概述
Prometheus从2016年加入CNCF,到2018年8月毕业,现在已经成为Kubernetes的官方监控方案,接下来的几篇文章将详细解读Promethues(2.x)
Prometheus可以从Kubernetes集群的各个组件中采集数据,比如kubelet中自带的cadvisor,api-server等,而node-export就是其中一种来源
Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取,默认的抓取地址为http://CURRENT_IP:9100/metrics
node-exporter用于采集服务器层面的运行指标,包括机器的loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的zabbix-agent
node-export由prometheus官方提供、维护,不会捆绑安装,但基本上是必备的exporter
功能
node-exporter用于提供*NIX内核的硬件以及系统指标。
- 如果是windows系统,可以使用WMI exporter
- 如果是采集NVIDIA的GPU指标,可以使用prometheus-dcgm
根据不同的*NIX操作系统,node-exporter采集指标的支持也是不一样的,如:
- diskstats 支持 Darwin, Linux
- cpu 支持Darwin, Dragonfly, FreeBSD, Linux, Solaris等,
详细信息参考:node_exporter
我们可以使用 --collectors.enabled参数指定node_exporter收集的功能模块,或者用--no-collector指定不需要的模块,如果不指定,将使用默认配置。
部署
二进制部署:
- 下载地址:从https://github.com/prometheus/node_exporter/releases
- 解压文件:tar -xvzf ****.tar.gz
- 开始运行:./node_exporter
./node_exporter -h 查看帮助
usage: node_exporter []
Flags:
-h, --help
--collector.diskstats.ignored-devices
--collector.filesystem.ignored-mount-points
--collector.filesystem.ignored-fs-types
--collector.netdev.ignored-devices
--collector.netstat.fields
--collector.ntp.server="127.0.0.1"
.....
./node_exporter运行后,可以访问http://${IP}:9100/metrics,就会展示对应的指标列表
Docker安装:
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs /host
k8s中安装:
node-exporter.yaml文件:
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
labels:
app: node-exporter
name: node-exporter
name: node-exporter
spec:
clusterIP: None
ports:
- name: scrape
port: 9100
protocol: TCP
selector:
app: node-exporter
type: ClusterIP
----
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
spec:
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/tryk8s/node-exporter:latest
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
hostNetwork: true
hostPID: true
kubectl create -f node-exporter.yaml
得到一个daemonset和一个service对象,部署后,为了能够让Prometheus能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
也可以使用prometheus.io/scrape: 'true'标识来自动获取service的metric接口
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
配置完成后,重启prometheus就能看到对应的指标
查看指标:
直接查看:
如果是二进制或者docker部署,部署成功后可以访问:http://${IP}:9100/metrics
会输出下面格式的内容,包含了node-exporter暴露的所有指标:
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 6.1872e-05
go_gc_duration_seconds{quantile="0.25"} 0.000119463
go_gc_duration_seconds{quantile="0.5"} 0.000151156
go_gc_duration_seconds{quantile="0.75"} 0.000198764
go_gc_duration_seconds{quantile="1"} 0.009889647
go_gc_duration_seconds_sum 0.257232201
go_gc_duration_seconds_count 1187
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="guest"} 0
node_cpu{cpu="cpu0",mode="guest_nice"} 0
node_cpu{cpu="cpu0",mode="idle"} 68859.19
node_cpu{cpu="cpu0",mode="iowait"} 167.22
node_cpu{cpu="cpu0",mode="irq"} 0
node_cpu{cpu="cpu0",mode="nice"} 19.92
node_cpu{cpu="cpu0",mode="softirq"} 17.05
node_cpu{cpu="cpu0",mode="steal"} 28.1
Prometheus查看:
类似go_gc_duration_seconds和node_cpu就是metric的名称,如果使用了Prometheus,则可以在http://${IP}:9090/页面的指标中搜索到以上的指标:
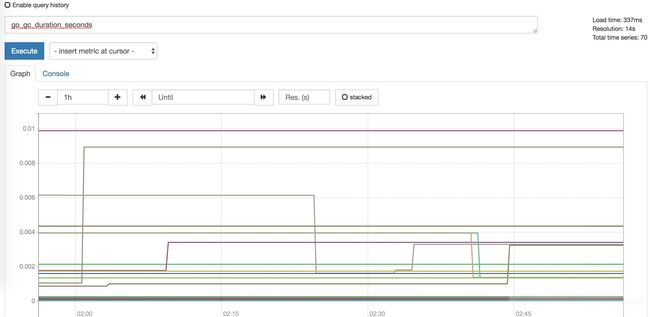
常用指标类型有:
node_cpu:系统CPU使用量
node_disk*:磁盘IO
node_filesystem*:文件系统用量
node_load1:系统负载
node_memeory*:内存使用量
node_network*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
Grafana查看:
Prometheus虽然自带了web页面,但一般会和更专业的Grafana配套做指标的可视化,Grafana有很多模板,用于更友好地展示出指标的情况,如Node Exporter for Prometheus
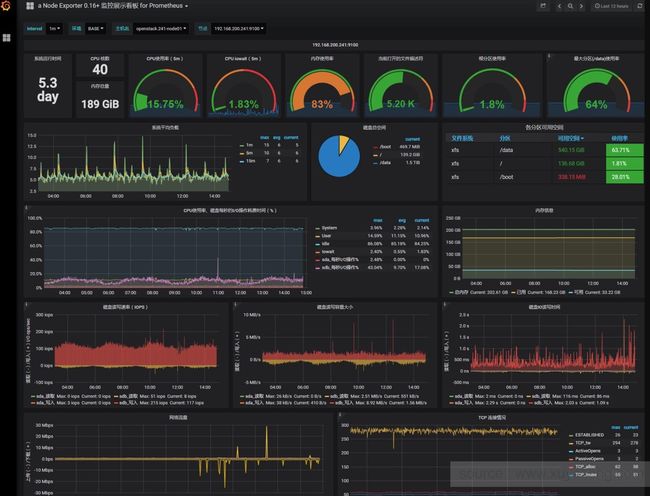
在grafana中配置好变量、导入模板就会有上图的效果。
深入解读
node-exporter是Prometheus官方推荐的exporter,类似的还有
- HAProxy exporter
- Collectd exporter
- SNMP exporter
- MySQL server exporter
- ....
官方推荐的都会在https://github.com/prometheus下,在exporter推荐页,也会有很多第三方的exporter,由个人或者组织开发上传,如果有自定义的采集需求,可以自己编写exporter,具体的案例可以参考后续的[自定义Exporter]文章
版本问题
因为node_exporter是比较老的组件,有一些最佳实践并没有merge进去,比如符合Prometheus命名规范(https://prometheus.io/docs/practices/naming/),因此建议使用较新的0.16和0.17版本,目前(2019.1)最新版本为0.17
一些指标名字的变化(详细比对)
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
解决版本问题的方法有两种:
- 一是在机器上启动两个版本的node-exporter,都让prometheus去采集。
- 二是使用指标转换器,他会将旧指标名称转换为新指标
对于grafana的展示,可以找同时支持两套指标的dashboard模板
Collector
node-exporter的主函数:
// Package collector includes all individual collectors to gather and export system metrics.
package collector
import (
"fmt"
"sync"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/common/log"
"gopkg.in/alecthomas/kingpin.v2"
)
// Namespace defines the common namespace to be used by all metrics.
const namespace = "node"
可以看到exporter的实现需要引入github.com/prometheus/client_golang/prometheus库,client_golang是prometheus的官方go库,既可以用于集成现有应用,也可以作为连接Prometheus HTTP API的基础库。
比如定义了基础的数据类型以及对应的方法:
Counter:收集事件次数等单调递增的数据
Gauge:收集当前的状态,比如数据库连接数
Histogram:收集随机正态分布数据,比如响应延迟
Summary:收集随机正态分布数据,和 Histogram 是类似的
switch metricType {
case dto.MetricType_COUNTER:
valType = prometheus.CounterValue
val = metric.Counter.GetValue()
case dto.MetricType_GAUGE:
valType = prometheus.GaugeValue
val = metric.Gauge.GetValue()
case dto.MetricType_UNTYPED:
valType = prometheus.UntypedValue
val = metric.Untyped.GetValue()
client_golang库的详细解析可以参考:theory-source-code
本文为容器监控实践系列文章,完整内容见:container-monitor-book