注:
这部分代码是使用typora写的,里面嵌套的一些内容可能在里面显示不出来,所以如有格式问题,建议下载typora复制粘贴查看。
另:这些内容基本都是从网上各个网站找的资料,印象比较深刻的有以下几个:
https://blog.csdn.net/vally1989/article/details/71796482
http://leenjewel.github.io/blog/2015/11/11/%5B%28xue-xi-xv6%29%5D-nei-he-gai-lan/
http://leenjewel.github.io/blog/2015/05/26/%5B%28xue-xi-xv6%29%5D-jia-zai-bing-yun-xing-nei-he/
https://blog.csdn.net/qq_25426415/article/details/54583835
https://blog.csdn.net/qq_25426415/article/details/54619488
感谢上述各个文章。
如有需要,联系[email protected]
引导
BIOS需要执行系统的启动扇区上的东西,故首先需要将启动扇区复制到内存中,并且将其执行后进入操作系统的内核之中。
BIOS必须通过实模式启动,但当需要我们引入xv6自己的内核时,需要从实模式转换到保护模式(因为保护模式地址总线为32位,可访问地址位更多,可以利用4G内存)。
打开A20
A20简介:(来自https://en.wikipedia.org/wiki/A20_line)
- A20总线,是x86体系的扩充电子线路之一。A20总线是专门用来转换地址总线的第二十一位。
- 由于16位操作系统数据线宽与寄存器是16位,这样只能支持$2{16}$即64K的内存,为了扩展,在8086CPU上将地址线宽度增加到20位,这样能寻址到$2{20}$即1M(16位+4位的偏移)。一个 16 位的寄存器来表示“段基址”(CS、DS、SS、ES四个寄存器),具体的做法是先将 16 位的“段基址”左移 4 位,然后加上 16 位的“偏移量”最终得到 20 位的内存地址送入地址线。
- 但是到了80286CPU时已经有了24根总线,为了能够访问1M之后的内容并且与之前的8086/8088兼容,故使用键盘控制器上剩余的一些输出线来管理A20,被称为A20 Gate,若A20 Gate被打开,则0x100000-0x10FFEF的内存就可以正常访问。否则,就将超过1M的内存取模再次回到了1M以内。
- 保护模式有32位,肯定不能关闭A20,无法访问4G地址空间。只能访问1M,3M,5M等。
BIOS设置CS寄存器为0x0,ip寄存器为0x7c00,开始执行boot loader程序。
在bootasm.S中:
.code16
一句说明现在是16位状态。之后一句:
.globl start
.globl指示告诉汇编器,start这个符号要被链接器用到,所以要在目标文件的符号表中标记它是一个全局符号。start就像C程序的main函数一样特殊,是整个程序的入口,链接器在链接时会查找目标文件中的start符号代表的地址,把它设置为整个程序的入口地址,所以每个汇编程序都要提供一个start符号并且用.globl声明。如果一个符号没有用.globl声明,就表示这个符号不会被链接器用到。
之后使用cli命令来禁用中断。
接下来四句:
xorw %ax,%ax # 使用异或操作,直接将%ax设0
movw %ax,%ds # -> Data Segment
movw %ax,%es # -> Extra Segment
movw %ax,%ss # -> Stack Segment
将寄存器DS, ES, SS全部设置为0。其中取值会用到 %cs,读写数据会用到%ds,读写栈会用到 %ss。
但是实模式刚运行完,很多遗留下的一些寄存器的值需要我们整理下,所以我们需要“将 %ax 置零,然后把这个零值拷贝到三个段寄存器中”。
接下来,打开A20开关:
seta20.1:
inb $0x64,%al # 等待键盘控制器不忙碌
testb $0x2,%al
jnz seta20.1
movb $0xd1,%al # 把0xd1写入0x64
outb %al,$0x64
seta20.2:
inb $0x64,%al # 等待键盘控制器不忙碌
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al # 把0xdf写入0x60
outb %al,$0x60
xv6打开A20采用的方法是键盘控制器法,通过输出命令到键盘控制器的IO接口,控制A20的开启与关闭。
与键盘控制器有关的IO接口是0x60和0x64。其中0x64起到一个状态控制的功能,0x60则是数据端口。首先需要检查键盘控制器是否忙碌,例如是否正有键盘输入等等。这个状态检查是通过读取0x64实现的。通过检查该状态数据的低第二个比特位是否为高,来判断是否忙碌。等到该比特位为低,就可以向0x64写命令了。
上述代码中
inb $0x64,%al
之中的inb代表读入数据,即将0x64地址上的数据放入%al。$代表常量。
testb $0x2,%al
之中的testb将两个操作数进行逻辑与运算,并根据运算结果设置相关的标志位。但两个操作数不会被改变。运算结果在设置过相关标记位后会被丢弃。这一句将0x2与%al中的内容求与,即得到了%al中内容的第二位,如果是高,则执行下一句
jnz seta20.1
也就是再次执行seta20.1,重新检测。否则,进行下面的操作
movb $0xd1,%al # 把0xd1写入0x64
outb %al,$0x64
使用%al作为中介,将0xd1写入0x64。该命令用于指示即将向键盘控制器的输出端口写一个字节的数据。
下面的一段含义类似,只是最后将0xdf写入0x60。该数据代表开启A20。
进入保护模式
GDT介绍:
内存地址是段地址+段内偏移。在实模式下,段地址就放在段寄存器中,而到了保护模式下,段寄存器中保存的不再是段地址,而是GDT(global descriptor table,全局描述符表)中的偏移量,所以进入保护模式时首先需要创建GDT。
GDT每个段对应一个表项,保存段基址、段大小、访问权限等,让CPU可以定位到具体的物理地址去,并且检查内存访问是否合法,因此被叫做保护模式。GDT整体储存很多段描述符,故类似一个数组。
-
每个“段描述符”占 8 字节,如图:
 1
1
三段基地址组合形成32位的基地址(8+8+16)
P: 0 本段不在内存中
DPL: 访问该段内存所需权限等级 00 — 11,0为最大权限级别
S: 1 代表数据段、代码段或堆栈段,0 代表系统段如中断门或调用门
E: 1 代表代码段,可执行标记,0 代表数据段
ED: 0 代表忽略特权级,1 代表遵守特权级
RW: 如果是数据段(E=0)则1 代表可写入,0 代表只读;
如果是代码段(E=1)则1 代表可读取,0 代表不可读取A: 1 表示该段内存访问过,0 表示没有被访问过
G: 1 表示 20 位段界限单位是 4KB,最大长度 4GB;
0 表示 20 位段界限单位是 1 字节,最大长度 1MBDB: 1 表示地址和操作数是 32 位,0 表示地址和操作数是 16 位
XX: 保留位永远是 0
AA: 给系统提供的保留位
规定GDT的第一个表项必须是空的。
CPU 单独为我们准备了一个寄存器叫做 GDTR 用来保存我们 GDT 在内存中的位置和我们 GDT 的长度。GDTR 寄存器一共 48 位,其中高 32 位用来存储我们的 GDT 在内存中的位置,其余的低 16 位用来存我们的 GDT 有多少个段描述符。 16 位最大可以表示 65536 个数,这里我们把单位换成字节,而一个段描述符是 8 字节,所以 GDT 最多可以有 8192 个段描述符。不仅 CPU 用了一个单独的寄存器 GDTR 来存储我们的 GDT,而且还专门提供了一个指令用来让我们把 GDT 的地址和长度传给 GDTR 寄存器。lgdt代表加载全局描述符。
# 将实模式转换为保护模式,使用一个引导GDT让虚拟地址直接映射到真实地址去,过渡期内这个GDT的内存映射不会改变。
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
其中
lgdt gdtdesc
之中用到的gdtdesc的定义如下:
gdtdesc:
.word (gdtdesc - gdt - 1) # sizeof(gdt) - 1, 16位
.long gdt # address gdt,32位
加起来48位。
其中gdt定义如下:
# Bootstrap GDT
.p2align 2 # 强制进行4比特对齐
gdt:
SEG_NULLASM # 空
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # 代码段
SEG_ASM(STA_W, 0x0, 0xffffffff) # 数据(堆栈)段
宏定义在asm.h中,将他们再替换回来,得到如下:
gdt:
.word 0, 0;
.byte 0, 0, 0, 0 # 空
.word 0xffff, 0x0000;
.byte 0x00, 0x9a, 0xcf, 0x00 # 代码段
.word 0xffff, 0x0000;
.byte 0x00, 0x92, 0xcf, 0x00 # 数据段
代码段空间如下:
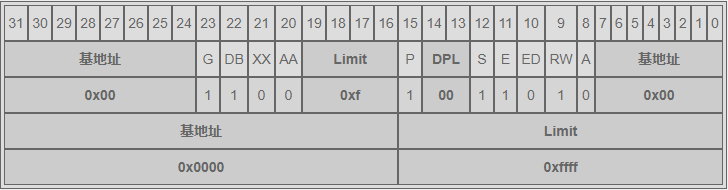
数据段空间如下:
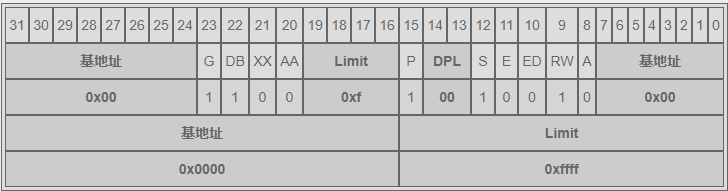
首先说说这两个内存段的共同点,DB = 1,G = 1,基地址都是 0x00000000,内存分段长度都是 0xfffff,这说明他们都是用于 32 位寻址,所使用的内存是从 0 开始到 4GB 结束(全部内存)。这里是这么算出来的,段长度是 0xfffff = $2^{20}$,G = 1 表示段界限单位是 4k,所以 4k * $2^{20}$ = 4GB。
再说说他们的不同点,代码段的 E = 1 而数据段的 E = 0 这表明了他们的身份,身份不同 RW 的值虽然相同,但代表的意义也就不相同了,代码段的 RW = 1 代表可读取,数据段的 RW = 1 表示可读可写。这也和我们上面解释的保护模式所能够达到的目的相吻合。
代码段和数据段都启用了从 0 到 4GB 的全部内存寻址。其实这种内存规划方法叫做“平坦内存模型”,即便是 Linux 也是用的这样的方式规划内存的,并没有做到真正的“分段”。这是因为 x86 的分页机制是基于分段的,Linux 选用了更先进的分页机制来管理内存,所以在分段这里只是走一个必要的形式罢了。
后面的几句:
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
因为我们无法直接操作 cr0,所以我们首先要用一个通用寄存器来保存当前 cr0 寄存器的值,这里第一行就是用通用寄存器 eax 来保存 cr0 寄存器的值;然后 CR0_PE 这个宏的定义在 mmu.h 文件中,是个数值 0x00000001,将这个数值与 eax 中的 cr0 寄存器的值做“或”运算后,就保证将 cr0 的第 0 位设置成了 1 即 PE = 1 保证打开了保护模式的开关。而 cr0 的第 31 位 PG = 0 表示我们只使用分段式,不使用分页,这时再将新的计算后的 eax 寄存器中的值写回到 cr0 寄存器中就完成了到保护模式的切换。
之后进入32位:
ljmp $(SEG_KCODE<<3), $start32
ljmp的语法:ljmp segment offset,它会同时设置段寄存器和段内偏移(EIP寄存器),而在32位模式下,段寄存器保存的是GDT里的偏移量,所以这里段寄存器的值是SEG_KCODE<<3,即数字8(SEG_KCODE=1),因为GDT的第一个表项必须为空,所以代码段占据第二个表项。
这个跳转语句的两个参数就是“基地址” + “偏移量”的方式告诉 CPU 要跳转到内存的什么位置去继续执行指令。
进入32位模式之后,设置各个段寄存器。
.code32 # 现在是32位
start32:
# 设置保护模式下的一堆寄存器的值
# 这时候已经在保护模式下了
# 数据段在 GDT 中的下标是 2,所以这里数据段的段选择子是 2 << 3 = 0000 0000 0001 0000
# 这 16 位的段选择子中的前 13 位是 GDT 段表下标,这里前 13 位的值是 2 代表选择了数据段
# 这里将 3 个数据段寄存器都赋值成数据段段选择子的值
movw $(SEG_KDATA<<3), %ax # 先借助中介设置DS,ES,SS这些作为数据项的值为(SEG_KDATA<<3)
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %ss # -> SS: Stack Segment
movw $0, %ax # 剩下的寄存器设置为0
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
上述代码中,数据段占用GDT第三个表项,ES, SS等同于数据段,其他不用的段置零。
# Set up the stack pointer and call into C.
movl $start, %esp # 栈顶被放置在 0x7C00 处,即 $start
call bootmain
现在准备执行.c代码,首先要设置stack,movl $start, %esp,即给esp寄存器设置,start为bootasm.S最开始的一个label,但是为何要将esp设置为start呢,这是因为start是代码的开始位置,代码是向高内存地址处放置的,而stack是向低内存地址增长的,所以这样设置之后,代码和栈向相反方向扩张,两者互不干涉。BIOS 会将引导扇区的引导程序加载到 0x7C00 处并引导 CPU 从此处开始运行,故栈顶即被设置在了和引导程序一致的内存位置上。我们知道栈是自栈顶开始向下增长的,所以这里栈会逐渐远离引导程序,所以这里这样安置栈顶的位置并无什么问题。另外,当call bootmain的时候,首先要做的就是movl %esp %ebp,即将esp的值设置给ebp,这样ebp保存的就是start的值,也就是函数栈中的第一个函数是start,这符合逻辑。
现在不应该执行接下来的这些语句,但是如果异常的话,bootmain返回并且执行下面的操作:
# If bootmain returns (it shouldn't), trigger a Bochs
# breakpoint if running under Bochs, then loop.
movw $0x8a00, %ax # 0x8a00 -> port 0x8a00
movw %ax, %dx
outw %ax, %dx
movw $0x8ae0, %ax # 0x8ae0 -> port 0x8a00
outw %ax, %dx
spin:
jmp spin
进入.c的内容
由于之前曾经使用了call bootmain,所以现在会执行bootmain.c里面的bootmain()函数,该函数如下所示:
#define SECTSIZE 512 // 表示磁盘扇区大小(字节数)
void bootmain(void)
{
struct elfhdr *elf;
struct proghdr *ph, *eph;
void (*entry)(void);
uchar* pa;
elf = (struct elfhdr*)0x10000; // 表示内核开始的地址空间位置
// 读取一个页的数据(4k)到内存中elf对应的位置
readseg((uchar*)elf, 4096, 0);
// 判断是否是一个正确的elf格式可执行文件
if(elf->magic != ELF_MAGIC)
return; // 现在返回会回到上面所说的错误处理部分
// 加载每一个程序段(忽略ph标记)
// 找到内核 ELF 文件的程序头表
ph = (struct proghdr*)((uchar*)elf + elf->phoff);
// 内核 ELF 文件程序头表的结束位置
eph = ph + elf->phnum;
// 开始将内核 ELF 文件程序头表载入内存
for(; ph < eph; ph++){
pa = (uchar*)ph->paddr;
readseg(pa, ph->filesz, ph->off);
// 如果内存大小大于文件大小,用 0 补齐内存空位
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz);
}
// 调用elf头所规定的起始位置
// 不会返回
entry = (void(*)(void))(elf->entry);
entry();
}
上述过程其实只是加载了内核(把内核从磁盘上搬到了内存中),然后执行内核中的程序。其中反复被用到的readseg()函数的定义如下所示:
// 将'count'字节的位于距离内核'offset'的代码写入内存地址'pa'中
// 可能会比要求的多拷贝一部分
void
readseg(uchar* pa, uint count, uint offset)
{
// 表示最后的边界
uchar* epa;
// 从开始写入,最后写入的位置要小于epa
epa = pa + count;
// 多出来的忽略掉(因为磁盘扇区大小)
pa -= offset % SECTSIZE;
// 将内容翻译到扇区(sector)中,内核从下标为1处开始(因为引导区已经占了第一个即下标为0的位置)
offset = (offset / SECTSIZE) + 1;
// 如果比较慢就每次多读一些扇区的东西
// (因为每次都是读一个扇区)将多读一部分,但是没关系,因为我们按照升序加载
for(; pa < epa; pa += SECTSIZE, offset++)
readsect(pa, offset);
}
要知道内核二进制文件到底是如何链接的,首先需要了解:
-
ld表示GCC连接脚本,链接的过程实际上是为了解决多个文件之间符号引用的问题(symbol resolution)。编译时编译器只对单个文件进行处理,如果该文件里面需要引用到其他文件中的符号(例如全局变量或者函数),那么这时在这个文件中该符号的地址是没法确定的,只能等链接器把所有的目标文件连接到一起的时候才能确定最终的地址。
打开kernel.ld文件,可以发现,内核入口地址为标号_start地址
OUTPUT_FORMAT("elf32-i386", "elf32-i386", "elf32-i386")
OUTPUT_ARCH(i386)
ENTRY(_start)
这个_start的地址其实是在内核代码文件entry.S是内核入口虚拟地址entry对应的物理地址,由于此时虚拟地址直接等于物理地址,_start将作为ELF文件头中的elf->entry的值。
内核文件中加载地址和链接地址是不一样的,链接地址是程序中所有标号、各种符号的地址,一般也就是内存中的虚拟地址,但是加载地址是为了在生成ELF文件时,指定各个段应该为加载的物理地址,这个地址作为每个段的p->paddr的值。
上面readseg函数之中的readsect函数定义如下:
// 从offset位置读取单个扇区到dst
void
readsect(void *dst, uint offset)
{
waitdisk();
outb(0x1F2, 1); // count = 1
outb(0x1F3, offset);
outb(0x1F4, offset >> 8);
outb(0x1F5, offset >> 16);
outb(0x1F6, (offset >> 24) | 0xE0);
outb(0x1F7, 0x20); // 命令0x20也就是读取扇区的命令
// 读取数据
waitdisk();
insl(0x1F0, dst, SECTSIZE/4);
}
里面一堆神奇(莫名其妙)的outb函数就是一个写入一比特的数据(一个uchar)。这样设置的原因如下:
-
IDE 标准定义了 8 个寄存器来操作硬盘。PC 体系结构将第一个硬盘控制器映射到端口 1F0-1F7 处,而第二个硬盘控制器则被映射到端口 170-177 处。这几个寄存器的描述如下(以第一个控制器为例):
1F0 - 数据寄存器。读写数据都必须通过这个寄存器 1F1 - 错误寄存器,每一位代表一类错误。全零表示操作成功。 1F2 - 扇区计数。这里面存放你要操作的扇区数量 1F3 - 扇区LBA地址的0-7位 1F4 - 扇区LBA地址的8-15位 1F5 - 扇区LBA地址的16-23位 1F6 (低4位) - 扇区LBA地址的24-27位 1F6 (第4位) - 0表示选择主盘,1表示选择从盘 1F6 (5-7位) - 必须为1 1F7 (写) - 命令寄存器 1F7 (读) - 状态寄存器 bit 7 = 1 控制器忙 bit 6 = 1 驱动器就绪 bit 5 = 1 设备错误 bit 4 N/A bit 3 = 1 扇区缓冲区错误 bit 2 = 1 磁盘已被读校验 bit 1 N/A bit 0 = 1 上一次命令执行失败上面代码中已经把这些内容翻译到注释里面去了。
xv6内核二进制文件是elf格式,在维基上有这个格式的具体说明。前两部分是ELF头部和程序头表,在elf.h文件里面有具体的声明,如下所示:
#define ELF_MAGIC 0x464C457FU // "\x7FELF" in little endian
// ELF 文件格式的头部
struct elfhdr {
uint magic; // 4 字节,为 0x464C457FU(大端模式)或 0x7felf(小端模式)
// 表明该文件是个 ELF 格式文件
uchar elf[12]; // 12 字节,每字节对应意义如下:
// 0 : 1 = 32 位程序;2 = 64 位程序
// 1 : 数据编码方式,0 = 无效;1 = 小端模式;2 = 大端模式
// 2 : 只是版本,固定为 0x1
// 3 : 目标操作系统架构
// 4 : 目标操作系统版本
// 5 ~ 11 : 固定为 0
ushort type; // 2 字节,表明该文件类型,意义如下:
// 0x0 : 未知目标文件格式
// 0x1 : 可重定位文件
// 0x2 : 可执行文件
// 0x3 : 共享目标文件
// 0x4 : 转储文件
// 0xff00 : 特定处理器文件
// 0xffff : 特定处理器文件
ushort machine; // 2 字节,表明运行该程序需要的计算机体系架构,
// 这里我们只需要知道 0x0 为未指定;0x3 为 x86 架构
uint version; // 4 字节,表示该文件的版本号
uint entry; // 4 字节,该文件的入口地址,没有入口(非可执行文件)则为 0
uint phoff; // 4 字节,表示该文件的“程序头部表”相对于文件的位置,单位是字节
uint shoff; // 4 字节,表示该文件的“节区头部表”相对于文件的位置,单位是字节
uint flags; // 4 字节,特定处理器标志
ushort ehsize; // 2 字节,ELF文件头部的大小,单位是字节
ushort phentsize; // 2 字节,表示程序头部表中一个入口的大小,单位是字节
ushort phnum; // 2 字节,表示程序头部表的入口个数,
// phnum * phentsize = 程序头部表大小(单位是字节)
ushort shentsize; // 2 字节,节区头部表入口大小,单位是字节
ushort shnum; // 2 字节,节区头部表入口个数,
// shnum * shentsize = 节区头部表大小(单位是字节)
ushort shstrndx; // 2 字节,表示字符表相关入口的节区头部表索引
};
// 程序头表
struct proghdr {
uint type; // 4 字节, 段类型
// 1 PT_LOAD : 可载入的段
// 2 PT_DYNAMIC : 动态链接信息
// 3 PT_INTERP : 指定要作为解释程序调用的以空字符结尾的路径名的位置和大小
// 4 PT_NOTE : 指定辅助信息的位置和大小
// 5 PT_SHLIB : 保留类型,但具有未指定的语义
// 6 PT_PHDR : 指定程序头表在文件及程序内存映像中的位置和大小
// 7 PT_TLS : 指定线程局部存储模板
uint off; // 4 字节, 段的第一个字节在文件中的偏移
uint vaddr; // 4 字节, 段的第一个字节在内存中的虚拟地址
uint paddr; // 4 字节, 段的第一个字节在内存中的物理地址(适用于物理内存定位型的系统)
uint filesz; // 4 字节, 段在文件中的长度
uint memsz; // 4 字节, 段在内存中的长度
uint flags; // 4 字节, 段标志
// 1 : 可执行
// 2 : 可写入
// 4 : 可读取
uint align; // 4 字节, 段在文件及内存中如何对齐
};
现在打开xv6.img文件,读取第二个扇区位置(第一个扇区即第一个512字节是bootblock)的开头数据并且与上面内容相对应,得到如下结果:
| 字段名称 | 大小 | 数值 | 意义 |
|---|---|---|---|
| magic | 4字节 | 7F 45 4C 46 | ELF 格式文件 |
| elf | 12字节 | 01 01 01 00 00 00 00 00 00 00 00 00 | 32 位小端模式,目标操作系统为 System V |
| type | 2字节 | 02 00 | 可执行文件 |
| machine | 2字节 | 03 00 | 指定计算机体系架构为 x86 |
| version | 4字节 | 01 00 00 00 | 版本号为 1 |
| entry | 4字节 | 0C 00 10 00 | 该可执行文件入口地址 |
| phoff | 4字节 | 34 00 00 00 | 程序头表相对于文件的起始位置是 52 字节 |
| shoff | 4字节 | 00 F6 01 00 | 节区头表相对于文件的起始位置是 128512 字节 |
| flags | 4字节 | 00 00 00 00 | 无特定处理器标志 |
| ehsize | 2字节 | 34 00 | ELF 头大小为 52 字节 |
| phentsize | 2字节 | 20 00 | 程序头表一个入口的大小是 32 字节 |
| phnum | 2字节 | 02 00 | 程序头表入口个数是 2 个 |
| shentsize | 2字节 | 28 00 | 节区头表入口大小是 40 字节 |
| shnum | 2字节 | 12 00 | 节区头表入口个数是 18 个 |
| shstrndx | 2字节 | 0F 00 | 字符表入口在节区头表的索引是 15 |
之后是程序头表,一共两个,每个32字节,如下:
- 程序头表 1
| 字段名称 | 大小 | 数值 | 意义 |
|---|---|---|---|
| type | 4字节 | 01 00 00 00 | 可载入的段 |
| off | 4字节 | 00 10 00 00 | 段在文件中的偏移是 4096 字节 |
| vaddr | 4字节 | 00 00 10 80 | 段在内存中的虚拟地址 |
| paddr | 4字节 | 00 10 00 00 | 同段在文件中的偏移量 |
| filesz | 4字节 | 96 B5 00 00 | 段在文件中的大小是 46486 字节 |
| memsz | 4字节 | FC 26 01 00 | 段在内存中的大小是 75516 字节 |
| flags | 4字节 | 07 00 00 00 | 段的权限是可写、可读、可执行 |
| align | 4字节 | 00 10 00 00 | 段的对齐方式是 4096 字节,即4kb |
- 程序头表 2
| 字段名称 | 大小 | 数值 | 意义 |
|---|---|---|---|
| type | 4字节 | 51 E5 74 64 | PT_GNU_STACK 段 |
| off | 4字节 | 00 00 00 00 | 段在文件中的偏移是 0 字节 |
| vaddr | 4字节 | 00 00 00 00 | 段在内存中的虚拟地址 |
| paddr | 4字节 | 00 00 00 00 | 同段在文件中的偏移量 |
| filesz | 4字节 | 00 00 00 00 | 段在文件中的大小是 0 字节 |
| memsz | 4字节 | 00 00 00 00 | 段在内存中的大小是 0 字节 |
| flags | 4字节 | 07 00 00 00 | 段的权限是可写、可读、可执行 |
| align | 4字节 | 04 00 00 00 | 段的对齐方式是 4 字节 |
因此只有第一个程序头表是需要加载的。这个程序头表指出的加载位置 0x80100000 和内核程序的代码段 .text 的位置是一样的。
而要加载的段是 .text .rodata .stab .stabstr .data .bss ,这些段在内存中的大小总和是0x008111 + 0x000672 + 0x000001 + 0x000001 + 0x002596 + 0x00715c = 73335 即 0x11e77 按照对齐要求 0x1000 对齐后为 75516 即 0x000126fc(注意大小端转换,FC 26 01 00 是按照小端排列的,转换成正常的十六进制数为 0x000126fc)和 ELF 程序头表中的内存大小信息一致。
我们再算算这些段在文件中的大小,由于这些段在文件中是顺序排列的,所以用 .bss段 的文件偏移量减去 .text段 的文件偏移量 0x00c596 - 0x001000 = 46486 这也是和 ELF 程序头表中段在文件中大小的信息一致。
进入内核
在kernel.ld文件中,找到:
ENTRY(_start) # 内核的代码为段执行入口:_start
. = 0x80100000 # 内核的起始虚拟地址位置为:0x80100000
.text : AT(0x100000) # 内核代码段的内存装载地址为:0x100000
. = ALIGN(0x1000) # 内核代码段保证 4KB 对齐
因此就可以让系统正确加载内核。
上面提到的_start在entry.S这个汇编文件里面。
# 多系统加载头。运行多系统加载程序的部分。
.p2align 2
.text
.globl multiboot_header
multiboot_header:
#define magic 0x1badb002
#define flags 0
.long magic
.long flags
.long (-magic-flags)
# 按照约定,_start符号指出入口。因为我们还没有设置虚拟内存,因此我们的起始点是'entry'的物理地址
.globl _start
_start = V2P_WO(entry)
multiboot_header 这部分是为了方便通过GNU GRUB来引导 xv6 系统的。而V2P_WO 的定义在 memlayout.h 文件中:
#define V2P_WO(x) ((x) - KERNBASE) // V2P里面将x转换成了uint,这里没有转换。
// 这个名字其实就是 Virtual to Physical WITHOUT
它的作用是将内存虚拟地址转换成物理地址。里面KERNBASE定义为:
#define KERNBASE 0x80000000 // First kernel virtual address
entry部分如下所示:
# 进入xv6的启动程序,这时候还没有开启分页
.globl entry
entry:
# 打开4M页面大小扩展
movl %cr4, %eax # 把cr4寄存器拿出来,与CR4_PSE取或来设置这一位为1以打开4M
orl $(CR4_PSE), %eax
movl %eax, %cr4
# 设置内存页表
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
# 打开分页
movl %cr0, %eax
orl $(CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# 设置栈指针
movl $(stack + KSTACKSIZE), %esp
# 跳转到main()函数,并且转移到高地址执行。
# 因为汇编程序产生了一个及其相关的直接跳转的指令,所以需要进行间接的调用。
mov $main, %eax
jmp *%eax
.comm stack, KSTACKSIZE
开启 4MB 内存分页支持
这是通过设置寄存器 cr4 的 PSE 位来完成的。cr4 寄存器是个 32 位的寄存器目前只用到低 21 位,每一位的至位都控制这一些功能的状态,所以 cr4 寄存器又叫做控制寄存器。
PSE 位是 cr4 控制寄存器的第 5 位,当该位置为 1 时表示内存页大小为 4MB,当置为 0 时表示内存页大小为 4KB。
建立内存页表
和分段机制一样,分页机制同样是管理内存的一种方式,只不过这种方式相对于分段式来说更为先进,也是目前主流的现代操作系统所使用的内存管理方式。
通过分页将虚拟地址转换为物理地址这项工作是由 MMU(内存管理单元)负责的,以 x86 32 位架构来说它支持两级分页(Pentium Pro下分页可以是三级),这也是由 MMU 决定的。同时 x86 架构支持 4KB、2MB 和 4MB 单位页面大小的分页。当然无论以多少级进行分页,分页机制的原理是相通的,我们就以两级分页来说。
以 32 位系统为例,其内存虚拟地址是 32 位的,这里我们先假设页面大小是 4KB ,此时 32 位的虚拟地址被分为三个部分,从高位到低位分别是:10 位的一级页表索引,10 位的二级页表索引,12 位的页内偏移量。
在 4KB 页面大小情况下 32 位的虚拟地址被分为三个部分,从高位到低位分别是:10 位的一级页表索引,10 位的二级页表索引,12 位的页内偏移量。
cr3 寄存器中保存着一级页表所在的内存物理地址,当给出一个虚拟地址后,根据 cr3 的地址首先找到一级页表在内存上的存放位置。上面我们说到虚拟地址的高 10 位为一级页表的索引,所以 2^10 = 1024 即一级页表一共有 1024 个元素,通过虚拟地址高 10 位的索引我们找到其中一个元素,而这个元素的值指向二级页表在内存中的物理地址。
同理,虚拟地址中紧挨着高 10 位后面的 10 位是二级页表索引,因此二级页表也有 1024 个元素,通过虚拟地址的二级页表索引找到其中的一个元素,该元素指向内存分页中的一个页的地址。
通过二级页表我们现在找到了内存上的一页物理页。根据现在的设定,一物理页的大小是 4KB,在虚拟地址上的低 12 位索引找到想要的数据(2^12 = 4096 = 4KB)。
而根据二级页表和每页内存的大小我们也不难算出:1024个一级页表项 x 1024个二级页表项 x 4KB页面大小 = 4GB,正好是 32 位系统的最大内存寻址。
这里我们再额外算一笔账,二级页表中每个表项占 32 位,所以一个一级页表的总体积是 4byte x 1024 = 4KB,而每个一级页表项都对应一个二级页表,所以全部二级页表的总体积是 4KB x 1024 = 4MB,即二级页表分页机制自身内存占用也要约 4MB 外加 4KB。
我们还要额外提一下页表项。上面刚说过每个页表项占 32 位,它也是分两个部分:高 20 位是基地址,低 12 位是控制标记位。所以当我们通过一级页表索引在一级页表中查找时是这样的:一级页表项地址 = cr3寄存器高20位 + ( 10位一级页表索引 << 2 );通过二级页表索引在二级页表中查找时是这样的:二级页表项地址 = 一级页表项高20位 + ( 10位二级页表索引 << 2 )。
- 注:页表项地址 = 基地址 + ( 索引 x 页表项大小 ) = 基地址 + ( 索引 x 4字节 ) = 基地址 + ( 索引 << 2 )
最后我们再看看页表项低 12 位控制位都代表什么意义:
+ 11 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 + 0 +
| Avail | G | PS | D | A | PCD | PWT | US | RW | P |
+--------------------------------------------------------+
| 000 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
+--------------------------------------------------------+
P : 0 表示此页不在物理内存中,1 表示此页在物理内存中
RW : 0 表示只读,1 表示可读可写(要配合 US 位)
US : 0 表示特权级页面,1 表示普通权限页面
PWT : 1 表示写这个页面时直接写入内存,0 表示先写到缓存中
PCD : 1 表示该页禁用缓存机制,0 表示启用缓存
A : 当该页被初始化时为 0,一但进行过读/写则置为 1
D : 脏页标记(这里就不做具体介绍了)
PS : 0 表示页面大小为 4KB,1 表示页面大小为 4MB
G : 1 表示页面为共享页面(这里就不做具体介绍了)
Avail : 3 位保留位
然后我们再说回 xv6。
到目前为止我们知道 xv6 开启了 4MB 内存页大小,在 x86 架构下当通过 cr4 控制寄存器的 PSE 位打开了 4MB 分页后 MMU 内存管理单元的分页机制就会从二级分页简化为一级分页。
即虚拟地址的高 10 位仍然是一级页表项索引,但是后面的 22 位则全部变为页内偏移量(因为一页有 2^22 = 4MB 大小)。
我们来看看这个一级页表的结构:
# Set page directory
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
通过代码我们知道页表地址是存在一个叫做 entrypgdir 的变量中了,通过文本搜索可以在 main.c 文件的最后找到这个变量,我们看一下:
// Boot page table used in entry.S and entryother.S.
// Page directories (and page tables), must start on a page boundary,
// hence the "__aligned__" attribute.
// Use PTE_PS in page directory entry to enable 4Mbyte pages.
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};
//PAGEBREAK!
// Blank page.
将这些宏定义都转义过来我们看看这个页表的样子:
unsigned int entrypgdir[1024] = {
[0] = 0 | 0x001 | 0x002 | 0x080, // 0x083 = 0000 1000 0011
[0x80000000 >> 22] = 0 | 0x001 | 0x002 | 0x080 // 0x083
};
可见这个页表非常简单,只有两个页表项 0x00000000 和 0x80000000,而且两个页表项索引的内存物理地址都是 0 ~ 4MB,其他页表项全部未作设置。而且通过这两个页表项的值也可以清楚的看出这段基地址为 0 的 4MB 大小的内存页还是特级权限内存页(低 12 位的控制位对应关系已经附在上面解释控制位的示意图里了)。它仅仅只是一个临时页表,它只保证内核在即将打开内存分页支持后内核可以正常执行接下来的代码,而内核在紧接着执行 main 方法时会马上再次重新分配新的页表,而且最终的页表是 4KB 单位页面的精细页表。
开启内存分页机制
将 cr0寄存器的第 31 位置为 1 就可以启动内存分页。
这里还要在提一句,至此我们开启了内存分页机制,接下来内核的代码执行和数据读写都要经过 MMU 通过分页机制对内核指令地址和数据地址的转换,那么目前的页表是如何保证在转换后的物理地址是正确的,如何保证内核可以继续正常运行的呢?
我们来分析一下。
根据 kernel.ld 链接器脚本的设定,内核的虚拟地址起始于 0x80100000 即内核代码段的起始处,而内核的代码段被放置在内存物理地址 0x100000 处。我们刚刚看到目前的临时页表将虚拟地址 0x80000000 映射到物理内存的 0x0 处,所以我们来尝试用刚刚了解到的内存分页机制来解析一下 0x80100000 虚拟地址最后转换成物理地址是多少。
0x80100000 = 1000 0000 00|01 0000 0000 0000 0000 0000
0x80100000 高 10 位 = 1000 0000 00 = 512
0x80100000 后 22 位 = 01 0000 0000 0000 0000 0000 = 1048576
索引 512 对应 entrypgdir[ 0x80000000 >> 22 ] 即基地址为 0x0
换算的物理地址 = 0 + 1048576 = 1048576 = 0x100000
即内核代码段所在内存物理地址 0x100000
说白了就是通过页表将内核高端的虚拟地址直接映射到内核真实所在的低端物理内存位置。
这样虽然保证了在分页机制开启的情况下内核也可以正常运行,但也限制了内核最多只能使用 4MB 的内存,不过对于现在的内核来说 4MB 足够了。
设置内核栈顶位置并跳转到 main 执行
这里通过 .comm 在内核 bbs 段开辟了一段 KSTACKSIZE = 4096 = 4KB 大小的内核栈并将栈顶设置为这段数据区域的末尾处(栈是自上而下的嘛),最后通过 jmp 语句跳转到 main 方法处继续执行。
其他内核的运行
另外一个启动xv6内核的代码是entryother.S,将每一个非引导CPU从16位切换至32位,然后进入mpenter()函数中,最终开始CPU协同调度。其中很大一部分都与bootloader.S相同。
具体工作在main()函数中被调用,因此在下一部分介绍。
进入main()函数
现在还需要将CPU的第二个核启动,这是在main()函数中调用的mpinit()函数负责。
mpinit()函数在mp.c文件中。具体定义如下:
void
mpinit(void)
{
uchar *p, *e;
struct mp *mp;
struct mpconf *conf;
struct mpproc *proc;
struct mpioapic *ioapic;
bcpu = &cpus[0];
if((conf = mpconfig(&mp)) == 0)
return;
ismp = 1;
lapic = (uint*)conf->lapicaddr;
for(p=(uchar*)(conf+1), e=(uchar*)conf+conf->length; papicid){
cprintf("mpinit: ncpu=%d apicid=%d\n", ncpu, proc->apicid);
ismp = 0;
}
if(proc->flags & MPBOOT)
bcpu = &cpus[ncpu];
cpus[ncpu].id = ncpu;
ncpu++;
p += sizeof(struct mpproc);
continue;
case MPIOAPIC:
ioapic = (struct mpioapic*)p;
ioapicid = ioapic->apicno;
p += sizeof(struct mpioapic);
continue;
case MPBUS:
case MPIOINTR:
case MPLINTR:
p += 8;
continue;
default:
cprintf("mpinit: unknown config type %x\n", *p);
ismp = 0;
}
}
if(!ismp){
// Didn't like what we found; fall back to no MP.
ncpu = 1;
lapic = 0;
ioapicid = 0;
return;
}
if(mp->imcrp){
// Bochs doesn't support IMCR, so this doesn't run on Bochs.
// But it would on real hardware.
outb(0x22, 0x70); // Select IMCR
outb(0x23, inb(0x23) | 1); // Mask external interrupts.
}
}
其中结构体cpu的定义如下(在proc.h中):
// 每个CPU的状态
struct cpu {
uchar id; // 本地 APIC(Advanced Programmable Interrupt Controller) ID, cpus[]数组的索引
struct context *scheduler; // 通过这里进入调用计划表
struct taskstate ts; // 寻找中断栈
struct segdesc gdt[NSEGS]; // 全局描述表
volatile uint started; // 记录启动与否
int ncli; // 终端层数
int intena; // 在pushcli之前有没有启用中断
// 本地的CPU存储变量
struct cpu *cpu;
struct proc *proc; // 正在运行的进程
};
并且定义:
extern struct cpu cpus[NCPU];
extern int ncpu;
extern struct cpu *cpu asm("%gs:0"); // &cpus[cpunum()]
extern struct proc *proc asm("%gs:4"); // cpus[cpunum()].proc
后面两句其实就是通过指针引用到当前的cpu,我觉得应该是相当于给这两个变量赋值?
因为每个CPU都有独立的gdt,所以在设置gdt的时候可以这样设置(见vm.c中的seginit()函数):
// CPU和进程的映射,对于每一个CPU都是私有的
c->gdt[SEG_KCPU] = SEG(STA_W, &c->cpu, 8, 0);
lgdt(c->gdt, sizeof(c->gdt));
loadgs(SEG_KCPU << 3);
通过提前设置gs寄存器和gdt的描述符,便能直接通过cpu和proc变量访问当前CPU的结构体和运行进程。
main()函数调用的mpinit()初始化了cpus结构体数组,并确定了lapic地址和ioapicid。
uchar ioapicid;
volatile uint *lapic; // Initialized in mp.c
volatile struct ioapic *ioapic; // ioapic在地址空间中有固定地址,这里写出来只是为了对比123
具体的初始过程如下:
lapic = (uint*)conf->lapicaddr;
for(p=(uchar*)(conf+1), e=(uchar*)conf+conf->length; papicid; // apicid may differ from ncpu
ncpu++;
}
p += sizeof(struct mpproc);
continue;
case MPIOAPIC:
ioapic = (struct mpioapic*)p;
ioapicid = ioapic->apicno;
p += sizeof(struct mpioapic);
continue;
case MPBUS:
case MPIOINTR:
case MPLINTR:
p += 8;
continue;
default:
ismp = 0;
break;
}
}1234567891011121314151617181920212223242526
通过在地址空间中找到mp的数据结构后,得到每个CPU的apicid和CPU数量。
通过mpinit()函数,有关的cpus结构体也初始完成了,接下来在main()函数中调用startothers函数启动其他CPU。
startothers让其他CPU执行名为entryother.S对应的代码.
entryother.S是作为独立的二进制文件与内核二进制文件一起组成整体的ELF文件,通过在LD链接器中-b参数来整合一个独立的二进制文件,在内核中通过_binary_entryother_start和_binary_entryother_size来引用,具体的makefile如下:
$(LD) $(LDFLAGS) -T kernel.ld -o kernelmemfs entry.o $(MEMFSOBJS) -b binary initcode entryother fs.img
entryothers在生成二进制文件时指定入口点为start以及加载地址和链接地址都为0x7000
entryother: entryother.S
$(CC) $(CFLAGS) -fno-pic -nostdinc -I. -c entryother.S
$(LD) $(LDFLAGS) -N -e start -Ttext 0x7000 -o bootblockother.o entryother.o
$(OBJCOPY) -S -O binary -j .text bootblockother.o entryother
$(OBJDUMP) -S bootblockother.o > entryother.asm
在startothers中,首先将entryothers移动到物理地址0x7000处使其能正常运行,在这里需要注意的是此时entryothers相当于CPU刚上电的情形,因为这是其他CPU最初运行的内核代码,所以没有开启保护模式和分页机制,entryothers将页表设置为entrypgdir,在设置页表前,虚拟地址等于物理地址
// Write entry code to unused memory at 0x7000.
// The linker has placed the image of entryother.S in
// _binary_entryother_start.
code = P2V(0x7000);
memmove(code, _binary_entryother_start, (uint)_binary_entryother_size);
然后循环逐个开启每个CPU让每个CPU从entryothers中start标号开始运行:
for(c = cpus; c < cpus+ncpu; c++){
if(c == cpus+cpunum()) // We've started already.
continue;
// Tell entryother.S what stack to use, where to enter, and what
// pgdir to use. We cannot use kpgdir yet, because the AP processor
// is running in low memory, so we use entrypgdir for the APs too.
stack = kalloc();
*(void**)(code-4) = stack + KSTACKSIZE;
*(void**)(code-8) = mpenter;
*(int**)(code-12) = (void *) V2P(entrypgdir);
lapicstartap(c->apicid, V2P(code));
// wait for cpu to finish mpmain()
while(c->started == 0)
;
}
在这里同时还设置了每个CPU特有的内核栈以及共有的页表,并设置mpenter为entryothers最后跳转回内核的地址,entryothers主要进行CPU必要的初始化:从实模式切换到保护模式,开启分页机制,最后跳转到mpenter处,跳回内核。
for(c = cpus; c < cpus+ncpu; c++){
if(c == cpus+cpunum()) // We've started already.
continue;
// Tell entryother.S what stack to use, where to enter, and what
// pgdir to use. We cannot use kpgdir yet, because the AP processor
// is running in low memory, so we use entrypgdir for the APs too.
stack = kalloc();
*(void**)(code-4) = stack + KSTACKSIZE;
*(void**)(code-8) = mpenter;
*(int**)(code-12) = (void *) V2P(entrypgdir);
lapicstartap(c->apicid, V2P(code));
// wait for cpu to finish mpmain()
while(c->started == 0)
;
}
mpter设置新的内核页表和进行段初始化,最后调用mpmain开始调度进程。
switchkvm();
seginit();
lapicinit();
mpmain();
至此,所有的CPU都已经正常工作。
公众号推荐
推荐一波自己的公众号:五道口的程序狐
里面有一个聊天机器人,抚慰你的心灵
