ELK集群搭建(四)
ELK集群部署(四)
ELK 是 elastic 公司旗下三款产品ElasticSearch、Logstash、Kibana的首字母组合,也即Elastic Stack包含ElasticSearch、Logstash、Kibana、Beats。ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。
ElasticSearch 一个基于 JSON 的分布式的搜索和分析引擎,作为 ELK 的核心,它集中存储数据,
用来搜索、分析、存储日志。它是分布式的,可以横向扩容,可以自动发现,索引自动分片
Logstash 一个动态数据收集管道,支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),
并对数据做进一步丰富或提取字段处理。用来采集日志,把日志解析为json格式交给ElasticSearch
Kibana 一个数据可视化组件,将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面
Beats 一个轻量型日志采集器,单一用途的数据传输平台,可以将多台机器的数据发送到 Logstash 或 ElasticSearch
X-Pack 一个对Elastic Stack提供了安全、警报、监控、报表、图表于一身的扩展包,不过收费
官网:https://www.elastic.co/cn/ ,中文文档:https://elkguide.elasticsearch.cn/
下载elk各组件的旧版本:
https://www.elastic.co/downloads/past-releases
grok正则表达式参考:
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
集群高可用原理
配置一套高可用的集群,我们必须要了解ES集群的数据分布和负载原理。ES集群是通过多台服务器来搭建,它们拥有一个共同的clustername比如叫做“my-app”,每台服务器叫做一个节点,拥有自己的节点名字:nodename,配置文件如下:
集群名称,用于定义哪些elasticsearch节点属同一个集群
cluster.name: my-app
节点名称,用于唯一标识节点,不可重名
node.name: node-1
设置索引的分片数,默认为5
index.number_of_shards: 5
设置索引的副本数,默认为1:
index.number_of_replicas: 1
这时多台服务器都可以对外提供查询和更改接口,他们彼此之间负载均衡。为了让SpringBoot连接ES集群,我们在SpringBoot中只需配置yml文件如下:
spirng:
data:
elasticsearch:
#集群名称
cluster-name: my-app
#配置es节点信息,逗号分隔,如果没有指定,则启动ClientNode
cluster-nodes: 192.168.1.2:9300,192.168.1.3:9300,192.168.1.4:9300
ES分片
Elasticsearch中的索引(index)是由分片(shard)构成的。比如我们集群中有个索引db_index,该索引由3个分片组成,那么这个db_index索引中的文档数据将分布在这3个分片中。
db_index索引中的文档是根据下面这个规则确定该文档属于哪个分片:
shard = hash(routing) % number_of_primary_shards
routing值默认是文档的_id,number_of_primary_shards是索引的主分片个数
这3个分片可以进行复制,复制是为了实现容错性,比如复制1份,那么一共就需要6个分片(3个主分片+3个主分片复制出来的复制分片)。
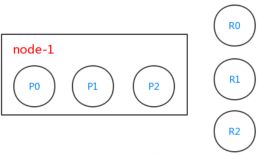
由于db_index索引有3个分片,es内部会创建出3个分片,分别是P0、P1和P2(大写P指的是primary),且这3个分片都是主分片。db_index索引需要对分片进行复制1份,所以这3个主分片都需要复制1份,分别对应R0、R1和R2这3个复制分片(大写R指的是replica)。
这个时候我们的集群只有1个节点node-1,所以复制分片并没有起作用(如果复制分片和主分片在同一个节点了,那么这个复制分片的意义就不存在了。复制分片的意义在于容错性,当一个节点挂了,另一个节点上的分片可以代替挂掉节点上的分片)。
在配置文件里我们看到默认的shards是5个,一个索引的全部数据会被分开存储在这几个分片上,我们用3个分片来看下效果:
单机分片分布,该机器节点拥有全部3个分片,前面★说明是master节点:
![]()
两台集群分片分布,一个节点有一个分片,另一台有两个分片,前面●说明是node节点:

三台集群分片分布, 每个节点拥有一个分片:
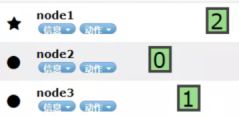
根据以上案例可以看到ES的工作原理是把整个数据分割成3个分片,然后每个节点平均分配。当我们有9个分片时,估计是每台机器各自3个分片。
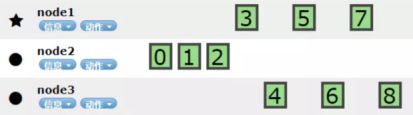
总结:
* ES集群只是根据我们指定的分片数来平均分配到各个节点上
* 当节点数大于分片数时,也不会冗余,只是让多余的节点空着不存数据,不分摊压力
* 当有节点挂掉时,我们一定会丢失一部分数据
根据上面的总结,ES集群无法避免机器挂掉后仍然能不丢数据的正常运行,解决办法是配置文件的另一个参数index.number_of_replicas来达到高可用目的。
ES replicas
index.number_of_replicas是索引的副本数,也就是索引的分片副本数,通过3台机器3个分片的配置来看下效果:
1个副本,每个副本都会把当前的分片全部复制一份并平均分布到集群节点上:
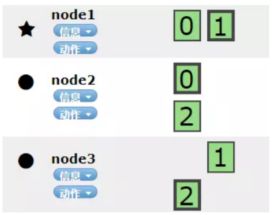
2个副本,每个分片会在其它2个node上复制一份副本:

3个副本当副本数3时,由于此时每台机器都已经占满自己的3个分片了,所以此时需要增加新的机器来存放第三个副本,所以提示了Unassigned:
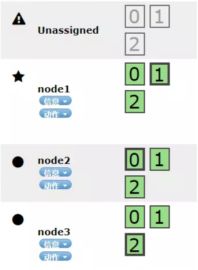
示例
我们以3机器3分片2副本为例:

第一步:
在每个分片编码(0,1,2)上的边框有粗有细,粗的是主分片,细的是副本分片,当node1的机器挂掉时,主节点1丢失,此时集群由green(健康)转为red,因为主节点丢失导致。
第二步:
其它节点上存在着主分片1的完整副本,所以集群立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片,此时集群的状态将会为 yellow 。
为什么我们集群状态是yellow 而不是 green 呢?虽然我们拥有所有的三个主分片,但是同时设置了每个主分片需要对应2份副本分片,而此时只存在一份副本分片。所以集群不能为 green 的状态,不过我们不必过于担心:如果我们同样关闭了 Node 2 ,我们的程序依然可以保持在不丢任何数据的情况下运行,因为 Node 3为每一个分片都保留着一份副本。
第三步:
如果我们重新启动 Node1,Node1依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据文件,集群状态由yellow转为green。
第四步:
如果不重启Node1,而是新增了一台机器并启动加进集群,此时集群可以将缺失的副本分片再次进行分配写入到新增的Node上,那么集群的状态也将由yellow转为green。
由此我们了解了高可用的基本原理,想要配置好高可用,节点数,分片数,副本数这三个数量之间是有很紧密的联系的。
ES高可用配置
| 配置 | 说明 |
|---|---|
| cluster.name | 集群名称,默认为elasticsearch |
| node.name | 配置节点名,用来区分节点 |
| node.master | 是否允许作为集群的主结点 ,值为true或false |
| node.data | 是否存储数据,值为true或false |
| path.data | 数据存放路径 |
| path.logs | 日志路径 |
| network.host | 本节点的IP地址 |
| http.port | 路由地址端口 |
| transport.tcp.port | TCP协议转发地址端口 |
| discovery.zen.ping.unicast.hosts | 用来配置所有用来组建集群的机器的IP地址 |
| discovery.zen.minimum_master_nodes | 用来配置主节点数量的最少值,默认为1 |
脑裂
所谓脑裂问题(类似于精神分裂),就是同一个集群中的不同节点,对于集群的状态有了不一样的理解。比如:
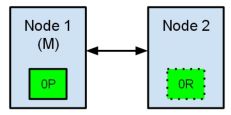
节点1在启动时被选举为主节点并保存主分片标记为0P,而节点2保存复制分片标记为0R。现在,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应,这是有可能发生的。

两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。在elasticsearch集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升复制节点为主节点。
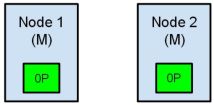
现在我们的集群处在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
如何预防脑裂问题,我们需要看的一个参数就是discovery.zen.minimum_master_nodes。这个参数决定了在选主过程中需要 有多少个节点通信,缺省是1。
一个基本的原则是这里需要设置成 N/2+1,N是集群中节点的数量。
例如在一个三节点的集群中, minimum_master_nodes应该被设为 3/2 + 1 = 2
让我们想象下之前的情况下如果我们把discovery.zen.minimum_master_nodes设置成 2(2/2 + 1)。当两个节点的通信失败了,节点1会失去它的主状态,同时节点2也不会被选举为主。没有一个节点会接受索引或搜索的请求,让所有的客户端马上发现这个问题。而且没有一个分片会处于不一致的状态。
我们可以调的另一个参数是discovery.zen.ping.timeout。它的默认值是3秒,并且它用来决定一个节点在假设集群中的另一个节点响应失败的情况时等待多久。在一个慢速网络中将这个值调的大一点是个不错的主意。这个参数不止适用于高网络延迟,还能在一个节点超载响应很慢时起作用。