[toc]
大数据安全体系及Sentry安全授权管理介绍(五星)
总结
- 大数据平台四层安全:外围安全(防火墙、系统登录认证等)、数据安全(存储安全、传输安全、加解密、脱敏)、访问安全(授权)、访问行为监控(访问行为审计)
- 大数据平台安全历史
- Linux简单用户授权:开始HDFS授权体系沿用的是Linux授权体系,Linux只有所有者、所在组和其他三种权限,不能满足细致的用户授权要求。
- HDFS ACL用户细粒度授权:后来Hadoop2.4.0中添加了对HDFS ACL(Access Control Lists)的支持,满足了用户授权要求,但不能满足细粒度的数据授权要求。
- Hive表粒度授权:Hiveserver2能够使用grant/revoke语句来限制用户对数据库、表、视图的访问权限,行列权限的控制是通过生成视图来实现的。Hiveserver2的授权体系是为防止正常用户误操作而提供保障机制;不是为保护敏感数据的安全性而设计的。
- Sentry列粒度授权:Sentry将Hiveserver2中支持的数据对象从数据库/表/视图扩展到了服务器,URI以及列粒度。
- Sentry授权方式:权限-》角色-》用户组-》用户
- 从权限到角色,再到用户组都是通过grant/revoke的SQL语句来授予的。
- 从“用户组”到能够影响“用户”是通过Hadoop自身的用户-组映射来实现的。Hadoop提供两种映射:一种是本地服务器上的Linux/Unix用户到所在组的映射;另一种是通过LDAP实现的用户到所属组的映射
- Sentry局限:目前Sentry1.4能够支持的授权级别还局限于SELECT,INSERT,ALL这三个级别,但后续版本中已经能够支持到与Hiveserver2现有的水平。Sentry来源于Hiveserver2中的授权管理模型,但却不局限于只管理Hive,而希望能管理Impala, Solr等其他需要授权管理的查询引擎。
问题导读
1.大数据安全分为哪四个体系?
2.什么是外围安全技术?
3.什么是外围安全技术?
4.Sentry的体系结构中有哪三个重要的组件?
大数据的安全体系
大数据平台安全体系的四个层次说起:外围安全、数据安全、访问安全以及访问行为监控;如下图所示;
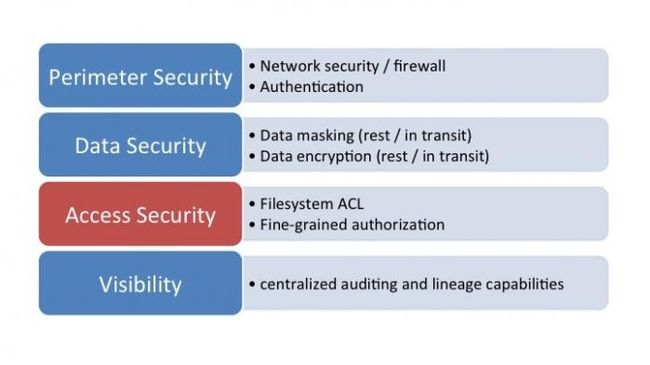
外围安全:多指传统意义上提到的网络安全技术,如防火墙,登陆认证等;
数据安全:从狭义上说包括对用户数据的加解密,又可细分为存储加密和传输加密;还包括用户数据的脱敏,脱敏可以看做“轻量级”的数据加密。如某人的生日为“2014-12-12”,脱敏后的数据为“2014-x-x”。数据的轮廓依然存在,但已无法精确定位数值。脱敏的程度越高数据可辨认度越低。上述的例子还可脱敏为“x-x-x”,相当于完全对外屏蔽该信息。
访问安全:主要是对用户的授权进行管理。Linux/Unix系统中用户-组的读、写、执行权限管理堪称其中的经典模型。HDFS对这一概念进行了扩充,形成了更加完备的ACL体系;另外随着大数据的应用的普及和深入,文件内部数据访问权限差异化的需求也变得越来越重要;
访问行为监控:多指记录用户对系统的访问行为:如查看哪个文件;运行了哪些SQL查询;访问行为监控一方面为了进行实时报警,迅速处置非法或者危险的访问行为;另一方面为了事后调查取证,从长期的数据访问行为中分析定位特定的目的。
在这四个安全的层次中,第三层同上层业务的关系最为直接:应用程序的多租户,分权限访问控制都直接依赖这一层的技术实现。
HDFS的授权体系
Hadoop生态圈长久以来一直沿用Linux/Unix系统的授权管理模型,将文件的访问权限分为读-写两种权限(HDFS上没有可执行文件的概念),将权限的所有者划分为三个大类:拥有者(owner),所在组(group),以及其他人(other)。这种模型限制权限的所有者只能有三类。如果试图增加一个新的“组”,并设定该组的用户拥有不同于owner,group或other的权限,现有的Linux/Unix授权模型是无法优雅地解决这个问题的。
举例来说明上述状况:假设有一个销售部门,部门经理manager具有修改销售数据sales_data的权利;销售部门的成员具有查看sales_data的权利,销售部门以外的人无法看到销售数据sales_data。那么对于销售数据sales_data的授权如下所示:
-rw-r----- 3 manager sales 0 2015-01-25 18:51 sales_data
后来该销售部门扩充了人员,又来两个销售经理,一个叫manager1,另一个叫manager2。这两个销售经理也被允许修改销售数据。这种情况下,manager1和manager2只能使用一个新账号manager_account,然后使该账号能够使用setuid对sales_data进行修改。这使得对同一份数据的权限管理变得复杂而不容易维护。
由于上述问题的存在,Hadoop2.4.0中添加了对HDFS ACL(Access Control Lists)的支持。这一新特性很好地解决了上述的问题。然而随着Hadoop在企业中广泛地应用,越来越多的业务场景要求大数据访问控制的粒度也不再局限在文件级别,而是更加细致地约束文件内部的数据哪些能被读写,哪些只能被读,哪些完全不允许被访问。对于基于SQL的大数据引擎来说,数据访问不止要到表粒度,更要精确到行列级别。
Hiveserver2的授权
Hive是早期将高级查询语言SQL引入Hadoop平台的引擎之一,早期的Hive服务器进程被称作Hiveserver1;Hiveserver1既不支持处理并行的多个连接,又不支持访问授权控制;后来这两个问题在Hiveserver2上被解决,Hiveserver2能够使用grant/revoke语句来限制用户对数据库、表、视图的访问权限,行列权限的控制是通过生成视图来实现的;但Hiveserver2的授权管理体系被认为存在问题,那就是任何通过认证登陆的用户都能够为自己增加对任何资源的访问权限。也就是说Hiveserver2提供的不是一种安全的授权体系,Hiveserver2的授权体系是为防止正常用户误操作而提供保障机制;不是为保护敏感数据的安全性而设计的。然而这些更多的是某些公司的说辞,事实上Hiveserver2自身的安全体系也在逐步完善,上述问题也在快速修复中。
但授权管理其实不止是Hive需要,其他的查询引擎也迫切需要这些技术来完善和规范应用程序对数据的访问。对于细粒度授权管理的实现,很大一部分功能在各引擎之间是可以公用的,因此独立实现的授权管理工具是非常必要的。
Sentry提供的安全授权管理
在这样的背景下,Cloudera公司的一些开发者利用Hiveserver2中现有的授权管理模型,扩展并细化了很多细节,完成了一个相对具有使用价值的授权管理工具Sentry,下图是Sentry与Hiveserver2中的授权管理模型的对比:
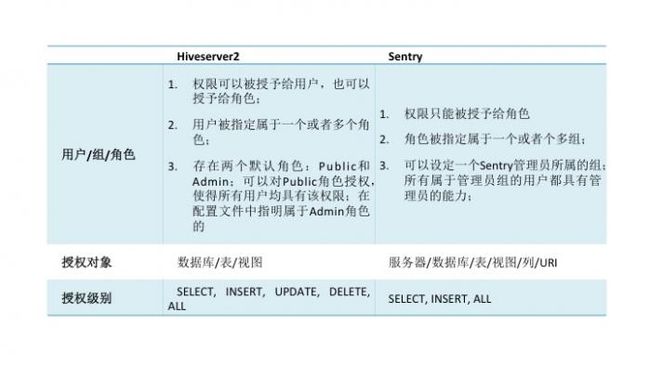
Sentry的很多基本模型和设计思路都来源于Hiveserver2,但在其基础之上加强了RBAC的概念。在Sentry中,所有的权限都只能授予角色,当角色被挂载到用户组的时候,该组内的用户才具有相应的权限。权限à角色à用户组à用户,这一条线的映射关系在Sentry中显得尤为清晰,这条线的映射显示了一条权限如何能最后被一个用户所拥有;从权限到角色,再到用户组都是通过grant/revoke的SQL语句来授予的。从“用户组”到能够影响“用户”是通过Hadoop自身的用户-组映射来实现的。Hadoop提供两种映射:一种是本地服务器上的Linux/Unix用户到所在组的映射;另一种是通过LDAP实现的用户到所属组的映射;后者对于大型系统而言更加适用,因为具有集中配置,易于修改的好处。
Sentry将Hiveserver2中支持的数据对象从数据库/表/视图扩展到了服务器,URI以及列粒度。虽然列的权限控制可以用视图来实现,但是对于多用户,表数量巨大的情况,视图的方法会使得给视图命名变得异常复杂;而且用户原先写的针对原表的查询语句,这时就无法直接使用,因为视图的名字可能与原表完全不同。
目前Sentry1.4能够支持的授权级别还局限于SELECT,INSERT,ALL这三个级别,但后续版本中已经能够支持到与Hiveserver2现有的水平。Sentry来源于Hiveserver2中的授权管理模型,但却不局限于只管理Hive,而希望能管理Impala, Solr等其他需要授权管理的查询引擎,Sentry的架构图如下所示:
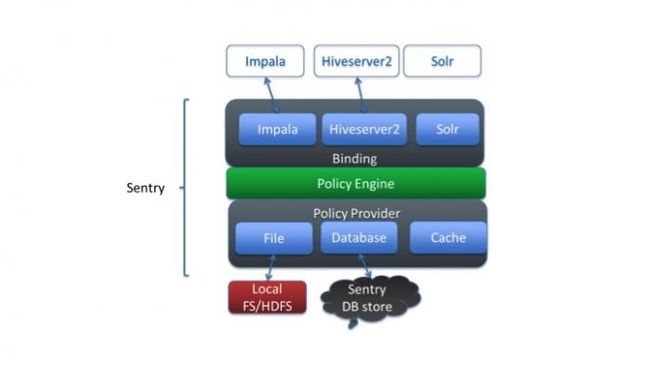
Sentry的体系结构中有三个重要的组件:一是Binding;二是Policy Engine;三是Policy Provider。
Binding实现了对不同的查询引擎授权,Sentry将自己的Hook函数插入到各SQL引擎的编译、执行的不同阶段。这些Hook函数起两大作用:一是起过滤器的作用,只放行具有相应数据对象访问权限的SQL查询;二是起授权接管的作用,使用了Sentry之后,grant/revoke管理的权限完全被Sentry接管,grant/revoke的执行也完全在Sentry中实现;对于所有引擎的授权信息也存储在由Sentry设定的统一的数据库中。这样所有引擎的权限就实现了集中管理。
Policy Engine判定输入的权限要求与已保存的权限描述是否匹配,Policy Provider负责从文件或者数据库中读取出原先设定的访问权限。Policy Engine以及Policy Provider其实对于任何授权体系来说都是必须的,因此是公共模块,后续还可服务于别的查询引擎。
小结
大数据平台上细粒度的访问权限控制各家都在做,当然平台厂商方面主导的还是Cloudera和Hortonworks两家,Cloudera主推Sentry为核心的授权体系;Hortonwork一方面靠对开源社区走向得把控,另一方面靠收购的XA Secure。无论今后两家公司对大数据平台市场的影响力如何变化,大数据平台上的细粒度授权访问都值得我们去学习。