作者|Karthik Deivasigamani
编译|VK
来源|Medium
介绍
电子商务目录是通过从卖家、供应商/品牌获取数据而创建的。合作伙伴(销售商、供应商、品牌)提供的数据往往不完整,有时会遗漏我们客户正在寻找的关键信息。尽管合作伙伴遵循一个规范(一种发送产品数据的约定格式),但在标题、描述和图像中隐藏着大量数据。除了我们的合作伙伴提供的数据外,互联网上还有许多非结构化数据,如产品手册、产品评论、博客、社交媒体网站等。
沃尔玛正致力于构建一个零售图谱(Retail Graph),捕捉有关产品及其相关实体的知识,以帮助我们的客户更好地发现产品。它是一个产品知识图谱,可以在零售环境中回答有关产品和相关知识的问题,可用于语义搜索、推荐系统等。本文进一步阐述了什么是零售图谱、如何构建零售图谱、围绕图模型的技术选择、数据库和一些用例。
沃尔玛的零售图谱是什么
零售图谱捕获了零售世界中存在的产品和实体之间的连接。实体是存在的物体、事物、概念或抽象,例如客厅、野生动物摄影、颜色、农舍风格。我们关注的实体大致有两种:抽象的和具体的。前者帮助我们回答诸如“夏日游泳池派对用品”、“农家客厅家具”、“野生动物摄影镜头”之类的问题,而后者帮助我们回答诸如“蓝色牛仔裤裤子”、“木制餐桌”之类的问题。该图谱还将产品之间的关系捕获到两个类别,替代品和补充品(附件、兼容产品等)。它还试图将抽象概念(如亮色)映射到具体的产品属性。
在研究过沃尔玛的产品目录后,我们知道在构建这样一个系统时会遇到一些挑战。最大的挑战是缺乏产品数据的唯一权威来源。此外,我们的目录中也有来自我们合作伙伴的错误数据。所以,我们首先:
- 建立二分图,一边是生成的,另一边是相关实体
- 利用我们现有的分类方法在发现新的实体时丰富实体。
- 连接产品与实体。
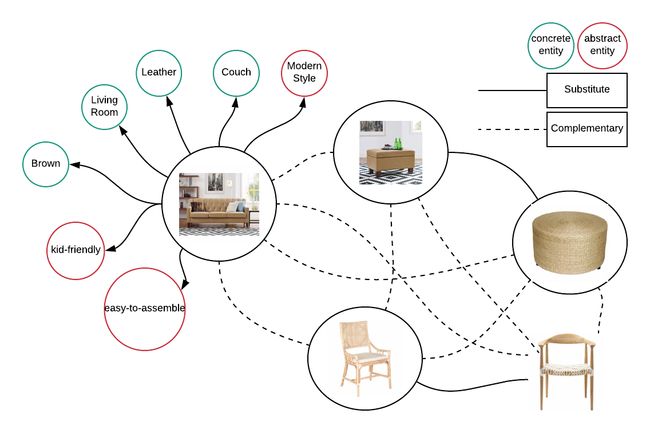
构建零售图谱
在较高层次上,我们主要关注以下关系来构建我们的零售图谱:
- 产品<->实体
- 产品<->产品(大致分为替代品和补充品)
1.产品<->实体
为了构建产品到实体图,我们首先从产品内容中提取实体,然后将它们链接到抽象或具体的概念,形成三元组。我们添加了一个管理层,允许人们在一定的置信水平下得到有效的三元组,以保持高质量标准。
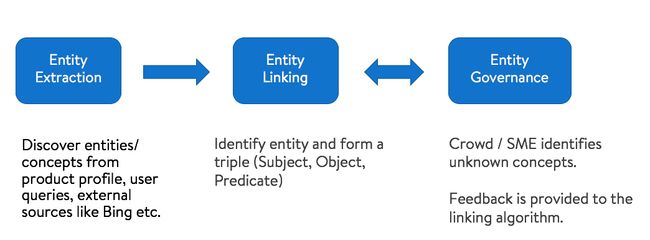
a.实体提取
实体提取模块的目标是从产品标题和描述中提取“实体”。产品描述内容多种多样。有时内容很冗长,有时可能是要点中的小短语。考虑到这一点,我们开发了两种从产品内容中提取实体的算法:
i.基于NLP的模型
我们首先从产品标题、描述和其他元数据中提取实体。这是通过建立一个语言模型来实现的,该模型利用了Standford Core NLP提供的POS标记。这个模型更适合我们的用例,因为产品标题和描述通常是以项目符号的形式出现的,以产品亮点为特征,而不是构造良好的句子。下面是我们基于NLP的模型的输出示例。

ii.启发式模型
我们采取的另一种方法产生了良好的结果,就是使用规则来解析描述。卖家/供应商使用某些格式(HTML标记)来突出产品的关键特性。我们通过对关键信息应用一组启发式方法,建立了关于如何解析和提取关键信息的规则。以下是示例产品说明及其输出:

在生产中,我们可以同时使用上述两种。这可以给我们一个很好的平衡,启发式模型非常准确而NLP模型给我们更大的覆盖。
b.实体链接
一旦实体被提取出来,我们需要识别它们所代表的内容以及它们与产品的关系。例如,对于“中世纪沙发”这样的实体,我们必须确定在沙发的上下文中,中世纪代表什么。这是通过一个称为实体链接的过程来实现的,在这个过程中,我们试图找到提取的实体与其产品之间的关系。实体链接模块的另一个重要功能是消除给定上下文的歧义。例如,“cherry(樱桃)”可以指蜡烛的香味,果汁的香味,家具的香味,布料的颜色,或者樱桃这种水果。这里所指的上下文通常是产品类别或产品类型。
链接器将上下文(产品类型)和实体作为输入,并生成一个三元组(主语-宾语谓词)。由于产品数据没有一个准确的真实来源,连接实体的任务变得很困难。我们首先从一组最畅销的产品(我们假设最畅销的产品有更准确的数据)创建一个产品类型、属性名和属性值三元组的字典。第一步是使用这个字典,在上下文不可知的时候确定可能的候选列表。然后运行第二个模型,通过使用上下文对它们进行排序。
对于上面提取的实体,链接器输出如下所示:
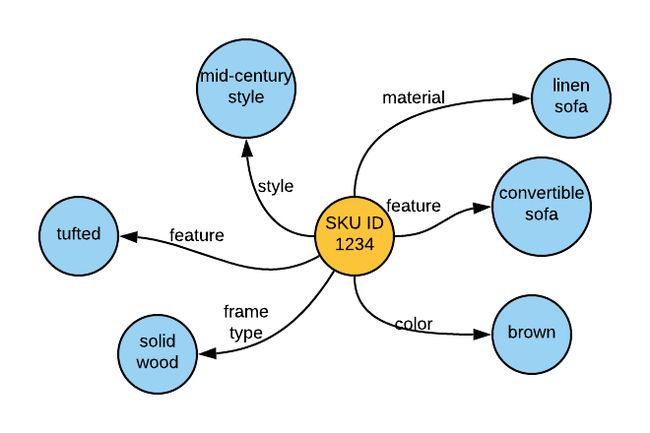
c.实体管理
作为实体提取的一部分,也会提取大量的“噪声”。我们使用现有的产品元数据构建了一个字典,作为将提取的实体分类为噪声或“未知”概念的参考。然后,我们添加了一个管理模块,该模块可以使用启发式和手动标记的组合来消除噪声。这确保了进入知识图谱的数据总是干净可靠的。
2.产品<->产品
为了识别给定产品的替代品,我们同时利用文本数据和图像数据。在家具、服装等产品类别中,视觉相似性在识别替代品方面起着重要作用。我们为我们的产品构建了图像嵌入和文本嵌入,并将它们放入FAISS索引中(FAISS是Facebook开发的一个高效相似性搜索和向量聚类库)。对于每个产品,我们从文本嵌入和图像嵌入两方面生成其KNN(k近邻),以得到候选集。在那之后,我们应用一个类别特定的排名逻辑来得出最终的结果。例如,在家具类别的情况下,“家居装饰风格”(中世纪/沿海/农舍)在确定可替代性方面起着关键作用。
架构
当我们开始构建零售图谱的旅程时,我们不太确定系统的最终状态会是什么样子。我们只知道我们需要一个组件来提取实体,链接它们,然后存储它们。考虑到我们产品目录的规模,我们知道每一个都必须扩展到100亿个产品。此外,还需要快速试验、构建并快速迭代以获得反馈。我们决定采用进化架构原则来构建我们的系统(https://evolutionaryarchitecture.com)。
一个进化的体系结构支持增量的、有指导的变化,这是跨越多个维度的首要原则。
实体提取和链接被构建为简单的库,然后作为REST风格的API公开给其他系统集成。我们还在实体提取和实体链接器库之上构建了Hive udf,以便在我们的Hadoop集群上按比例运行它们。
数据处理管道
我们有两条管道-一条用于生成产品<->实体,另一条用于生成产品<->产品。它们定期在我们的数据平台团队管理的Hadoop集群上运行。以下是对数据处理管道的高度概述:
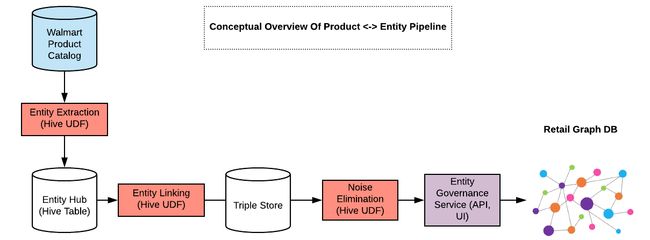
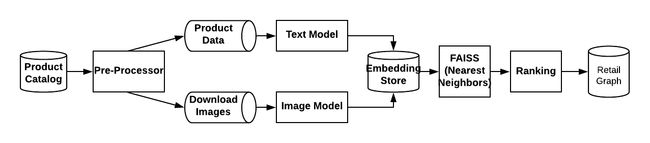
图数据模型和图数据库
在聚合到LPG(标记属性图)之前,我们已经为读写用例测试了LPG和RDF图数据模型。在对内部的图形数据库进行了一些实验之后,我们缩小了对图数据模型的范围。我们与Azure团队密切合作,为我们提供Java支持,以实现数据的大容量接收。对于图形遍历,我们使用gremlin。
沃尔玛内部应用程序
为沃尔玛产品目录的大小构建产品知识图谱需要相当长的时间。我们在构建这个模型时,一次只使用一个类别,然后学习并扩展到其他类别。我们开始这项工作的重点是家庭类和花园类。我们在沃尔玛产品页面上做了一个a/B测试,与使用产品关系的商品推荐团队一起工作。
我们的电子商务语义搜索团队正与我们紧密合作,利用零售图谱中的关系构建一个新的查询理解系统。我们目前正在运行交错测试,A/B测试,以收集客户对我们的新语义搜索实现的反馈。
结尾
很难在一篇文章中详细介绍零售图谱的各个细节,但我希望这能提供一个不错的概述。我们还有很长的路要走。像这样的计划需要快速的迭代、大量的实验。我很幸运,有一个伟大的工程师和数据科学家的团队来合作这个有趣的项目!
原文链接:https://medium.com/walmartlabs/retail-graph-walmarts-product-knowledge-graph-6ef7357963bc
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/