****什么是Hbase****
Hbase是一种基于HDFS的分布式数据库
支持海量的数据的存储,千亿、万亿级别
表存储比较稀疏,Schema十分灵活
支持数据的多版本
列式存储
主键索引,低延迟的随机查询
扩展性与生俱来
HBase的基本概念和架构:
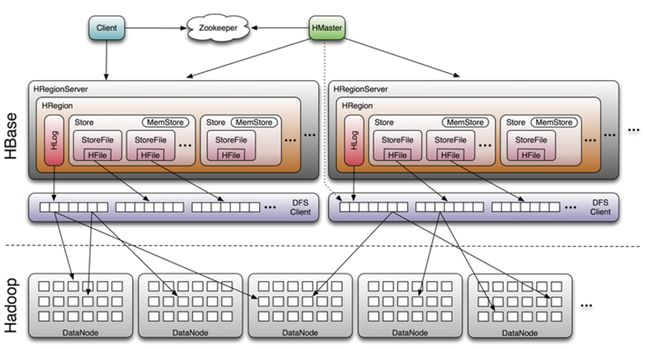
HMaster:Hbase的管理协调进程,用于Schema的管理,管理对Table的增、删、改、查操作,调整Region的分布,Region进行分裂的时候负责新的Region的分配。
RegionServer:Hbase的数据节点进程,主要是负责响应用户的I/O请求。
Zookeeper在这里主要起命名和通知的功能,Zk主要负责多HMaster的选举,存贮部分元数据、实时监控RegionServer,宕机之后迅速进行Region的转移、保证集群中只有一个HMaster。
数据存储:
HRegion 是RegionServer内部维护的一个对象,是一个Table的一个子集,一个Region和一个表一一对。
HLOG是Hbase的WAL(Write-Ahead Logging)机制的一个实现,通过预写日志,来避免节点宕机带来的数据丢失的问题,当写入HLOG成功,此时此节点宕机,HMaster控制Region转移到其他节点后,在Region上线的过程中会将HLOG上的数据重新写入,保证可靠性。
MemStore:数据写入时先进行MemStore的写入,当MemStore写满之后进行Flush,将数据FLush成一个HRegion。这样就保证了高吞吐,同时数据写入内存后,请求即返回,响应速度十分快。
Store是Region的子集,一个Store对应着Hbase的一个列族,所以Hbase的列族是分开存储的,通常将经常放在一个查询的数据放在一个列族中,同时官方不建议用多列族,原因是会导致数据不均匀的问题。
StoreFile对应着Hbase的底层存储—HFile,HFile是Hbase的底层存储,所有数据以固定的数据格式存储在HDFS的特定目录下,会定期的Split和Compact。
Table的层级和在HDFS上的存储:
表在HDFS上的存储

表的层级关系:

表结构:
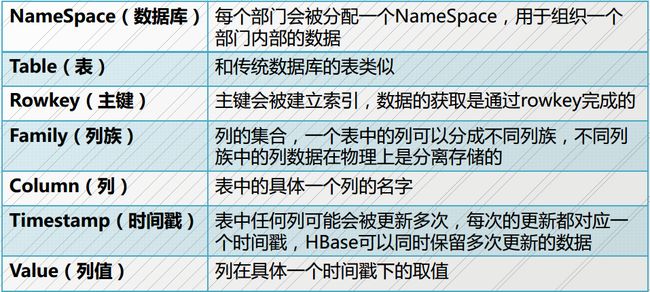
逻辑视图:
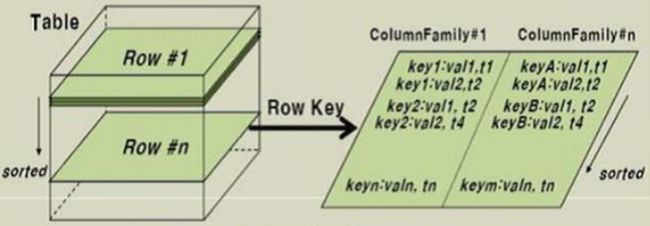
Hfile里是怎么存储的:

数据膨胀:
从上面的图我们可以看见,数据的基本格式为:rowkey:timestamp:columm_family:coloum:value.
逻辑上的一行数据被拆成了两行数据进行存储,同时存储的数据大大的膨胀了主要是冗余了rowkey timestamp 和coloumFamily字段,通常数据会膨胀2倍以上,具体大小视具体的数据。
更小的单元
Cell
Cell的概念是在Hbase0.96之后出现的,用来表征一行数据,Cell的前身是KeyValue,Cell的格式如下:
{row, column, version}
Version:

Version使用来标识数据版本的概念,Hbase支持多版本的机制,同一份数据具有多个版本,这样可以追踪到一条数据的上一个版本的信息,Hbase中的Cell是按照Version倒序排列的,所以第一个读取到的一定是最新版本的数据。
Hbase 默认的版本数为1,过量的Version数据将在Compact的过程中被删除,官方的建议是Version最大数最好不要超过100,因为这样会很大程度上消耗存储空间。
TTL( Time To Live)
TTL是一个标识一个数据的生命周期,对一个列族设定TTL之后,在到达TTL的时间时,数据会自动删除,尽管设置了Version,到达了TTL之后数据仍然会被删除:

Hbase的存储模型:
LSM思想:
LSM的基本思想是将修改的数据保存在内存,达到一定数量后在将修改的数据批量写入磁盘,在写入的过程中与之前已经存在的数据做合并。同B树存储模型一样,LSM存储模型也支持增、删、读、改以及顺序扫描操作。LSM模型利用批量写入解决了随机写入的问题,虽然牺牲了部分读的性能,但是大大提高了写的性能.
因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
MemStore的Flush过程:
在Hbase的写入过程中,首先追加到HLOG上,来保证数据的可靠性,随后append到MemStore上,当MemStore写满了之后会进行Flush过程,Flush过程中Hbase会开启一个新的MemStore接收新的写入,Flush会产生一个新的HFile到HDFS上,当Hfile数量和大小达到一定程度时,已经大大的影响到了查询性能,随后会进行Compact操作。
Compact过程:
随着MemStore的不断Flush,在HDFS上会形成越来越多的小文件,文件数量过多会大大的降低查询效率,Compact过程会尽可能的将它们合并成规模更少但是更大的文件
合并过程又分为minor compact和major的compact。
minor compact:主要是将小于一定阈值的文件合并成更大的文件。
major compact:主要是将所有的文件都合并成一个文件。
文件合并之后会大大的提高查询效率,但是由于合并过程中会读取全量的数据,这样会大量的占用磁盘的IO,导致查询效率大幅下降,甚至不可用。
Split过程:
当一个Region的大小达到一定程度的时候,会进行Region的Split过程,Split过程中Region会进行下线操作,此时不响应任何请求,直到Split过程结束。多列族且数据不均匀的情况会导致,大列族触发了Split,尽管小列族的数据很小,但是依然会进行split导致数据不均,同时大列族的flush会带动小列族的flush,导致反复的IO,十分影响效率,久而久之会严重的影响Scan查询效率。
Hbase对查询的优化:
Server端缓存——BlockCache
一个Hbase的查询请求首先会先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,BlockCache采用LRU机制,这样相当于对常用数据进行缓存,提高查询效率,但是在进行Scan的时候尽量避免使用cache,因为这样会大大的降低查询效率,例如MapReduce在做全表Scan的时候一定要关闭cache。
多File的选择——Bloom Filter
Hbase在HDFS上存储可能会有多个文件,在没有合并的情况下,各个File之间Rowkey索引可能互有交集,查询时最坏情况下要遍历全部文件,这样就大大的降低了查询效率,Hbase提供了Bloom Filter来实现快速的定位目标记录所在的文件。
Bloom Filter可以保守的确定一条数据在不在一个集合中,如果Bloom Filter认为一条数据在一个文件中,但事实上不一定在。但是Bloom Filter认为不在那么该数据一定不在。
Bloom Filter的原理使用一个十分大的二进制数组将File中的所有数据进行多种Hash算法hash到这个二进制数组上。当查询到来时,对查询进行同样的Hash处理,该结果在该File中,那么就判断该数据在这个集合中,但是由于Hash冲突的存在,这种判断的正确性不能100%保证,但是也能帮我们挡住大量的请求了。
MapReduce对Hbase的支持:
Hbase是Hadoop生态系统中很重要的一员,所以Hbase和MapReduce的契合度十分高,Mapreduce为Hbase提供了抽象度很高的Api,能快速的对Hbase中的数据进行计算。
Mapredece中提供了TableMapReduceUtil来支持读取和写入Hbase两种场景:

在Map函数中继承下TableMapper:

实现Reduce函数:

此处有坑! 在Hbase作为Mapreduce为输入的时候,Scan需要关闭blockCache 否则容易拖垮集群。
虽然这种是比较常用的mapreduce方式,但是,它的性能十分不好,数据吞吐量比较大的时候会给Hbase造成十分大的负载。
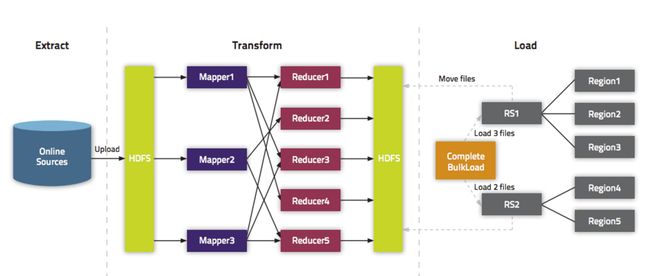
另一种加载机制:BulkLoad和HFileInputFormat
为了避免大量数据批量涌入造成Hbase Region进行频繁的compact和Split 造成短暂性不可用的问题。 Hbase提供了一种批量写入到Hbase底层存储的机制——bulkLoad。
bulkLoad是通过直接写底层Hbase存储的机制避开了整个Hbase的写入流程,从而避免Region的Compact和Split。
为什么选择bulkLoad:

处理流程:

流程图
应用场景:

对于直接读取Hbase底层Hfile,官方没有提供方法,不过可以通过自定义HfileInputFormat实现,但是这里面存在的问题是,对于还在内存中的数据通过这种方式查询不到(不知道现在有没有解决)。
“诟病”——热点问题
在初次写入或者rowkey分布不均匀的情况下,容易导致集群负载不一致,查询和写入速度变慢。
rowkey被设计为顺序,或分布比较集中的情况。顺序的rowkey虽然能为scan带来比较高的性能,但是会在写入时带来写人热点的问题。
初次写入问题则是第一次写入时默认只有一个region,那么如果第一次有大量数据写入,会导致Region会很快的进行compact和Split,会短暂的导致数据不可用,进而阻塞写操作。
解决:合理设置rowkey(主要针对写入热点问题,同时实时写入数据):
对rowkey进行hash或MD5
翻转倒序
避免顺序时间或者时间戳
加盐(salting)

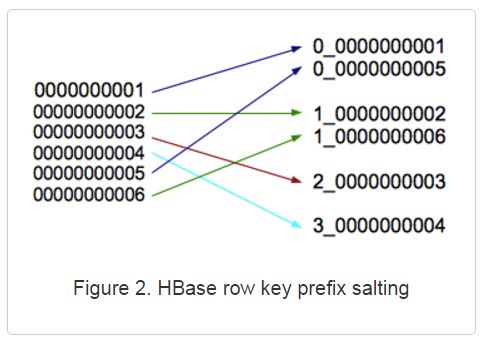

局限性:虽然做了salting 但是还是不能把数据准确的分到不同的region上
预分区:
预分区是在建表的时候根据预先设计的Rowkey,预先进行rowkey的划分。这样可以解决数据初始写入压力大的问题。

局限:随着数据量的增加,还是会产生,compact、split的,region短暂性下线的问题。
终极大招bulkload:
bulkload巧妙的避开了Hbase Api的写入,所以不会产生Compact和Split的问题。同mapreduce配合使用,系统吞吐量十分大。
局限:只能做离线的数据导入,不支持实时写入,一般场景为离线非实时的场景。
以上均为自己总结的,作为自己的备忘录,希望大家看到错误之处,帮忙指出,共同学习,谢谢。