信息是我们一直在谈论的东西,但信息这个概念本身依然比较抽象。但信息可不可以被量化,怎样量化?
答案当然是有的,那就是“信息熵”。早在1948年,香农(Shannon)在他著名的《通信的数学原理》论文中指出:“信息是用来消除随机不确定性的东西”,并提出了“信息熵”的概念(据说是冯诺依曼建议他借用了热力学中熵的概念),来解决信息的度量问题。
概率和“信息量”
首先我们可以简单地认为,一个事件发生的概率越小,“信息量”就越大(这里的信息量的定义非常不严谨,实际上不同于机器学习中信息量的概念,但便于理解先这样认为)。例如:“太阳从东边升起”,几乎是一件确定的事,包含的信息量很小;“2018中国队勇夺世界杯”则包含的信息量很大。当一件事确定会发生的话,则这件事的信息量为0,反之信息量则很大。
基于这种假设,我们可以认为,“信息量”的大小和概率负相关。
其次我们假设两个独立事件同时发生的概率:
![][equtation1]
[equtation1]: http://latex.codecogs.com/svg.latex?p(x,y)=p(x)*p(y)
两个事件分别发生的概率之积,但是同时发生的信息量则是两者信息量之和。从这个角度出发,我们可以认为:
![][equtation2]
[equtation2]: http://latex.codecogs.com/svg.latex?-ln(p(x,y))=-log(p(x))-log(p(y))
现在我们考虑随机事件X,假设存在这样的情况:
| X | 0 | 1 |
|---|---|---|
| P | 1-p | p |
| “信息量” | -log(1-p) | -log(p) |
那么我们如果要求“信息量”的期望的话:
![][equtation3]
[equtation3]: http://latex.codecogs.com/svg.latex?E(info)=-plog(p)-(1-p)log(1-p)=-\sum_{i=1}^{n}p_{i}logp_{i}
这样一来我们就导出了信息熵的定义:
![][equtation4]
[equtation4]: http://latex.codecogs.com/svg.latex?H(X)=-\sum_{i=1}^{n}p(x_{i})logp(x_{i})
而且对于一个二元信源(Bernoulli事件):
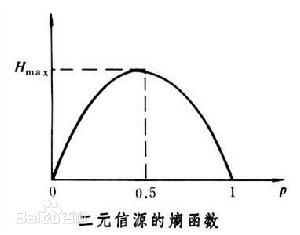
也就是说,一个事情“确定不发生”,和“确定发生”包含的“信息量”的期望都很小,而当发生的概率为0.5时,包含的“信息量”的期望最大。
对于离散型变量信息熵永远是非负数,它的单位为(bit);对于连续型变量,信息熵有可能是负数(在微分意义上),但这里我们暂不考虑。
联合熵 H(X,Y)
联合熵的概念很好理解,结合联合概率密度分布,有:
![][equtation7]
[equtation7]: http://latex.codecogs.com/svg.latex?H(X,Y)=-\sum_{j=1}{m}\sum_{i=1}{n}p(x_{i},y_{j})logp(x_{i},y_{j})
条件殇 H(Y|X)
首先我们定义:在X给定条件下,Y的平均不确定性。
设有随机变量(X,Y),其联合概率分布为:
![][equtation5]
[equtation5]: http://latex.codecogs.com/svg.latex?p(X=x_{i},Y=y_{j})=p_{ij}
对应条件概率公式:
![][equtation6]
[equtation6]: http://latex.codecogs.com/svg.latex?P(X|Y)=\frac{P(XY)}{P(Y)}
有链规则:
![][equtation9]
[equtation9]: http://latex.codecogs.com/svg.latex?H(Y|X)=H(X,Y)-H(X)
我们可以得到条件熵的定义:

根据定义我们可以得到:

举个例子:

设随机变量Y={嫁,不嫁},我们可以统计出,嫁的概率为6/12 = 1/2,那么Y的熵,根据熵的公式来算,可以得到H(Y) = -1/2log1/2 -1/2log1/2 = 0.69。
我们现在还有一个变量X,代表长相是帅还是帅,当长相是不帅的时候,统计如下红色所示:

可以得出,当已知不帅的条件下,满足条件的只有4个数据了,这四个数据中,不嫁的个数为1个,占1/4;嫁的个数为3个,占3/4。
那么此时的H(Y|X = 不帅) = -1/4log1/4-3/4log3/4 = 0.56
同理我们可以得到:H(Y|X = 帅) = -5/8log5/8-3/8log3/8 = 0.66
p(X = 帅) = 8/12 = 2/3
有了上面的铺垫之后,我们终于可以计算我们的条件熵了(其实我觉得挺奇怪的,这种写法非常类似于边缘条件概率):
H(Y|X=长相)= p(X =帅)*H(Y|X=帅)+ p(X =不帅)*H(Y|X=不帅) = 0.62
相对熵
相对熵又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度(即KL散度)等。设p(x)和q(x)是X的两个概率密度分布,则p对q的相对熵为:

在一定程度上,熵可以度量两个随机变量的距离。KL散度是两个概率分布P和Q差别的非对称性的度量。KL散度是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下, P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布,所以相对殇可以用来表征模型的损失函数。
相对熵的性质
- 尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即:
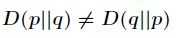
-
相对熵的值为非负值,即:

上述不等式可以通过吉布斯不等式(是不是Gibbs自由能那个吉布斯?)证明,这里就不再赘述了。
某些情形下,min(KL散度)作为目标函数,和最大似然估计MLE,是等价的,证明略。
相对熵的应用
相对熵可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零;当两个随机分布的差别增大时,它们的相对熵也会增大。所以相对熵(KL散度)可以用于比较文本的相似度,先统计出词的频率,然后计算KL散度就行了。另外,在多指标系统评估中,指标权重分配是一个重点和难点,通过相对熵可以处理。
互信息
定义:两个随机变量X,Y的互信息,就是X,Y的联合分布和独立分布乘积的相对熵。
![][equtation10]
[equtation10]: http://latex.codecogs.com/svg.latex?I(X,Y)=D(P(X,Y)||P(X)P(Y))
![][equtation11]
[equtation11]: http://latex.codecogs.com/svg.latex?I(X,Y)=\sum_{x,y}p(x,y)log\frac{p(x,y)}{p(x)p(y)}
不难发现如果X,Y完全独立,则互信息I(X,Y)为0,不独立,则大于零。
互信息的物理意义:
可以从另外一个维度定义条件熵
![][equtation12]
[equtation12]: http://latex.codecogs.com/svg.latex?H(Y|X)=H(X,Y)-H(X)
![][equtation13]
[equtation13]: http://latex.codecogs.com/svg.latex?H(Y|X)=H(Y)-I(X,Y)对偶式得到关于联合熵的定义
![][equtation14]
[equtation14]: http://latex.codecogs.com/svg.latex?H(Y|X)=H(X,Y)-H(X)
![][equtation15]
[equtation15]: http://latex.codecogs.com/svg.latex?H(Y|X)=H(X)-I(X,Y)
![][equtation16]
[equtation16]: http://latex.codecogs.com/svg.latex?I(X,Y)=H(X)+H(Y)-H(X,Y)说明一个问题:
H(X|Y) <= H(X), H(Y|X) <= H(Y):也即是说,对比X自身的不确定性,在给定Y的情况下X的不确定性只会减小,不会增大。-
一图胜千言
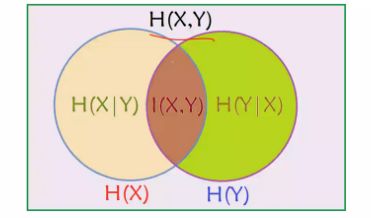
这一节的内容比较简单,主要围绕信息熵,很明显它可以构建分类器的目标函数或是损失函数,下一节我们将会具体介绍决策树的概念和几种实现方案。