前言
整个图元的合成,大致上分为如下6个步骤:
- 1.preComposition 预处理合成
- 2.rebuildLayerStacks 重新构建Layer栈
- 3.setUpHWComposer HWC的渲染或者准备
- 4.doDebugFlashRegions 打开debug绘制模式
- 5.doTracing 跟踪打印
- 6.doComposition 合成图元
- 7.postComposition 图元合成后的vysnc等收尾工作。
上文已经分析了1,2,3点介绍了SF绘制准备流程。本着重分析第6,7 两个SF图元合成步骤。
如果遇到问题,请到本文进行讨论https://www.jianshu.com/p/65a3f8ac88c1
正文
doComposition OpenGL es合成图元
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::doComposition() {
const bool repaintEverything = android_atomic_and(0, &mRepaintEverything);
for (size_t dpy=0 ; dpy& hw(mDisplays[dpy]);
if (hw->isDisplayOn()) {
// transform the dirty region into this screen's coordinate space
const Region dirtyRegion(hw->getDirtyRegion(repaintEverything));
// repaint the framebuffer (if needed)
doDisplayComposition(hw, dirtyRegion);
hw->dirtyRegion.clear();
hw->flip();
}
}
postFramebuffer();
}
合成图元分为两部分:
- 1.doDisplayComposition 通过DisplayDevice合成图元
- 2.postFramebuffer 合成完毕之后,需要的话,将会把图元发送到fb驱动。
doDisplayComposition 合成图元
void SurfaceFlinger::doDisplayComposition(
const sp& displayDevice,
const Region& inDirtyRegion)
{
...
if (!doComposeSurfaces(displayDevice)) return;
displayDevice->swapBuffers(getHwComposer());
}
- 1.doComposeSurfaces 合成每一个Surface对应的Layer中的图元
- 2.swapBuffers 进行一次图元交换,把数据推到FrameBufferSurface中进一步消费。
doComposeSurfaces 合成图元
这个方法很长,我拆开成2部分分析:
bool SurfaceFlinger::doComposeSurfaces(const sp& displayDevice)
{
const Region bounds(displayDevice->bounds());
const DisplayRenderArea renderArea(displayDevice);
const auto hwcId = displayDevice->getHwcDisplayId();
const bool hasClientComposition = getBE().mHwc->hasClientComposition(hwcId);
bool applyColorMatrix = false;
bool needsLegacyColorMatrix = false;
bool legacyColorMatrixApplied = false;
if (hasClientComposition) {
Dataspace outputDataspace = Dataspace::UNKNOWN;
if (displayDevice->hasWideColorGamut()) {
outputDataspace = displayDevice->getCompositionDataSpace();
}
getBE().mRenderEngine->setOutputDataSpace(outputDataspace);
getBE().mRenderEngine->setDisplayMaxLuminance(
displayDevice->getHdrCapabilities().getDesiredMaxLuminance());
const bool hasDeviceComposition = getBE().mHwc->hasDeviceComposition(hwcId);
const bool skipClientColorTransform = getBE().mHwc->hasCapability(
HWC2::Capability::SkipClientColorTransform);
applyColorMatrix = !hasDeviceComposition && !skipClientColorTransform;
if (applyColorMatrix) {
getRenderEngine().setupColorTransform(mDrawingState.colorMatrix);
}
needsLegacyColorMatrix =
(displayDevice->getActiveRenderIntent() >= RenderIntent::ENHANCE &&
outputDataspace != Dataspace::UNKNOWN &&
outputDataspace != Dataspace::SRGB);
if (!displayDevice->makeCurrent()) {
getRenderEngine().resetCurrentSurface();
if(!getDefaultDisplayDeviceLocked()->makeCurrent()) {
}
return false;
}
if (hasDeviceComposition) {
getBE().mRenderEngine->clearWithColor(0, 0, 0, 0);
} else {
const Region letterbox(bounds.subtract(displayDevice->getScissor()));
Region region(displayDevice->undefinedRegion.merge(letterbox));
if (!region.isEmpty()) {
drawWormhole(displayDevice, region);
}
}
if (displayDevice->getDisplayType() != DisplayDevice::DISPLAY_PRIMARY) {
const Rect& bounds(displayDevice->getBounds());
const Rect& scissor(displayDevice->getScissor());
if (scissor != bounds) {
const uint32_t height = displayDevice->getHeight();
getBE().mRenderEngine->setScissor(scissor.left, height - scissor.bottom,
scissor.getWidth(), scissor.getHeight());
}
}
}
...
}
在doComposeSurfaces第一部分中,会判断每一个DisplayDevice中是否包含着Client模式的Layer,如果有就会初始化Layer在RenderEngine的环境。
- 1.获取DataSpace设置到RenderEngine
- 2.RenderEngine 设置ColorMatrix 颜色矩阵
- 3.DisplayService.makeCurrent 绑定当前OpenGL es环境
- 4.如果包含了Device模式,也就是存在通过HWC进行OverLayer绘制的Layer,则会调用OpenGL es 清空背景,否则调用drawWormhole
- 5.最后对Layer的区域在OpenGL es中进行裁剪。
DisplayService makeCurrent
bool DisplayDevice::makeCurrent() const {
bool success = mFlinger->getRenderEngine().setCurrentSurface(*mSurface);
setViewportAndProjection();
return success;
}
RenderEngine会设置DisplayDevice的mSurface为当前渲染对象。mSurface就是第一篇文章中,提到过的由RenderEngine生成一个RE::Surface对象。最后初始化整个实图矩阵,这是一个正交投射。
drawWormhole
void SurfaceFlinger::drawWormhole(const sp& displayDevice, const Region& region) const {
const int32_t height = displayDevice->getHeight();
auto& engine(getRenderEngine());
engine.fillRegionWithColor(region, height, 0, 0, 0, 0);
}
乍看之下,好像这个方法和上面包含Device模式清空背景似乎一致,我们看看源码:
void RenderEngine::fillRegionWithColor(const Region& region, uint32_t height, float red,
float green, float blue, float alpha) {
size_t c;
Rect const* r = region.getArray(&c);
Mesh mesh(Mesh::TRIANGLES, c * 6, 2);
Mesh::VertexArray position(mesh.getPositionArray());
for (size_t i = 0; i < c; i++, r++) {
position[i * 6 + 0].x = r->left;
position[i * 6 + 0].y = height - r->top;
position[i * 6 + 1].x = r->left;
position[i * 6 + 1].y = height - r->bottom;
position[i * 6 + 2].x = r->right;
position[i * 6 + 2].y = height - r->bottom;
position[i * 6 + 3].x = r->left;
position[i * 6 + 3].y = height - r->top;
position[i * 6 + 4].x = r->right;
position[i * 6 + 4].y = height - r->bottom;
position[i * 6 + 5].x = r->right;
position[i * 6 + 5].y = height - r->top;
}
setupFillWithColor(red, green, blue, alpha);
drawMesh(mesh);
}
void RenderEngine::clearWithColor(float red, float green, float blue, float alpha) {
glClearColor(red, green, blue, alpha);
glClear(GL_COLOR_BUFFER_BIT);
}
能看到clearWithColor其实是把整个OpenGL es对应的屏幕区域背景全部清空为黑色。fillRegionWithColor其实就是把这个区域内的颜色填充为一种颜色,这里是黑色。
裁剪我们就暂时不需要关注。接下来,我们来看看后半段核心逻辑。
const Transform& displayTransform = displayDevice->getTransform();
bool firstLayer = true;
for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) {
const Region clip(bounds.intersect(
displayTransform.transform(layer->visibleRegion)));
if (!clip.isEmpty()) {
switch (layer->getCompositionType(hwcId)) {
case HWC2::Composition::Cursor:
case HWC2::Composition::Device:
case HWC2::Composition::Sideband:
case HWC2::Composition::SolidColor: {
const Layer::State& state(layer->getDrawingState());
if (layer->getClearClientTarget(hwcId) && !firstLayer &&
layer->isOpaque(state) && (state.color.a == 1.0f)
&& hasClientComposition) {
layer->clearWithOpenGL(renderArea);
}
break;
}
case HWC2::Composition::Client: {
...
layer->draw(renderArea, clip);
break;
}
default:
break;
}
} else {
}
firstLayer = false;
}
if (applyColorMatrix) {
getRenderEngine().setupColorTransform(mat4());
}
if (needsLegacyColorMatrix && legacyColorMatrixApplied) {
getRenderEngine().setSaturationMatrix(mat4());
}
getBE().mRenderEngine->disableScissor();
return true;
值得注意的是,在真正的合成步骤中,分别对Cursor,Device,Sideband,SolidColor,Client进行处理。
对于前四者,只是简单做了Layer的背景清空,不允许背景对HWC的渲染造成影响,把渲染时机往后移动。在这个步骤只会处理Client渲染模式。最后检测是否有颜色矩阵,有则会设置。
layer->draw会直接调用子类的onDraw方法,这个方法就是OpenGL es绘制合成核心逻辑。
BufferLayer onDraw
文件:/frameworks/native/services/surfaceflinger/BufferLayer.cpp
void BufferLayer::onDraw(const RenderArea& renderArea, const Region& clip,
bool useIdentityTransform) const {
if (CC_UNLIKELY(getBE().compositionInfo.mBuffer == 0)) {
...
return;
}
// Bind the current buffer to the GL texture, and wait for it to be
// ready for us to draw into.
status_t err = mConsumer->bindTextureImage();
...
bool blackOutLayer = isProtected() || (isSecure() && !renderArea.isSecure());
auto& engine(mFlinger->getRenderEngine());
if (!blackOutLayer) {
const bool useFiltering = getFiltering() || needsFiltering(renderArea) || isFixedSize();
float textureMatrix[16];
mConsumer->setFilteringEnabled(useFiltering);
mConsumer->getTransformMatrix(textureMatrix);
if (getTransformToDisplayInverse()) {
uint32_t transform = DisplayDevice::getPrimaryDisplayOrientationTransform();
mat4 tr = inverseOrientation(transform);
sp p = mDrawingParent.promote();
if (p != nullptr) {
const auto parentTransform = p->getTransform();
tr = tr * inverseOrientation(parentTransform.getOrientation());
}
const mat4 texTransform(mat4(static_cast(textureMatrix)) * tr);
memcpy(textureMatrix, texTransform.asArray(), sizeof(textureMatrix));
}
// Set things up for texturing.
mTexture.setDimensions(getBE().compositionInfo.mBuffer->getWidth(),
getBE().compositionInfo.mBuffer->getHeight());
mTexture.setFiltering(useFiltering);
mTexture.setMatrix(textureMatrix);
engine.setupLayerTexturing(mTexture);
} else {
engine.setupLayerBlackedOut();
}
drawWithOpenGL(renderArea, useIdentityTransform);
engine.disableTexturing();
}
-
- BufferLayerConsumer.bindTextureImage 把GraphicBuffer绑定到OpenGL es。
-
- 由于关于protect的标志位和secure标志位默认都是关闭的,此时blackOutLayer是false。在setFilteringEnabled计算裁剪,旋转等效果矩阵,getTransformMatrix获取在setFilteringEnabled计算出来的矩阵,把这个矩阵赋值给Texture对象,并且通过setupLayerTexturing 把这个矩阵作为纹理绑定都OpenGL es中。
-
- drawWithOpenGL 核心是调用glDrawArray 合成所有OpenGL es步骤中的绘制效果。
BufferLayerConsumer bindTextureImage
文件:/frameworks/native/services/surfaceflinger/BufferLayer.cpp
status_t BufferLayerConsumer::bindTextureImage() {
Mutex::Autolock lock(mMutex);
return bindTextureImageLocked();
}
status_t BufferLayerConsumer::bindTextureImageLocked() {
mRE.checkErrors();
if (mCurrentTexture == BufferQueue::INVALID_BUFFER_SLOT && mCurrentTextureImage == nullptr) {
mRE.bindExternalTextureImage(mTexName, *mRE.createImage());
return NO_INIT;
}
const Rect& imageCrop = canUseImageCrop(mCurrentCrop) ? mCurrentCrop : Rect::EMPTY_RECT;
status_t err = mCurrentTextureImage->createIfNeeded(imageCrop);
if (err != NO_ERROR) {
...
return UNKNOWN_ERROR;
}
mRE.bindExternalTextureImage(mTexName, mCurrentTextureImage->image());
return doFenceWaitLocked();
}
先通过canUseImageCrop判断是否能参见,最后为mCurrentTextureImage设置裁剪区域。mCurrentTextureImage是什么呢?其实就是RE::Image对象,内部包含了GraphicBuffer。
最后通过doFenceWaitLocked 进行Fence进行等待OpenGL es完成绑定图元的完成。
RenderEngine bindExternalTextureImage
文件:/frameworks/native/services/surfaceflinger/RenderEngine/RenderEngine.cpp
void RenderEngine::bindExternalTextureImage(uint32_t texName, const android::RE::Image& image) {
return bindExternalTextureImage(texName, static_cast(image));
}
void RenderEngine::bindExternalTextureImage(uint32_t texName,
const android::RE::impl::Image& image) {
const GLenum target = GL_TEXTURE_EXTERNAL_OES;
glBindTexture(target, texName);
if (image.getEGLImage() != EGL_NO_IMAGE_KHR) {
glEGLImageTargetTexture2DOES(target, static_cast(image.getEGLImage()));
}
}
还记得我在OpenGL es上的封装一文中和大家聊到的OpenGL es的优化吗?实际上glEGLImageTargetTexture2DOES设置的EGLImage对象本质上就是我们GraphicBuffer对象。之后操作就以GraphicBuffer为纹理蓝本进行效果绘制。。
setFilteringEnabled 计算变换矩阵
void BufferLayerConsumer::setFilteringEnabled(bool enabled) {
Mutex::Autolock lock(mMutex);
...
bool needsRecompute = mFilteringEnabled != enabled;
mFilteringEnabled = enabled;
....
if (needsRecompute && mCurrentTextureImage != nullptr) {
computeCurrentTransformMatrixLocked();
}
}
void BufferLayerConsumer::computeCurrentTransformMatrixLocked() {
sp buf =
(mCurrentTextureImage == nullptr) ? nullptr : mCurrentTextureImage->graphicBuffer();
const Rect& cropRect = canUseImageCrop(mCurrentCrop) ? Rect::EMPTY_RECT : mCurrentCrop;
GLConsumer::computeTransformMatrix(mCurrentTransformMatrix, buf, cropRect, mCurrentTransform,
mFilteringEnabled);
}
一般情况下,标志位isFixSize,getFilter,needsFiltering都是false.因此会走到computeTransformMatrix中进行变换举证的处理,能看到这里有之前计算invalidate步骤中得到mCurrentTransform,这个mCurrentTransform实际上是一个flag。
GLConsumer computeTransformMatrix
void GLConsumer::computeTransformMatrix(float outTransform[16],
const sp& buf, const Rect& cropRect, uint32_t transform,
bool filtering) {
static const mat4 mtxFlipH(
-1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
1, 0, 0, 1
);
static const mat4 mtxFlipV(
1, 0, 0, 0,
0, -1, 0, 0,
0, 0, 1, 0,
0, 1, 0, 1
);
static const mat4 mtxRot90(
0, 1, 0, 0,
-1, 0, 0, 0,
0, 0, 1, 0,
1, 0, 0, 1
);
mat4 xform;
if (transform & NATIVE_WINDOW_TRANSFORM_FLIP_H) {
xform *= mtxFlipH;
}
if (transform & NATIVE_WINDOW_TRANSFORM_FLIP_V) {
xform *= mtxFlipV;
}
if (transform & NATIVE_WINDOW_TRANSFORM_ROT_90) {
xform *= mtxRot90;
}
if (!cropRect.isEmpty()) {
float tx = 0.0f, ty = 0.0f, sx = 1.0f, sy = 1.0f;
float bufferWidth = buf->getWidth();
float bufferHeight = buf->getHeight();
float shrinkAmount = 0.0f;
if (filtering) {
switch (buf->getPixelFormat()) {
case PIXEL_FORMAT_RGBA_8888:
case PIXEL_FORMAT_RGBX_8888:
case PIXEL_FORMAT_RGBA_FP16:
case PIXEL_FORMAT_RGBA_1010102:
case PIXEL_FORMAT_RGB_888:
case PIXEL_FORMAT_RGB_565:
case PIXEL_FORMAT_BGRA_8888:
shrinkAmount = 0.5;
break;
default:
// If we don't recognize the format, we must assume the
// worst case (that we care about), which is YUV420.
shrinkAmount = 1.0;
break;
}
}
if (cropRect.width() < bufferWidth) {
tx = (float(cropRect.left) + shrinkAmount) / bufferWidth;
sx = (float(cropRect.width()) - (2.0f * shrinkAmount)) /
bufferWidth;
}
if (cropRect.height() < bufferHeight) {
ty = (float(bufferHeight - cropRect.bottom) + shrinkAmount) /
bufferHeight;
sy = (float(cropRect.height()) - (2.0f * shrinkAmount)) /
bufferHeight;
}
mat4 crop(
sx, 0, 0, 0,
0, sy, 0, 0,
0, 0, 1, 0,
tx, ty, 0, 1
);
xform = crop * xform;
}
// SurfaceFlinger expects the top of its window textures to be at a Y
// coordinate of 0, so GLConsumer must behave the same way. We don't
// want to expose this to applications, however, so we must add an
// additional vertical flip to the transform after all the other transforms.
xform = mtxFlipV * xform;
memcpy(outTransform, xform.asArray(), sizeof(xform));
}
在这里面涉及到了一些矩阵计算,原理不多介绍,推导过程,我已经写过了,就在OpenGL(四)坐标以及OpenGL(三)矩阵的基本使用
首先看头三个矩阵,十分简单。
static const mat4 mtxFlipH(
-1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
1, 0, 0, 1
);
static const mat4 mtxFlipV(
1, 0, 0, 0,
0, -1, 0, 0,
0, 0, 1, 0,
0, 1, 0, 1
);
static const mat4 mtxRot90(
0, 1, 0, 0,
-1, 0, 0, 0,
0, 0, 1, 0,
1, 0, 0, 1
);
第一个矩阵,象征x轴的缩放向量从1变成了-1,也就说进行了水平翻转。同理mtxFlipV,就是指y轴上的水平翻转。mtxRot90 则是进行了绕着z轴一次90度的翻转。他们会根据Surface中设置得到flag进行一些简单的处理。
if (filtering) {
switch (buf->getPixelFormat()) {
case PIXEL_FORMAT_RGBA_8888:
case PIXEL_FORMAT_RGBX_8888:
case PIXEL_FORMAT_RGBA_FP16:
case PIXEL_FORMAT_RGBA_1010102:
case PIXEL_FORMAT_RGB_888:
case PIXEL_FORMAT_RGB_565:
case PIXEL_FORMAT_BGRA_8888:
shrinkAmount = 0.5;
break;
default:
shrinkAmount = 1.0;
break;
}
}
if (cropRect.width() < bufferWidth) {
tx = (float(cropRect.left) + shrinkAmount) / bufferWidth;
sx = (float(cropRect.width()) - (2.0f * shrinkAmount)) /
bufferWidth;
}
if (cropRect.height() < bufferHeight) {
ty = (float(bufferHeight - cropRect.bottom) + shrinkAmount) /
bufferHeight;
sy = (float(cropRect.height()) - (2.0f * shrinkAmount)) /
bufferHeight;
}
mat4 crop(
sx, 0, 0, 0,
0, sy, 0, 0,
0, 0, 1, 0,
tx, ty, 0, 1
);
xform = crop * xform;
解析来,再来看看下一段,如果裁剪区域比图元小。此时会在原来的变换矩阵上计算,sx是代表x轴上的缩放,sy代表y轴上的缩放,tx,ty则会影响平移位置。
缩放遵循如下公式:
当为RGBA时候:(裁剪区域宽度 - (2 * 0.5)) / 图元宽度
(裁剪区域高度 - (2 * 0.5)) / 图元高度
当为非RGBA(一般为YUV420)时候:(裁剪区域宽度 - (2 * 1)) / 图元宽度
(裁剪区域高度 - (2 * 1)) / 图元高度
BufferLayer drawWithOpenGL 绘制合成OpenGL es中的参数
void BufferLayer::drawWithOpenGL(const RenderArea& renderArea, bool useIdentityTransform) const {
ATRACE_CALL();
const State& s(getDrawingState());
computeGeometry(renderArea, getBE().mMesh, useIdentityTransform);
const Rect bounds{computeBounds()}; // Rounds from FloatRect
Transform t = getTransform();
Rect win = bounds;
if (!s.finalCrop.isEmpty()) {
win = t.transform(win);
if (!win.intersect(s.finalCrop, &win)) {
win.clear();
}
win = t.inverse().transform(win);
if (!win.intersect(bounds, &win)) {
win.clear();
}
}
float left = float(win.left) / float(s.active.w);
float top = float(win.top) / float(s.active.h);
float right = float(win.right) / float(s.active.w);
float bottom = float(win.bottom) / float(s.active.h);
// TODO: we probably want to generate the texture coords with the mesh
// here we assume that we only have 4 vertices
Mesh::VertexArray texCoords(getBE().mMesh.getTexCoordArray());
texCoords[0] = vec2(left, 1.0f - top);
texCoords[1] = vec2(left, 1.0f - bottom);
texCoords[2] = vec2(right, 1.0f - bottom);
texCoords[3] = vec2(right, 1.0f - top);
auto& engine(mFlinger->getRenderEngine());
engine.setupLayerBlending(mPremultipliedAlpha, isOpaque(s), false /* disableTexture */,
getColor());
engine.setSourceDataSpace(mCurrentDataSpace);
if (isHdrY410()) {
engine.setSourceY410BT2020(true);
}
engine.drawMesh(getBE().mMesh);
engine.disableBlending();
engine.setSourceY410BT2020(false);
}
这里面的核心思想,可以阅读我之前写的OpenGL 纹理基础与索引,其实就是设置了纹理坐标,纹理之间的混合模式,颜色空间。
由于纹理坐标都是在[-1,1]之间,因此需要把活跃范围active和GraphicBuffer进行等比压缩,把它归一化到一个区间。最后设置到RenderEngine。
最后调用drawMesh 合并OpenGL es的渲染参数。
RenderEngine drawMesh
void GLES20RenderEngine::drawMesh(const Mesh& mesh) {
ATRACE_CALL();
if (mesh.getTexCoordsSize()) {
glEnableVertexAttribArray(Program::texCoords);
glVertexAttribPointer(Program::texCoords, mesh.getTexCoordsSize(), GL_FLOAT, GL_FALSE,
mesh.getByteStride(), mesh.getTexCoords());
}
glVertexAttribPointer(Program::position, mesh.getVertexSize(), GL_FLOAT, GL_FALSE,
mesh.getByteStride(), mesh.getPositions());
//处理DataSpace
...
ProgramCache::getInstance().useProgram(wideColorState);
glDrawArrays(mesh.getPrimitive(), 0, mesh.getVertexCount());
...
} else {
ProgramCache::getInstance().useProgram(mState);
glDrawArrays(mesh.getPrimitive(), 0, mesh.getVertexCount());
}
if (mesh.getTexCoordsSize()) {
glDisableVertexAttribArray(Program::texCoords);
}
}
这里就是我们十分熟悉的OpenGL es的绘制循环步骤。
- 1.glVertexAttribPointer 告诉OpenGL es改怎么解析顶点
- 2.ProgramCache::getInstance().useProgram(wideColorState); 调用着色器程序。
- 3.glDrawArrays 合成OpenGL es中所有参数,绘制在在之前通过EGLImage保存进来的GraphicBuffer
这里面的核心原理我已经在我写的OpenGL es上的封装(下)
的软件模拟OpenGL es渲染流程中已经解析了。
DisplayDevice swapBuffers
当我们完成了OpenGL es的绘制,将会调用DisplayDevice swapBuffers 进行OpenGL es中缓冲区的交换,发送到消费端消费。
文件:/frameworks/native/services/surfaceflinger/DisplayDevice.cpp
void DisplayDevice::swapBuffers(HWComposer& hwc) const {
if (hwc.hasClientComposition(mHwcDisplayId) || hwc.hasFlipClientTargetRequest(mHwcDisplayId)) {
mSurface->swapBuffers();
}
status_t result = mDisplaySurface->advanceFrame();
}
由于DisplayDevice管理两个Surface,一个RE::Surface以及FrameBufferSurface。
RE::Surface实际上就是上文bindTexture步骤,OpenGL es绘制的承载体。
- 1.如果发现需要进行Client模式渲染,则会调用RE::Surface的swapBuffers
- 2.FrameBufferSurface advanceFrame 获取下一个需要消费图元。
我们需要探索他们之间的关系,我们需要退回我写的第一篇文章SurfaceFlinger 的初始化。
先看看第一个片段,processDisplayChangesLocked:
sp dispSurface;
sp producer;
sp bqProducer;
sp bqConsumer;
mCreateBufferQueue(&bqProducer, &bqConsumer, false);
...
dispSurface = new FramebufferSurface(*getBE().mHwc, hwcId, bqConsumer);
FramebufferSurface在底层持有一个IGraphicBufferConsumer,一个图元消费者。说明这个FramebufferSurface和我们常说的Surface不一样。我们客户端的Surface一般作为生产端获取生产图元推入SF中,而这里面FramebufferSurface将会进行图元的消费。
再来看看第二个片段,setupNewDisplayDeviceInternal:
auto nativeWindowSurface = mCreateNativeWindowSurface(producer);
auto nativeWindow = nativeWindowSurface->getNativeWindow();
...
std::unique_ptr renderSurface = getRenderEngine().createSurface();
renderSurface->setCritical(state.type == DisplayDevice::DISPLAY_PRIMARY);
renderSurface->setAsync(state.type >= DisplayDevice::DISPLAY_VIRTUAL);
renderSurface->setNativeWindow(nativeWindow.get());
这里面可以得知在生成RE::Surface时候会通过IGraphicBufferProducer生成一个openGL es对应的egl_surface_v2_t结构体。他就是OpenGL es中进行承载图元绘制结果的对象。
结合我写的一篇OpenGL es上的封装(上),就能得知,一次swapbuffer其实就是把其中的IGraphicBufferProducer重复上面几篇文章的图元一直到queue的过程。
有了这个基础之后,我们来看看mDisplaySurface->advanceFrame方法。
FramebufferSurface advanceFrame
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp
status_t FramebufferSurface::advanceFrame() {
uint32_t slot = 0;
sp buf;
sp acquireFence(Fence::NO_FENCE);
Dataspace dataspace = Dataspace::UNKNOWN;
status_t result = nextBuffer(slot, buf, acquireFence, dataspace);
mDataSpace = dataspace;
...
return result;
}
status_t FramebufferSurface::nextBuffer(uint32_t& outSlot,
sp& outBuffer, sp& outFence,
Dataspace& outDataspace) {
Mutex::Autolock lock(mMutex);
BufferItem item;
status_t err = acquireBufferLocked(&item, 0);
if (err == BufferQueue::NO_BUFFER_AVAILABLE) {
mHwcBufferCache.getHwcBuffer(mCurrentBufferSlot, mCurrentBuffer,
&outSlot, &outBuffer);
return NO_ERROR;
} else if (err != NO_ERROR) {
...
return err;
}
if (mCurrentBufferSlot != BufferQueue::INVALID_BUFFER_SLOT &&
item.mSlot != mCurrentBufferSlot) {
mHasPendingRelease = true;
mPreviousBufferSlot = mCurrentBufferSlot;
mPreviousBuffer = mCurrentBuffer;
}
mCurrentBufferSlot = item.mSlot;
mCurrentBuffer = mSlots[mCurrentBufferSlot].mGraphicBuffer;
mCurrentFence = item.mFence;
outFence = item.mFence;
mHwcBufferCache.getHwcBuffer(mCurrentBufferSlot, mCurrentBuffer,
&outSlot, &outBuffer);
outDataspace = static_cast(item.mDataSpace);
status_t result =
mHwc.setClientTarget(mDisplayType, outSlot, outFence, outBuffer, outDataspace);
...
return NO_ERROR;
}
这里面的逻辑就不多介绍,我之前写的图元消费几乎一样的逻辑。经过acquireBufferLocked步骤获取了OpenGL es此时绘制合成完毕的图元,需要显示到屏幕的GraphicBuffer。
SF postFramebuffer
void SurfaceFlinger::postFramebuffer()
{
const nsecs_t now = systemTime();
mDebugInSwapBuffers = now;
for (size_t displayId = 0; displayId < mDisplays.size(); ++displayId) {
auto& displayDevice = mDisplays[displayId];
if (!displayDevice->isDisplayOn()) {
continue;
}
const auto hwcId = displayDevice->getHwcDisplayId();
if (hwcId >= 0) {
getBE().mHwc->presentAndGetReleaseFences(hwcId);
}
displayDevice->onSwapBuffersCompleted();
displayDevice->makeCurrent();
for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) {
auto hwcLayer = layer->getHwcLayer(hwcId);
sp releaseFence = getBE().mHwc->getLayerReleaseFence(hwcId, hwcLayer);
if (layer->getCompositionType(hwcId) == HWC2::Composition::Client) {
releaseFence = Fence::merge("LayerRelease", releaseFence,
displayDevice->getClientTargetAcquireFence());
}
layer->onLayerDisplayed(releaseFence);
}
if (!displayDevice->getLayersNeedingFences().isEmpty()) {
sp presentFence = getBE().mHwc->getPresentFence(hwcId);
for (auto& layer : displayDevice->getLayersNeedingFences()) {
layer->onLayerDisplayed(presentFence);
}
}
if (hwcId >= 0) {
getBE().mHwc->clearReleaseFences(hwcId);
}
}
mLastSwapBufferTime = systemTime() - now;
mDebugInSwapBuffers = 0;
if (getBE().mHwc->isConnected(HWC_DISPLAY_PRIMARY)) {
uint32_t flipCount = getDefaultDisplayDeviceLocked()->getPageFlipCount();
if (flipCount % LOG_FRAME_STATS_PERIOD == 0) {
logFrameStats();
}
}
}
- 1.presentAndGetReleaseFences 统一通过HWC的绘制到屏幕
- 2.onSwapBuffersCompleted 释放当前的GraphicBuffer,让它回到Free状态。
- 3.onLayerDisplayed 设置释放状态的Fence。
还记得因为我们无论怎么绘制也好,在HWC的Hal层中,硬件层中,OpenGL es中其实持有的都是通过buffer_handle句柄的GraphicBuffer,换句话说无论三方中那一方对保存在自己缓存中的GraphicBuffer进行修改,也是修改ion中同一段内存。所以,SF才能统一通过HWC渲染到屏幕上。
我们主要关注前两个核心的方法。
HWC presentAndGetReleaseFences
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
status_t HWComposer::presentAndGetReleaseFences(int32_t displayId) {
ATRACE_CALL();
RETURN_IF_INVALID_DISPLAY(displayId, BAD_INDEX);
auto& displayData = mDisplayData[displayId];
auto& hwcDisplay = displayData.hwcDisplay;
...
auto error = hwcDisplay->present(&displayData.lastPresentFence);
std::unordered_map> releaseFences;
error = hwcDisplay->getReleaseFences(&releaseFences);
displayData.releaseFences = std::move(releaseFences);
return NO_ERROR;
}
- 1.调用Hal层的present方法,进行渲染
- 2.getReleaseFences从Hal层中获取释放的Fence
我们直接看ComposerHal中的presentDisplay
Error Composer::presentDisplay(Display display, int* outPresentFence)
{
mWriter.selectDisplay(display);
mWriter.presentDisplay();
Error error = execute();
if (error != Error::NONE) {
return error;
}
mReader.takePresentFence(display, outPresentFence);
return Error::NONE;
}
其实这里还是使用上一篇文章中的ComposeCommandEngine方式给HWC下命令把数据渲染到fb驱动中。
接下来就不继续赘述其中的流程,我们直接看核心代码HWC2On1Adapter::Display::present。
HWC2On1Adapter::Display::present
文件:/hardware/interfaces/graphics/composer/2.1/utils/hwc2on1adapter/HWC2On1Adapter.cpp
Error HWC2On1Adapter::Display::present(int32_t* outRetireFence) {
std::unique_lock lock(mStateMutex);
if (mChanges) {
Error error = mDevice.setAllDisplays();
if (error != Error::None) {
return error;
}
}
*outRetireFence = mRetireFence.get()->dup();
return Error::None;
}
核心是调用setAllDisplays,发送每一个Displays上的图元,dup则是进行fence的等待。
HWC2On1Adapter::setAllDisplays
Error HWC2On1Adapter::setAllDisplays() {
ATRACE_CALL();
std::unique_lock lock(mStateMutex);
// Make sure we're ready to validate
for (size_t hwc1Id = 0; hwc1Id < mHwc1Contents.size(); ++hwc1Id) {
if (mHwc1Contents[hwc1Id] == nullptr) {
continue;
}
auto displayId = mHwc1DisplayMap[hwc1Id];
auto& display = mDisplays[displayId];
Error error = display->set(*mHwc1Contents[hwc1Id]);
if (error != Error::None) {
return error;
}
}
{
mHwc1Device->set(mHwc1Device, mHwc1Contents.size(),
mHwc1Contents.data());
}
// Add retire and release fences
for (size_t hwc1Id = 0; hwc1Id < mHwc1Contents.size(); ++hwc1Id) {
if (mHwc1Contents[hwc1Id] == nullptr) {
continue;
}
auto displayId = mHwc1DisplayMap[hwc1Id];
auto& display = mDisplays[displayId];
auto retireFenceFd = mHwc1Contents[hwc1Id]->retireFenceFd;
display->addRetireFence(mHwc1Contents[hwc1Id]->retireFenceFd);
display->addReleaseFences(*mHwc1Contents[hwc1Id]);
}
return Error::None;
}
- 1.HWC2On1Adapter::Display::set 设置渲染Target
- 2.hw_device_t 设备的set方法
-
- display 记录释放的fence。
我们直接看msm8960中set对应的方法。
硬件发送图像到fb驱动
文件/hardware/qcom/display/msm8960/libhwcomposer/hwc.cpp
static int hwc_set(hwc_composer_device_1 *dev,
size_t numDisplays,
hwc_display_contents_1_t** displays)
{
int ret = 0;
hwc_context_t* ctx = (hwc_context_t*)(dev);
Locker::Autolock _l(ctx->mBlankLock);
for (uint32_t i = 0; i < numDisplays; i++) {
hwc_display_contents_1_t* list = displays[i];
switch(i) {
case HWC_DISPLAY_PRIMARY:
ret = hwc_set_primary(ctx, list);
break;
case HWC_DISPLAY_EXTERNAL:
ret = hwc_set_external(ctx, list, i);
break;
case HWC_DISPLAY_VIRTUAL:
ret = hwc_set_virtual(ctx, list, i);
break;
default:
ret = -EINVAL;
}
}
CALC_FPS();
MDPComp::resetIdleFallBack();
ctx->mVideoTransFlag = false;
return ret;
}
这里照样的处理三种屏幕对应的渲染方法,我们直接关注hwc_set_primary。
tatic int hwc_set_primary(hwc_context_t *ctx, hwc_display_contents_1_t* list) {
ATRACE_CALL();
int ret = 0;
const int dpy = HWC_DISPLAY_PRIMARY;
if (LIKELY(list) && ctx->dpyAttr[dpy].isActive) {
uint32_t last = list->numHwLayers - 1;
hwc_layer_1_t *fbLayer = &list->hwLayers[last];
int fd = -1;
bool copybitDone = false;
if(ctx->mCopyBit[dpy])
copybitDone = ctx->mCopyBit[dpy]->draw(ctx, list, dpy, &fd);
if(list->numHwLayers > 1)
hwc_sync(ctx, list, dpy, fd);
if (!ctx->mMDPComp[dpy]->draw(ctx, list)) {
ret = -1;
}
private_handle_t *hnd = (private_handle_t *)fbLayer->handle;
if(copybitDone) {
hnd = ctx->mCopyBit[dpy]->getCurrentRenderBuffer();
}
if(hnd) {
if (!ctx->mFBUpdate[dpy]->draw(ctx, hnd)) {
ret = -1;
}
}
if (display_commit(ctx, dpy) < 0) {
return -1;
}
}
closeAcquireFds(list);
return ret;
}
让我们回忆一下hwc在prepare中做了什么。就清楚实际上这里面都做了什么事情,由于在MDP中会找到需要自己处理的Layer,把另一部分Layer交给FBUpdate中进行完成。
因此会有2个步骤:
- 1.mCopyBit 进行draw
- 2.hwc_sync
- 3.mMDPComp对应屏幕的MDPComp对象调用draw
- 4.mFBUpdate对应屏幕的FBUpdate调用draw
- 5.display_commit 提交所有的渲染
在prepare中,mCopyBit相关的数据,在msm8960并没有经过prepare处理,我们先不去关注它。
hwc_sync
int hwc_sync(hwc_context_t *ctx, hwc_display_contents_1_t* list, int dpy,
int fd) {
int ret = 0;
int acquireFd[MAX_NUM_APP_LAYERS];
int count = 0;
int releaseFd = -1;
int retireFd = -1;
int fbFd = -1;
bool swapzero = false;
int mdpVersion = qdutils::MDPVersion::getInstance().getMDPVersion();
struct mdp_buf_sync data;
memset(&data, 0, sizeof(data));
//Until B-family supports sync for rotator
if(mdpVersion >= qdutils::MDSS_V5) {
data.flags = MDP_BUF_SYNC_FLAG_WAIT;
}
data.acq_fen_fd = acquireFd;
data.rel_fen_fd = &releaseFd;
data.retire_fen_fd = &retireFd;
...
#ifndef MDSS_TARGET
if(mdpVersion < qdutils::MDSS_V5) {
//A-family
int rotFd = ctx->mRotMgr->getRotDevFd();
struct msm_rotator_buf_sync rotData;
for(uint32_t i = 0; i < ctx->mLayerRotMap[dpy]->getCount(); i++) {
memset(&rotData, 0, sizeof(rotData));
int& acquireFenceFd =
ctx->mLayerRotMap[dpy]->getLayer(i)->acquireFenceFd;
rotData.acq_fen_fd = acquireFenceFd;
rotData.session_id = ctx->mLayerRotMap[dpy]->getRot(i)->getSessId();
ioctl(rotFd, MSM_ROTATOR_IOCTL_BUFFER_SYNC, &rotData);
close(acquireFenceFd);
acquireFenceFd = dup(rotData.rel_fen_fd);
ctx->mLayerRotMap[dpy]->getLayer(i)->releaseFenceFd =
rotData.rel_fen_fd;
}
} else {
//TODO B-family
}
#endif
for(uint32_t i = 0; i < list->numHwLayers; i++) {
if(list->hwLayers[i].compositionType == HWC_OVERLAY &&
list->hwLayers[i].acquireFenceFd >= 0) {
if(UNLIKELY(swapzero))
acquireFd[count++] = -1;
else
acquireFd[count++] = list->hwLayers[i].acquireFenceFd;
}
if(list->hwLayers[i].compositionType == HWC_FRAMEBUFFER_TARGET) {
if(UNLIKELY(swapzero))
acquireFd[count++] = -1;
else if(fd >= 0) {
acquireFd[count++] = fd;
data.flags &= ~MDP_BUF_SYNC_FLAG_WAIT;
} else if(list->hwLayers[i].acquireFenceFd >= 0)
acquireFd[count++] = list->hwLayers[i].acquireFenceFd;
}
}
data.acq_fen_fd_cnt = count;
fbFd = ctx->dpyAttr[dpy].fd;
//Waits for acquire fences, returns a release fence
if(LIKELY(!swapzero)) {
uint64_t start = systemTime();
ret = ioctl(fbFd, MSMFB_BUFFER_SYNC, &data);
}
if(ret < 0) {
}
for(uint32_t i = 0; i < list->numHwLayers; i++) {
if(list->hwLayers[i].compositionType == HWC_OVERLAY ||
list->hwLayers[i].compositionType == HWC_FRAMEBUFFER_TARGET) {
if(UNLIKELY(swapzero)) {
list->hwLayers[i].releaseFenceFd = -1;
} else if(list->hwLayers[i].releaseFenceFd < 0) {
list->hwLayers[i].releaseFenceFd = dup(releaseFd);
}
}
}
if(fd >= 0) {
close(fd);
fd = -1;
}
if (ctx->mCopyBit[dpy])
ctx->mCopyBit[dpy]->setReleaseFd(releaseFd);
//A-family
if(mdpVersion < qdutils::MDSS_V5) {
ctx->mLayerRotMap[dpy]->setReleaseFd(releaseFd);
}
close(releaseFd);
if(UNLIKELY(swapzero))
list->retireFenceFd = -1;
else
list->retireFenceFd = retireFd;
return ret;
}
如果编译模式打开了MDSS_TARGET标志位。MDP低版本此时还没有旋转等功能,会把这部分任务交给msm_rotator驱动完成。发送MSM_ROTATOR_IOCTL_BUFFER_SYNC一个命令让驱动进行同步。
接着会发送MSMFB_BUFFER_SYNC命令到fb驱动,也进行同步操作。
MDPCompLowRes draw
bool MDPCompLowRes::draw(hwc_context_t *ctx, hwc_display_contents_1_t* list) {
...
/* reset Invalidator */
if(idleInvalidator && !sIdleFallBack && mCurrentFrame.mdpCount)
idleInvalidator->markForSleep();
overlay::Overlay& ov = *ctx->mOverlay;
LayerProp *layerProp = ctx->layerProp[mDpy];
int numHwLayers = ctx->listStats[mDpy].numAppLayers;
for(int i = 0; i < numHwLayers && mCurrentFrame.mdpCount; i++ )
{
if(mCurrentFrame.isFBComposed[i]) continue;
hwc_layer_1_t *layer = &list->hwLayers[i];
private_handle_t *hnd = (private_handle_t *)layer->handle;
if(!hnd) {
return false;
}
int mdpIndex = mCurrentFrame.layerToMDP[i];
MdpPipeInfoLowRes& pipe_info =
*(MdpPipeInfoLowRes*)mCurrentFrame.mdpToLayer[mdpIndex].pipeInfo;
ovutils::eDest dest = pipe_info.index;
if(dest == ovutils::OV_INVALID) {
return false;
}
if(!(layerProp[i].mFlags & HWC_MDPCOMP)) {
continue;
}
int fd = hnd->fd;
uint32_t offset = hnd->offset;
Rotator *rot = mCurrentFrame.mdpToLayer[mdpIndex].rot;
if(rot) {
if(!rot->queueBuffer(fd, offset))
return false;
fd = rot->getDstMemId();
offset = rot->getDstOffset();
}
if (!ov.queueBuffer(fd, offset, dest)) {
return false;
}
layerProp[i].mFlags &= ~HWC_MDPCOMP;
}
return true;
}
核心只有一个调用OverLayer和Rotator的queueBuffer方法,把图元对应的fd句柄返回到交给OverLayer进一步开始消费。
最后会调用到如下方法:
文件:/hardware/qcom/display/msm8960/liboverlay/mdpWrapper.h
inline bool play(int fd, msmfb_overlay_data& od) {
if (ioctl(fd, MSMFB_OVERLAY_PLAY, &od) < 0) {
return false;
}
return true;
}
最后通过ioctl 发送MSMFB_OVERLAY_PLAY对fb通信,渲染fd句柄对应的ion中的内存数据。
FBUpdateLowRes::draw
bool FBUpdateLowRes::draw(hwc_context_t *ctx, private_handle_t *hnd)
{
if(!mModeOn) {
return true;
}
bool ret = true;
overlay::Overlay& ov = *(ctx->mOverlay);
ovutils::eDest dest = mDest;
if (!ov.queueBuffer(hnd->fd, hnd->offset, dest)) {
ret = false;
}
return ret;
}
这里的逻辑和MDP都是一样的,通过Overlay调用queueBuffer方法,而向fb发送MSMFB_OVERLAY_PLAY命令,把数据保存到fb驱动。
display_commit
static int display_commit(hwc_context_t *ctx, int dpy) {
int fbFd = ctx->dpyAttr[dpy].fd;
if(fbFd == -1) {
ALOGE("%s: Invalid FB fd for display: %d", __FUNCTION__, dpy);
return -1;
}
struct mdp_display_commit commit_info;
memset(&commit_info, 0, sizeof(struct mdp_display_commit));
commit_info.flags = MDP_DISPLAY_COMMIT_OVERLAY;
if(ioctl(fbFd, MSMFB_DISPLAY_COMMIT, &commit_info) == -1) {
return -errno;
}
return 0;
}
最后通过MSMFB_DISPLAY_COMMIT 提交所有的图元到fb驱动中渲染。fb驱动会拿到LCD屏幕驱动中的一块内存,把ion对应的内存数据拷贝上去,最后完成LCD屏幕的渲染。
postComposition 处理合成图元后的工作
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::postComposition(nsecs_t refreshStartTime)
{
// Release any buffers which were replaced this frame
nsecs_t dequeueReadyTime = systemTime();
for (auto& layer : mLayersWithQueuedFrames) {
layer->releasePendingBuffer(dequeueReadyTime);
}
// |mStateLock| not needed as we are on the main thread
const sp hw(getDefaultDisplayDeviceLocked());
getBE().mGlCompositionDoneTimeline.updateSignalTimes();
std::shared_ptr glCompositionDoneFenceTime;
if (hw && getBE().mHwc->hasClientComposition(HWC_DISPLAY_PRIMARY)) {
glCompositionDoneFenceTime =
std::make_shared(hw->getClientTargetAcquireFence());
getBE().mGlCompositionDoneTimeline.push(glCompositionDoneFenceTime);
} else {
glCompositionDoneFenceTime = FenceTime::NO_FENCE;
}
getBE().mDisplayTimeline.updateSignalTimes();
sp presentFence = getBE().mHwc->getPresentFence(HWC_DISPLAY_PRIMARY);
auto presentFenceTime = std::make_shared(presentFence);
getBE().mDisplayTimeline.push(presentFenceTime);
nsecs_t vsyncPhase = mPrimaryDispSync.computeNextRefresh(0);
nsecs_t vsyncInterval = mPrimaryDispSync.getPeriod();
updateCompositorTiming(
vsyncPhase, vsyncInterval, refreshStartTime, presentFenceTime);
CompositorTiming compositorTiming;
{
std::lock_guard lock(getBE().mCompositorTimingLock);
compositorTiming = getBE().mCompositorTiming;
}
mDrawingState.traverseInZOrder([&](Layer* layer) {
bool frameLatched = layer->onPostComposition(glCompositionDoneFenceTime,
presentFenceTime, compositorTiming);
if (frameLatched) {
recordBufferingStats(layer->getName().string(),
layer->getOccupancyHistory(false));
}
});
if (presentFenceTime->isValid()) {
if (mPrimaryDispSync.addPresentFence(presentFenceTime)) {
enableHardwareVsync();
} else {
disableHardwareVsync(false);
}
}
if (!hasSyncFramework) {
if (getBE().mHwc->isConnected(HWC_DISPLAY_PRIMARY) && hw->isDisplayOn()) {
enableHardwareVsync();
}
}
if (mAnimCompositionPending) {
mAnimCompositionPending = false;
if (presentFenceTime->isValid()) {
mAnimFrameTracker.setActualPresentFence(
std::move(presentFenceTime));
} else if (getBE().mHwc->isConnected(HWC_DISPLAY_PRIMARY)) {
// The HWC doesn't support present fences, so use the refresh
// timestamp instead.
nsecs_t presentTime =
getBE().mHwc->getRefreshTimestamp(HWC_DISPLAY_PRIMARY);
mAnimFrameTracker.setActualPresentTime(presentTime);
}
mAnimFrameTracker.advanceFrame();
}
mTimeStats.incrementTotalFrames();
if (mHadClientComposition) {
mTimeStats.incrementClientCompositionFrames();
}
if (getBE().mHwc->isConnected(HWC_DISPLAY_PRIMARY) &&
hw->getPowerMode() == HWC_POWER_MODE_OFF) {
return;
}
nsecs_t currentTime = systemTime();
if (mHasPoweredOff) {
mHasPoweredOff = false;
} else {
nsecs_t elapsedTime = currentTime - getBE().mLastSwapTime;
size_t numPeriods = static_cast(elapsedTime / vsyncInterval);
if (numPeriods < SurfaceFlingerBE::NUM_BUCKETS - 1) {
getBE().mFrameBuckets[numPeriods] += elapsedTime;
} else {
getBE().mFrameBuckets[SurfaceFlingerBE::NUM_BUCKETS - 1] += elapsedTime;
}
getBE().mTotalTime += elapsedTime;
}
getBE().mLastSwapTime = currentTime;
}
在这里主要记录每一次刷新完屏幕后,记录当前的时间在Timeline,同时更新计算mPrimaryDispSync中的时间。
详细的后面的文章我们再进行详谈。
总结
到这里,我就把整个图元的消费到合成,到硬件的渲染大体都过了一遍,如果对fb驱动具体的技术细节感兴趣,可以去看老罗的。虽然不是最新的,但是也代表经典的设计,我就暂时不去解析fb驱动中做了什么了,如果以后有机会我会解析fb驱动其中的设计。
老规矩,我们把整个流程从图元消费到渲染全部复习一遍,并且用图来表达出来。下面这幅图是我尽可能的精简得出的结果。

我把整个流程从消费到合成,我分成三个步骤:
判断是否需要SF是否需要刷新屏幕
- 1.handleMessageTransaction将会处理每一个Layer的事务,最核心的事情就是把每一个Layer中的上一帧的mDrawState被当前帧的mCurrentState替代。一旦有事务需要处理,说明有Surface发生了状态的变化,如宽高如位置。此时就必须重新刷新整个界面。
- 2.handleMessageInvalidate处理的核心:
- 首先检测哪一些图元需要显示,需要的则会添加到mLayersWithQueuedFrames。条件是入队时间不能超过预期时间的一秒,也能不能超过预期时间(mQueueItems是onFrameAvailable回调添加)。
- 遍历每一个需要显示的Layer,调用latchBuffer方法。这个方法核心是updateTexImage。这个方法分为3个步骤:
acquireBufferLocked 本质上是获取mQueue的第一个加进来的图元作为即将显示的图元。但是如果遇到显示的时间和预期时间差大于1秒,同时发现这个图元已经过期了(free状态),则会跳帧,直到找到最近时间的一帧。
LayerRejecter 判断是否有打开冻结窗口模式,打开了但是发现图元的大小不对则拒绝显示。相反,则会mDrawState的requested赋值给active。
updateAndReleaseLocked 释放前一帧的图元,同时准备设置当前消费的图元作为准备绘制的画面。
SF 绘制的准备流程
- 1.preComposition 通知需要绘制的图元解开mLocalSyncPoints阻塞。
-
- rebuildLayerStacks 如果发现有Layer添加或者有新的图元进入了SF。则会重新遍历一遍可视的Layer栈,重新计算可视区域,遮罩区域,透明区域,非透明区域。
-
- setUpHWComposer 准备HWComposer的Hal层以及控制硬件行为的lib层。主要的工作为4点:
遍历每一个DisplayDevice调用beginFrame方法,准备绘制图元。
遍历每一个DisplayDevice先判断他的色彩空间。并且设置颜色矩阵。接着获取DisplayDevice中需要绘制的Layer,检查是否创建了hwcLayer,没有则创建,创建失败则设置forceClientComposition,强制设置为Client渲染模式,进行OpenGL es渲染。最后调用setGeometry。
遍历每一个DisplayDevice,根据DataSpace,进一步处理是否需要强制使用Client渲染模式,最后调用layer的setPerFrameData方法。setPerFrameData最终会用到Hal层的setBuffer,把图元句柄保存在对应的hw_layer_t中。
遍历每一个DisplayDevice,调用prepareFrame。准备所有屏幕对应的hwc的设备hw_device_t。在这个过程中为FBUpdate和MDPComp两个对象从PipeBook申请一段合适type的管道空间,承载接下来需要渲染的参数。
SF的图元合成
-
- doComposition 主要的工作实际上就是判断到是OpenGL es渲染模式,最会调用每一个Layer的onDraw方法。每一个Layer都会通过RenderEngine进行常规OpenGL es绘制,最后通过swapBuffers 把图元从RE::Surface推到FramebufferSurface中消费。最后缓存下来当前需要绘制的图元,最后通过presentAndGetReleaseFences,通知Hal层进行渲染。Hal层会通知hwc硬件进行渲染,hwc最后会通知fb通过lcd驱动渲染到屏幕上。
-
- postComposition 处理一些渲染完的同步参数。
因此我们可以得出一个结论,Android中有两种渲染模式,一种是OpenGL es,一种是HWC模式。最后都会通过HWC通过管道通知到fb中。

在Android渲染体系中,也不是只有一对生产者消费者模型:
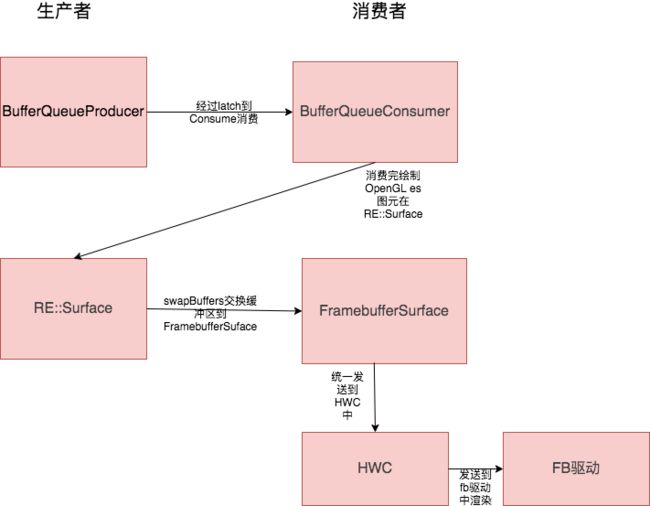
到这里,我们对整个SF的流程已经有一个透彻的理解。但是有一个问题,里面包含了几个不同对象,SF,app应用,OpenGL es,HWC,Android。这些都想都在自己的进程中,有着自己的时间顺序,那么Android是怎么把这些对象同步起来,接下来我们将会对这个问题进行剖析。