1、目标确定
本次分析主要探寻泰坦尼克号上的生还率和各因素(客舱等级、年龄、性别、有无父母、客户花费等)的关系。
2、数据获取
Kaggle上titanic的数据集中的训练集train.csv
3、数据清洗
(1) 缺失值处理
数据清理上,我用的是python,对整个数据的描述性分析:
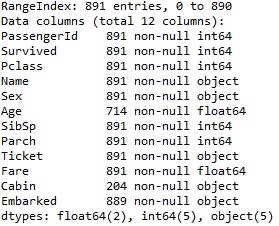
由图可知,有三个变量有缺失值,分别是Age,Cabin和Embarked。
Embarked是分类型变量,而且缺失值很少,所以可以用众数填充。

通过python代码,对Embarked的数据进行统计,发现共有3个维度,所以有三个登陆港口C、Q和S,其中S最多,所以缺失值都填充为S。
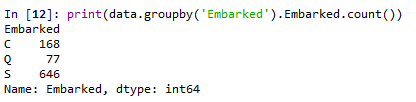
Cabin表示的是所在的客舱,对于缺失值可能表示不在客舱内,所以,把缺失值都填充为C0,以表示不在客舱内。
对于数值型变量Age,采用随机森林算法来预测缺失值。因为变量只能为数值型变量,所以,对于选取的模型数据包含'Age','Survived','Parch','SibSp','Pclass','Fare'等6个变量。先通过Age把缺失值和未缺失的数据分开,然后采用随机森林模型用未缺失的数据来预测缺失的数据。
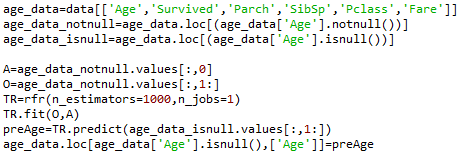
这时候,选取的模型数据里面就没有缺失值。然后循环几次随机森林,这次的数据模型发生了些变化,用没有缺失值的模型数据age_data来预测之前的缺失数据age_data_isnull,循环几次,把最后的结果赋值给总的数据data。
因为随机森林产生的数据是浮点型,而总数据是整数型的,所以赋值前需要转换一下格式。

数据清理后,最后的数据信息如下:

测试集的缺失值处理方式一样。
(2) 数据整理
为了方便分析,需要对一些数据进行整理。
对于PassengerId、Name和Ticket,对于数据分析没有多大用处,所以首先删除。
对于Age这个变量,首先进行描述性统计:
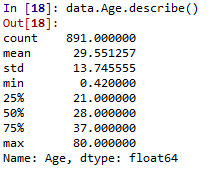
最大值为80,最小值为0.42,跨度非常大,不能每个年龄都去统计,所以,需要把年龄分成4段,分别是小与12岁、12-18岁、18-65岁以及大于65岁,缩小成4个维度,方便统计。

同理还有SibSp、Parch和Cabin,维度要多。
首先对SibSp进行描述分析:

“0”代表没有兄弟姐妹,没有兄弟姐妹占大多数,所以,SibSp可以分成两个维度,有兄弟姐妹和无兄弟姐妹。
同理,Parch分为两个维度,有父母兄弟和没有父母兄弟。
Cabin分为有客舱和无客舱两个维度。
4、数据分析
本次数据总共有891 个样本量,生还者为342人,生还率为38%。
(1) Pclass分析

泰坦尼克号上总共有三个等级的船舱,等级越高,代表客户贡献的价值越高,越重视客户,如图,各个等级舱的人数分别是216、184和491,生还人数为136、87和119,生还率分别为63%、47%和24%,生还率依船舱的等级递减,充分体现了“富人先行”。
(2) Age分析
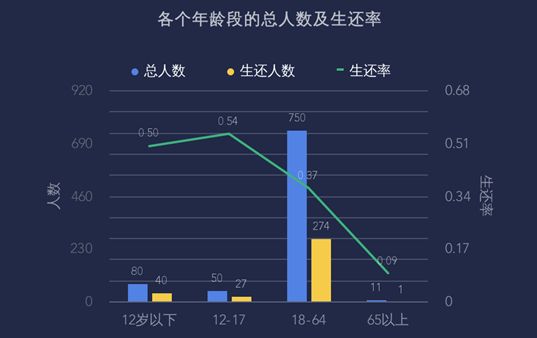
把年龄分成了4个维度,各个年龄段的人数分别为80、50、750和11人,生还人数分别为40、27、274和1人,生还率为50%、54%、37%和9%,年龄在12-17岁的生还率最高,其次是12岁以下的,在这场灾难中,大家把机会都让给了小孩和年轻人。
(3) Sex分析
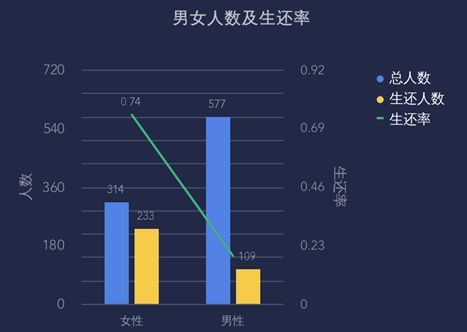
男生和女生人数分别为314和577,女性偏少,但是,女生生还233人,生还率为%74,男生生还109人,生还率为19%,充分体现了“女士优先”。
(4) SibSp分析

无兄弟姐妹的人数为608,有兄弟姐妹的是283,无兄弟姐妹的人数偏少,但是,无兄弟姐妹的生还率为47%,高于有兄弟姐妹的37%,说明有兄弟姐妹的人在离别时会更能引起别人的关注,更容易一起获救。
(5) Parch分析

无父母子女与有父母子女的人数分别为678和213,无父母子女的人数占大多数,但是生还率却是有父母子女的人的生还率高,原因同上,有父母子女的更容易获得别人的同情与注意,同时也求生欲更强。
(6) Fare分析

生还者的平均票价为48.4,未生还者的票价为22.12,生还者的远远高于未生还者的,和Pclass一样,体现了“富人悠闲”。
(7) Cabin分析

无客舱与有客舱的人数分别为687和204,无客舱的人占大多数,无客舱的生还人数为206,生还率为30%,有客舱的生还人数为136,生还率为67%,有客舱的生还率远远高于无客舱的,有无客舱与乘客的经济能力挂钩,所以,还是体现了“富人优先”。
(8) Embarked分析
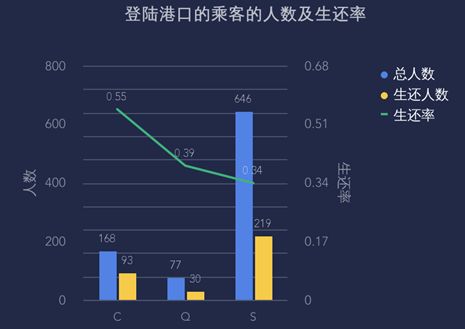
登陆港口总共有3个,分别为C、Q和S港口,从图中可看出,S港口登陆的乘客最多,共646人,C港口其次,是168人,Q港口最少,77人,生还人数中S港口的生还人数最多,为219人,但生还率是最低的,为34%,生还率最高的是C港口,为55%,Q港口的生还人数是30,生还率是39%,可以看出,C港口上船的乘客生还率最高。
5 特征处理
最后,经过分析,选出了能影响生存率的几个特征,保留下‘Pclass‘,’Sex’,‘Age’,‘SibSp’,‘Parch’,‘Fare’,‘Cabin‘,’Embarked’几个变量。
对于Age这个变量,把女性设为1,男性设为0,同理,将每个变量的特征强的设为1,剩下的设为0,把值都变成布尔型的值,调用伯努力朴素贝叶斯,预测测试集的结果。
最后提交到kaggle中,评分为0.736。
分不高,主要是体验一次数据处理过程。