开玩笑呢?学习KMP算法能改变自我认知? | 原力计划


作者 | 落阳学编程
责编 | 王晓曼
出品 | CSDN 博客

前言
近日被朋友问到了字符串匹配算法,让我想起了大二上学期在一次校级编程竞赛中我碰到同样的问题时,为自己写出了暴力匹配算法而沾沾自喜的经历。
现在想来,着实有点羞愧,于是埋头去学习了一下 KMP 算法,为了让自己不至于那么快忘记,也希望小伙伴们能从我的理解中收获一点自己的感悟!
文章带有精心雕琢的动画以便理解。

分析
我们首先来分析一下暴力算法,为鲜花的诞生献上绿叶!
以下文中统一将需要被匹配的字符串(长的那段)称为待匹配串,把用来匹配的字符串(短的那段)称为模式串。
暴力匹配算法的思路很简单,就是每一次都首先将待匹配串和模式串的首字母对齐,然后比对是否相同,若相同则继续比对两个串的下一个位置,如果不相同的话就将模式串向右移动一位,然后再重新开始从头匹配,就像下面这样:

从上面的动画我们可以直观的看出来,下面的模式串在匹配失败之后都只会移动一格,傻里傻气的,这就导致它的时间复杂度是M∗N M*NM∗N,其中M是模式串的长度,N是待匹配串的长度。
对于这个时间复杂度,我不满意!它太傻了,不符合我聪明睿智的气质!
那就来分析一下为何它这么傻。我们可以看到,在第一次匹配失败的时候,我们肯定希望它向右移动至少两格,因为模式串的第一格和第三格都为a,既然第三格已经匹配成功了,那么把第一格对上第三格匹配的位置,那么无疑肯定也是可以成功的,我们的算法本该知道并且利用这一点的!但是它没有,它太傻了。
嗯,这么一说,好像是感觉应该是要把它向着动态规划的方向改(即利用已有信息为下一步提供便利)。
PS:字符串问题百分之八十以上都可以使用动态规划思想达到较低的时间复杂度。

核心问题
我们大都听过一句老话:人啊,贵在有自知之明。
同时我们肯定也听别人说过:人只有深刻的认识了自己,才能找对位置,迅速地向目标前进!
这两句话用在KMP算法中再合适不过了!
KMP算法的核心便在于,模式串对自己的自我认知!
想一想,我们人对自己的认知是如何的:男,19岁,阳光帅气聪明机智,这些自我认知都存放在我的脑袋里面。
那么,模式串对自己的认知应该存放在哪呢?
对,就是next数组里面!字符串没有大脑,所以它需要额外的空间来存储它对自己的认知并借此作出高效准确的判断。
那么字符串对自己的认知是怎样的呢?其实很容易理解,就是知道自己身上哪些地方是相同的,这样的话在匹配失败之后就能迅速找准下次开始的点。这里是不是有点模糊了?图来!
以上就是KMP算法的动画,如果觉得动画稍微有点快的话可以多观看几次,在这个动画里我还没有放出next数组的部分,只是用拟人化的手法展现出来。希望大家能够理解,为什么第一次匹配失败可以直接移动两格。
是因为模式串中第三格的a,它知道在第一格有与自己相同的字符,并且把这个信息告诉下一格的字符,让它在匹配失败之后直接把第一格的a移动到它的那个位置上去。
来看看模式串与其对应的next自我认识数组吧。

不要去在意next数组的第一个为什么是-1,这是为了代码写的方便,暂且就给它当成0。
在动画中,当一个字符发出“直接移动”的语句的时候,其实是告诉后一个字符,如果你匹配失败了的话,就直接移动,同时后一个字符对应的next数组值为0,当后一个字符匹配失败了,就移动模式串的长度-这个匹配失败的字符对应的next值个长度。
从第四个字符(i=3)起,它们都在不断告诉后面一个字符:“将i=0移动到i=3的位置”,这句话对于i=4的字符来说,是移动4-1格,对于i=5的字符来说,是移动5-2格,对于i=6的字符来说,是移动6-3格:后面那个减数恰好就是这个字符对应的next数组的值!
因为模式串足够了解自己,所以它能够在匹配失败的时候不用回退,不用每次只移动一格,而是跟随着待匹配串一起移动。待匹配字符串的指针从未回退过,以线性的速度向前一步步越进。
最终:KMP算法的时间复杂度是M+N M+NM+N
这里我们不禁发出了感叹!原来认识自己真的这么重要啊!
接下来是求出给定模式串的next数组:
Python3代码奉上:
def get_next_lst(ss: str) -> list:
length = len(ss)
next_lst = [0 for _ in range(length)]
next_lst[0] = -1
i = 0
j = -1
while i < length - 1:
if j == -1 or ss[i] == ss[j]:
i += 1
j += 1
next_lst[i] = j
else:
j = next_lst[j]
return next_lst
这段代码最难理解的就是j=next_lst[j]这句话,其实这句话也是动态规划的一个思想,看我为你剖析一下。
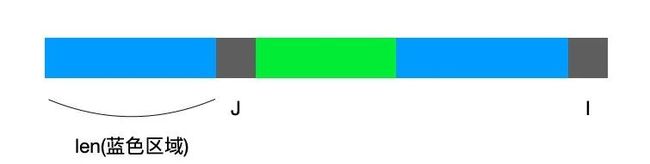
已知蓝色区域相等且长度都为len,那么很明显,next[i] == len,若此时模式串pattern[i] != pattern[j](两个灰色区域不相等)。那么看下图:
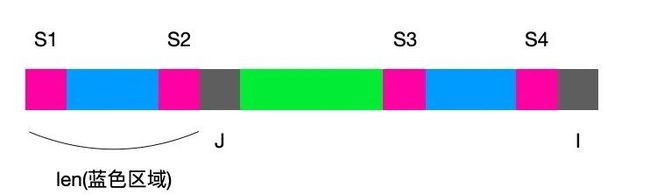
若此时next[j] == len(粉色部分)那么S1==S2,又因为next[i] == next[j],所以S1==S3 且 S3 == S4,则可以推出S1 == S4,这样我们就利用前面所获得的信息,推出了S1 == S4这个信息,然后将J移动到S1后一格,只要再次比较patter[i] 与 patter[j]的相等情况,就可以得出next[i+1]的值。这里因为i始终向后移动,所以也是线性时间复杂度的算法。
ohhhhhhhhh~
到这里,大家就明白了为啥KMP算法的时间复杂度是M+N M+NM+N了。
KMP匹配字符串的完整代码附上!
class KMP():
def __init__(self, ss: str) -> list:
self.length = len(ss)
self.next_lst = [0 for _ in range(self.length)]
self.next_lst[0] = -1
i = 0
j = -1
while i < self.length - 1:
if j == -1 or ss[i] == ss[j]:
i += 1
j += 1
self.next_lst[i] = j
else:
j = self.next_lst[j]
self.pattern = ss
def match_str(self, ss:str):
ans_lst = []
j = 0
for i in range(len(ss)):
if ss[i] != self.pattern[j]:
j = self.next_lst[j] if self.next_lst[j] != -1 else 0
if ss[i] == self.pattern[j]:
j += 1
if j == self.length:
return i + 1 - self.length
return -1
tmp_kmp = KMP('iabc')
print(tmp_kmp.match_str('adosjfoiajsoifjasiofjoiasdjoiabc'))
版权声明:本文为CSDN博主「落阳学编程」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/luoyangIT/java/article/details/106041160


更多精彩推荐
☞中国第一代程序员潘爱民的 30 年程序人生
☞云上容器 ATT&CK 矩阵详解,阿里云助力企业容器化安全落地
☞秋名山老司机从上车到翻车的悲痛经历,带你深刻了解什么是 Spark on Hive | 原力计划
☞拯救渣画质,马赛克图秒变高清,杜克大学提出AI新算法
☞数据科学产业中哪些架构最热门?本文为你盘点了 5 款
☞行业大神支招!5 个方法让你的数字资产免受黑客祸害
你点的每个“在看”,我都认真当成了喜欢