干货|非常详细的 Ceph 介绍、原理、架构
点击上方“民工哥技术之路”选择“星标”
每天10点为你分享不一样的干货

 读者福利!多达 2048G 各种资源免费赠送
读者福利!多达 2048G 各种资源免费赠送
作者:李航
原文:https://www.jianshu.com/p/cc3ece850433
1. Ceph架构简介及使用场景介绍
1.1 Ceph简介
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
1.2 Ceph特点
高性能
高可用性
高可扩展性
特性丰富
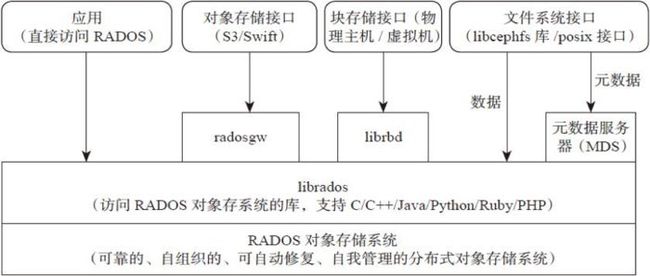
1.3 Ceph架构
支持三种接口:
Object:有原生的API,而且也兼容Swift和S3的API。
Block:支持精简配置、快照、克隆。
File:Posix接口,支持快照。
rados
1.4 Ceph核心组件及概念介绍
Monitor
OSD
MDS
Object
PG
RADOS
Libradio
CRUSH
RBD
RGW
CephFS
1.5 三种存储类型-块存储

rbd
典型设备:磁盘阵列,硬盘
主要是将裸磁盘空间映射给主机使用的。
优点:
通过Raid与LVM等手段,对数据提供了保护。
多块廉价的硬盘组合起来,提高容量。
多块磁盘组合出来的逻辑盘,提升读写效率。
缺点:
采用SAN架构组网时,光纤交换机,造价成本高。
主机之间无法共享数据。
使用场景:
docker容器、虚拟机磁盘存储分配。
日志存储。
文件存储。
…
1.6 三种存储类型-文件存储

fs
典型设备:FTP、NFS服务器
为了克服块存储文件无法共享的问题,所以有了文件存储。
在服务器上架设FTP与NFS服务,就是文件存储。
优点:
造价低,随便一台机器就可以了。
方便文件共享。
缺点:
读写速率低。
传输速率慢。
使用场景:
日志存储。
有目录结构的文件存储。
…
1.7 三种存储类型-对象存储
rgw
典型设备:内置大容量硬盘的分布式服务器(swift, s3)
多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。
优点:
具备块存储的读写高速。
具备文件存储的共享等特性。
使用场景:(适合更新变动较少的数据)
图片存储。
视频存储。
…
2. Ceph IO流程及数据分布
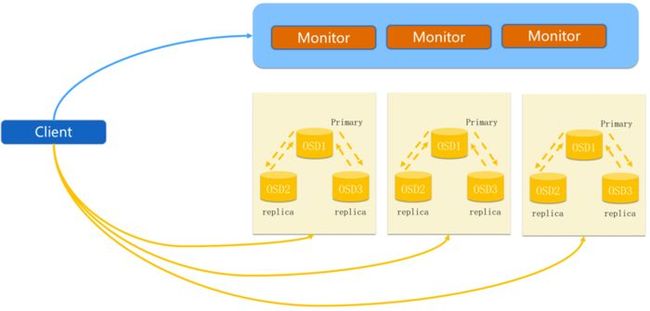
rados_io_1
2.1 正常IO流程图
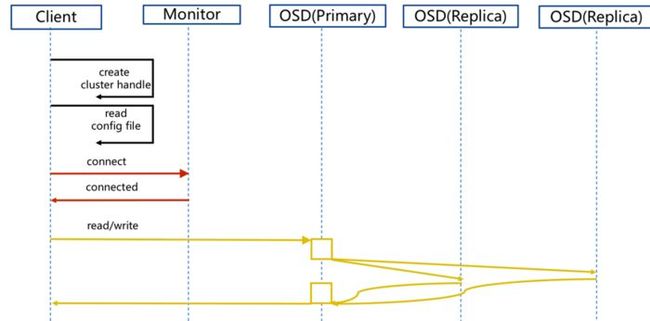
ceph_io_2
步骤:
1. client 创建cluster handler。
2. client 读取配置文件。
3. client 连接上monitor,获取集群map信息。
4. client 读写io 根据crshmap 算法请求对应的主osd数据节点。
5. 主osd数据节点同时写入另外两个副本节点数据。
6. 等待主节点以及另外两个副本节点写完数据状态。
7. 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
2.2 新主IO流程图
说明:
如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
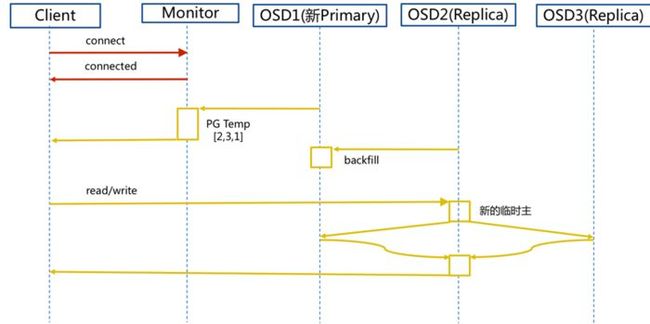
ceph_io_3
步骤:
1. client连接monitor获取集群map信息。
2. 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
3. 临时主osd2会把数据全量同步给新主osd1。
4. client IO读写直接连接临时主osd2进行读写。
5. osd2收到读写io,同时写入另外两副本节点。
6. 等待osd2以及另外两副本写入成功。
7. osd2三份数据都写入成功返回给client, 此时client io读写完毕。
8. 如果osd1数据同步完毕,临时主osd2会交出主角色。
9. osd1成为主节点,osd2变成副本。
2.3 Ceph IO算法流程
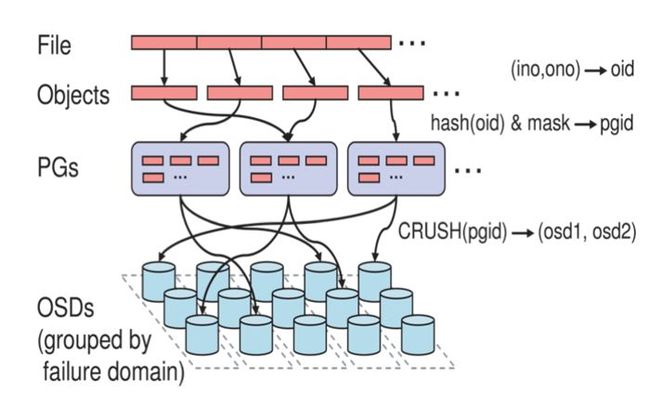
ceph_io_4
1. File用户需要读写的文件。File->Object映射:
a. ino (File的元数据,File的唯一id)。
2. Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid。Object->PG映射:
a. hash(oid) & mask-> pgid 。
3. PG(Placement Group),用途是对object的存储进行组织和位置映射, (类似于redis cluster里面的slot的概念) 一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
a. CRUSH(pgid)->(osd1,osd2,osd3) 。
2.4 Ceph IO伪代码流程
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osdsprimary = osds_for_pg[0]
replicas = osds_for_pg[1:]
2.5 Ceph RBD IO流程
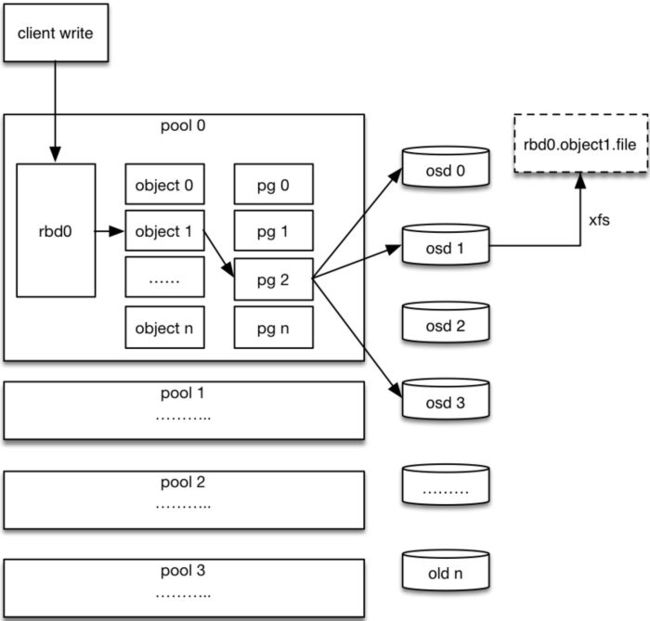
ceph_rbd_io
步骤:
1. 客户端创建一个pool,需要为这个pool指定pg的数量。
2. 创建pool/image rbd设备进行挂载。
3. 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
4. 将每个object通过pg进行副本位置的分配。
5. pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上。
6. osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
7. object的存储就变成了存储一个文rbd0.object1.file。
2.6 Ceph RBD IO框架图
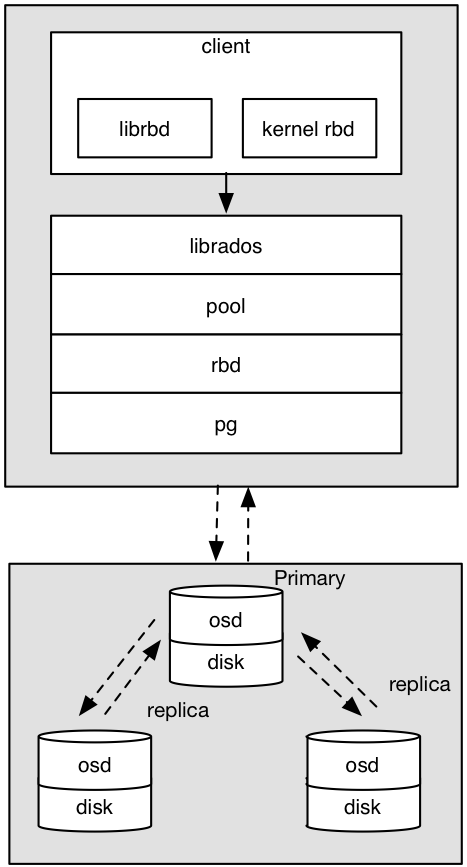
ceph_rbd_io1
客户端写数据osd过程:
1. 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
2. 在客户端本地同过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据保存在哪3个OSD上,这3个OSD分为主从的关系。
3. 客户端与primay OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
2.7 Ceph Pool和PG分布情况
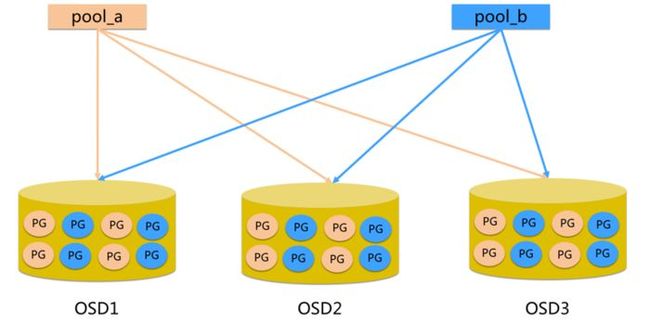
ceph_pool_pg
说明:
pool是ceph存储数据时的逻辑分区,它起到namespace的作用。
每个pool包含一定数量(可配置)的PG。
PG里的对象被映射到不同的Object上。
pool是分布到整个集群的。
pool可以做故障隔离域,根据不同的用户场景不一进行隔离。
2.8 Ceph 数据扩容PG分布
场景数据迁移流程:
现状3个OSD, 4个PG
扩容到4个OSD, 4个PG
现状:
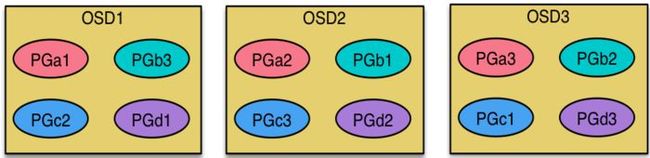
ceph_recory_1
扩容后:

ceph_io_recry2
说明
每个OSD上分布很多PG, 并且每个PG会自动散落在不同的OSD上。如果扩容那么相应的PG会进行迁移到新的OSD上,保证PG数量的均衡。
3. Ceph心跳机制
3.1 心跳介绍
心跳是用于节点间检测对方是否故障的,以便及时发现故障节点进入相应的故障处理流程。
问题:
故障检测时间和心跳报文带来的负载之间做权衡。
心跳频率太高则过多的心跳报文会影响系统性能。
心跳频率过低则会延长发现故障节点的时间,从而影响系统的可用性。
故障检测策略应该能够做到:
及时:节点发生异常如宕机或网络中断时,集群可以在可接受的时间范围内感知。
适当的压力:包括对节点的压力,和对网络的压力。
容忍网络抖动:网络偶尔延迟。
扩散机制:节点存活状态改变导致的元信息变化需要通过某种机制扩散到整个集群。
3.2 Ceph 心跳检测
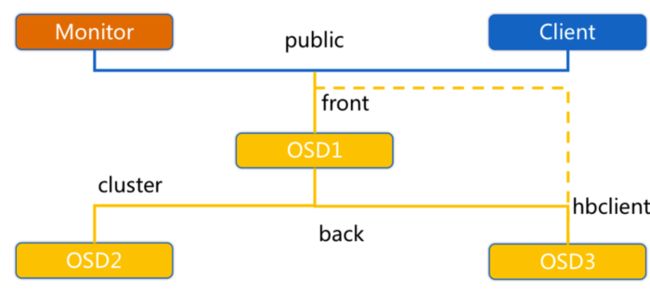
ceph_heartbeat_1
OSD节点会监听public、cluster、front和back四个端口
public端口:监听来自Monitor和Client的连接。
cluster端口:监听来自OSD Peer的连接。
front端口:供客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
back端口:供客集群内部使用的网卡。集群内部之间进行心跳。
hbclient:发送ping心跳的messenger。
3.3 Ceph OSD之间相互心跳检测
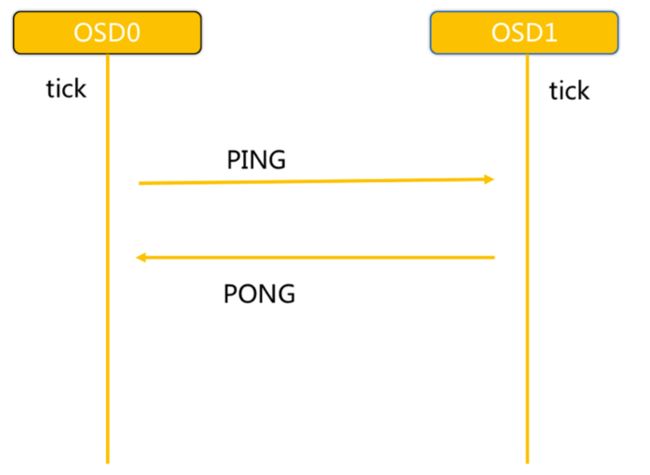
ceph_heartbeat_osd
步骤:
同一个PG内OSD互相心跳,他们互相发送PING/PONG信息。
每隔6s检测一次(实际会在这个基础上加一个随机时间来避免峰值)。
20s没有检测到心跳回复,加入failure队列。
3.4 Ceph OSD与Mon心跳检测
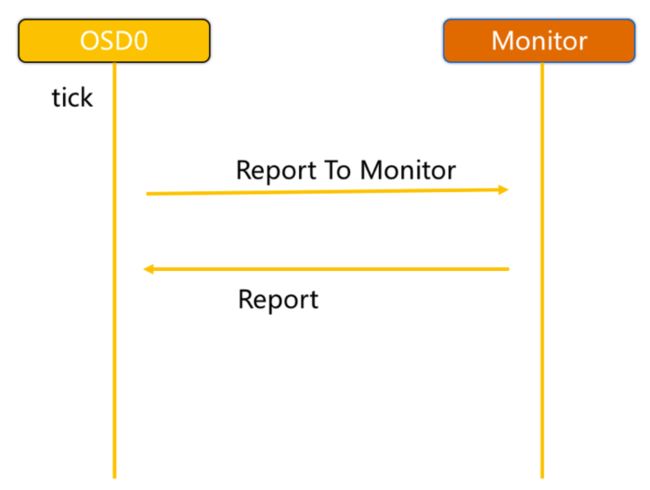
ceph_heartbeat_mon
OSD报告给Monitor:
OSD有事件发生时(比如故障、PG变更)。
自身启动5秒内。
OSD周期性的上报给Monito
OSD检查failure_queue中的伙伴OSD失败信息。
向Monitor发送失效报告,并将失败信息加入failure_pending队列,然后将其从failure_queue移除。
收到来自failure_queue或者failure_pending中的OSD的心跳时,将其从两个队列中移除,并告知Monitor取消之前的失效报告。
当发生与Monitor网络重连时,会将failure_pending中的错误报告加回到failure_queue中,并再次发送给Monitor。
Monitor统计下线OSD
Monitor收集来自OSD的伙伴失效报告。
当错误报告指向的OSD失效超过一定阈值,且有足够多的OSD报告其失效时,将该OSD下线。
3.5 Ceph心跳检测总结
Ceph通过伙伴OSD汇报失效节点和Monitor统计来自OSD的心跳两种方式判定OSD节点失效。
及时:伙伴OSD可以在秒级发现节点失效并汇报Monitor,并在几分钟内由Monitor将失效OSD下线。
适当的压力:由于有伙伴OSD汇报机制,Monitor与OSD之间的心跳统计更像是一种保险措施,因此OSD向Monitor发送心跳的间隔可以长达600秒,Monitor的检测阈值也可以长达900秒。Ceph实际上是将故障检测过程中中心节点的压力分散到所有的OSD上,以此提高中心节点Monitor的可靠性,进而提高整个集群的可扩展性。
容忍网络抖动:Monitor收到OSD对其伙伴OSD的汇报后,并没有马上将目标OSD下线,而是周期性的等待几个条件:
目标OSD的失效时间大于通过固定量osd_heartbeat_grace和历史网络条件动态确定的阈值。
来自不同主机的汇报达到mon_osd_min_down_reporters。
满足前两个条件前失效汇报没有被源OSD取消。
扩散:作为中心节点的Monitor并没有在更新OSDMap后尝试广播通知所有的OSD和Client,而是惰性的等待OSD和Client来获取。以此来减少Monitor压力并简化交互逻辑。
4. Ceph通信框架
4.1 Ceph通信框架种类介绍
网络通信框架三种不同的实现方式:
Simple线程模式
Async事件的I/O多路复用模式
XIO方式使用了开源的网络通信库accelio来实现
4.2 Ceph通信框架设计模式
设计模式(Subscribe/Publish):
订阅发布模式又名观察者模式,它意图是“定义对象间的一种一对多的依赖关系,
4.3 Ceph通信框架流程图
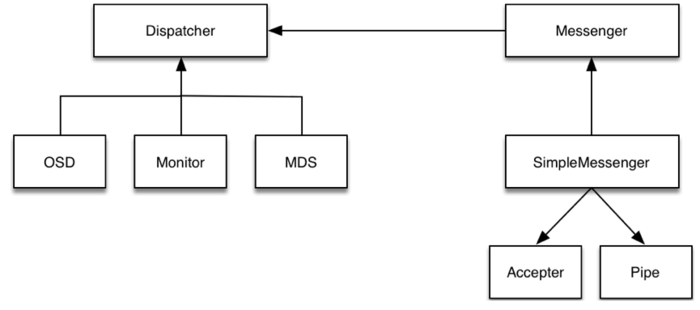
ceph_message
步骤:
Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe 到 SimpleMessenger::pipes 来处理该请求。
Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过 Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通知该类处理。
DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。
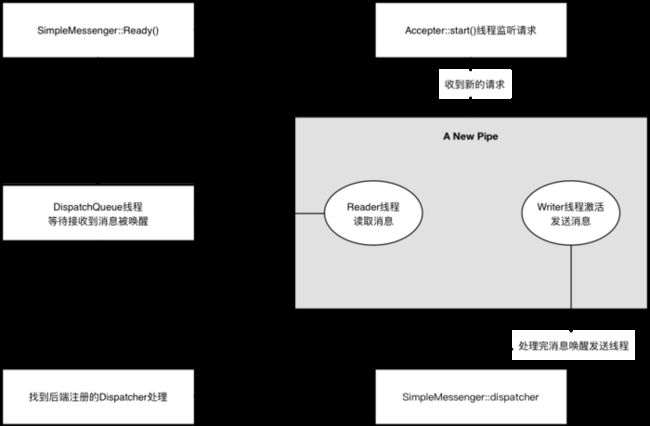
ceph_message_2
4.4 Ceph通信框架类图
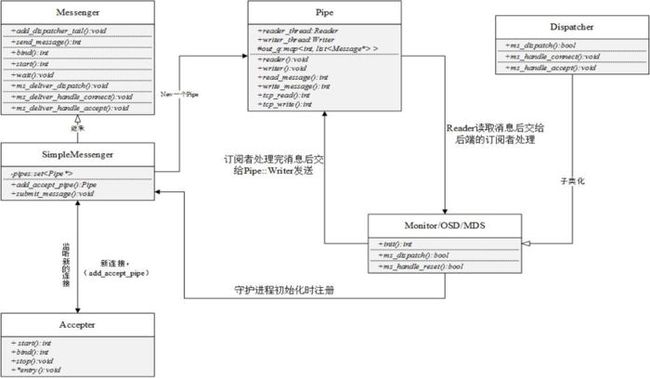
ceph_message_3
4.5 Ceph通信数据格式
通信协议格式需要双方约定数据格式。
消息的内容主要分为三部分:
header //消息头,类型消息的信封
user data //需要发送的实际数据
payload //操作保存元数据
middle //预留字段
data //读写数据
footer //消息的结束标记
class Message : public RefCountedObject {
protected:
ceph_msg_header header; // 消息头
ceph_msg_footer footer; // 消息尾
bufferlist payload; // "front" unaligned blob
bufferlist middle; // "middle" unaligned blob
bufferlist data; // data payload (page-alignment will be preserved where possible)
/* recv_stamp is set when the Messenger starts reading the
* Message off the wire */
utime_t recv_stamp; //开始接收数据的时间戳
/* dispatch_stamp is set when the Messenger starts calling dispatch() on
* its endpoints */
utime_t dispatch_stamp; //dispatch 的时间戳
/* throttle_stamp is the point at which we got throttle */
utime_t throttle_stamp; //获取throttle 的slot的时间戳
/* time at which message was fully read */
utime_t recv_complete_stamp; //接收完成的时间戳
ConnectionRef connection; //网络连接
uint32_t magic = 0; //消息的魔术字
bi::list_member_hook<> dispatch_q; //boost::intrusive 成员字段
};
struct ceph_msg_header {
__le64 seq; // 当前session内 消息的唯一 序号
__le64 tid; // 消息的全局唯一的 id
__le16 type; // 消息类型
__le16 priority; // 优先级
__le16 version; // 版本号
__le32 front_len; // payload 的长度
__le32 middle_len;// middle 的长度
__le32 data_len; // data 的 长度
__le16 data_off; // 对象的数据偏移量
struct ceph_entity_name src; //消息源
/* oldest code we think can decode this. unknown if zero. */
__le16 compat_version;
__le16 reserved;
__le32 crc; /* header crc32c */
} __attribute__ ((packed));
struct ceph_msg_footer {
__le32 front_crc, middle_crc, data_crc; //crc校验码
__le64 sig; //消息的64位signature
__u8 flags; //结束标志
} __attribute__ ((packed));
5. Ceph CRUSH算法
5.1 数据分布算法挑战
数据分布和负载均衡:
灵活应对集群伸缩
支持大规模集群
5.2 Ceph CRUSH算法说明
CRUSH算法的全称为:Controlled Scalable Decentralized Placement of Replicated Data,可控的、可扩展的、分布式的副本数据放置算法。
pg到OSD的映射的过程算法叫做CRUSH 算法。(一个Object需要保存三个副本,也就是需要保存在三个osd上)。
CRUSH算法是一个伪随机的过程,他可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。
5.3 Ceph CRUSH算法原理
CRUSH算法因子:
层次化的Cluster Map
Placement Rules
5.3.1 层级化的Cluster Map
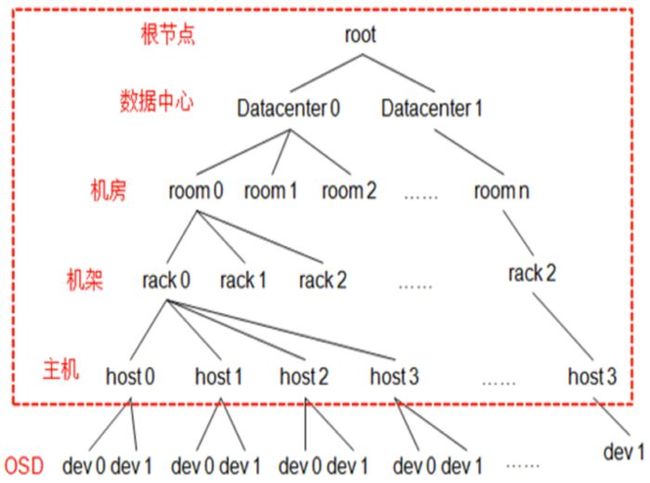
ceph_crush
CRUSH Map是一个树形结构,OSDMap更多记录的是OSDMap的属性(epoch/fsid/pool信息以及osd的ip等等)。
叶子节点是device(也就是osd),其他的节点称为bucket节点,这些bucket都是虚构的节点,可以根据物理结构进行抽象,当然树形结构只有一个最终的根节点称之为root节点,中间虚拟的bucket节点可以是数据中心抽象、机房抽象、机架抽象、主机抽象等。
5.3.2 数据分布策略Placement Rules
数据分布策略Placement Rules主要有特点:
a. 从CRUSH Map中的哪个节点开始查找
rule replicated_ruleset #规则集的命名,创建pool时可以指定rule集
{
ruleset 0 #rules集的编号,顺序编即可
type replicated #定义pool类型为replicated(还有erasure模式)
min_size 1 #pool中最小指定的副本数量不能小1
max_size 10 #pool中最大指定的副本数量不能大于10
step take default #查找bucket入口点,一般是root类型的bucket
step chooseleaf firstn 0 type host #选择一个host,并递归选择叶子节点osd
step emit #结束
}
5.3.3 Bucket随机算法类型
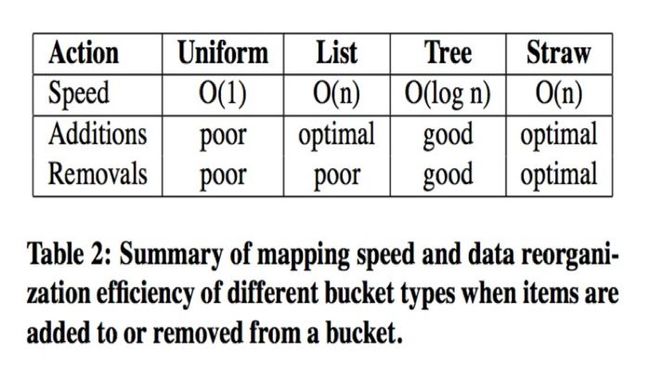
ceph_bucket
一般的buckets:适合所有子节点权重相同,而且很少添加删除item。
list buckets:适用于集群扩展类型。增加item,产生最优的数据移动,查找item,时间复杂度O(n)。
tree buckets:查找负责度是O (log n), 添加删除叶子节点时,其他节点node_id不变。
straw buckets:允许所有项通过类似抽签的方式来与其他项公平“竞争”。定位副本时,bucket中的每一项都对应一个随机长度的straw,且拥有最长长度的straw会获得胜利(被选中),添加或者重新计算,子树之间的数据移动提供最优的解决方案。
5.4 CRUSH算法案例
说明:
集群中有部分sas和ssd磁盘,现在有个业务线性能及可用性优先级高于其他业务线,能否让这个高优业务线的数据都存放在ssd磁盘上。
普通用户:
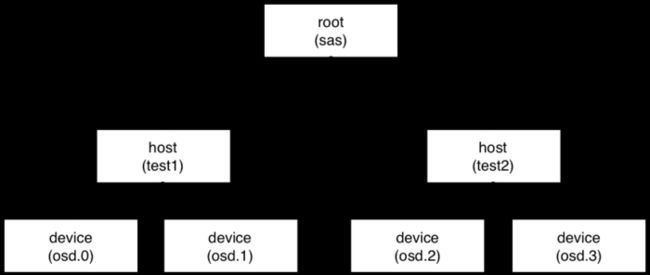
ceph_sas.png
高优用户:
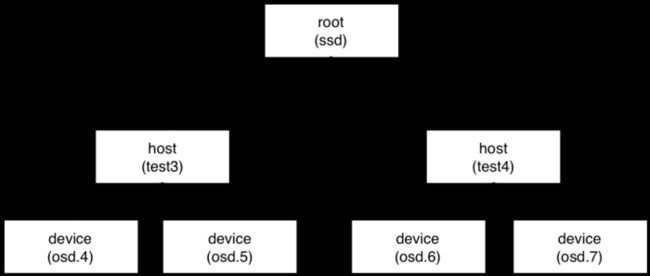
ssd
配置规则:

ceph_crush1
6. 定制化Ceph RBD QOS
6.1 QOS介绍
QoS (Quality of Service,服务质量)起源于网络技术,它用来解决网络延迟和阻塞等问题,能够为指定的网络通信提供更好的服务能力。
问题:
我们总的Ceph集群的iIO能力是有限的,比如带宽,IOPS。如何避免用户争取资源,如果保证集群所有用户资源的高可用性,以及如何保证高优用户资源的可用性。所以我们需要把有限的IO能力合理分配。
6.2 Ceph IO操作类型
ClientOp:来自客户端的读写I/O请求。
SubOp:osd之间的I/O请求。主要包括由客户端I/O产生的副本间数据读写请求,以及由数据同步、数据扫描、负载均衡等引起的I/O请求。
SnapTrim:快照数据删除。从客户端发送快照删除命令后,删除相关元数据便直接返回,之后由后台线程删除真实的快照数据。通过控制snaptrim的速率间接控制删除速率。
Scrub:用于发现对象的静默数据错误,扫描元数据的Scrub和对象整体扫描的deep Scrub。
Recovery:数据恢复和迁移。集群扩/缩容、osd失效/从新加入等过程。
6.3 Ceph 官方QOS原理
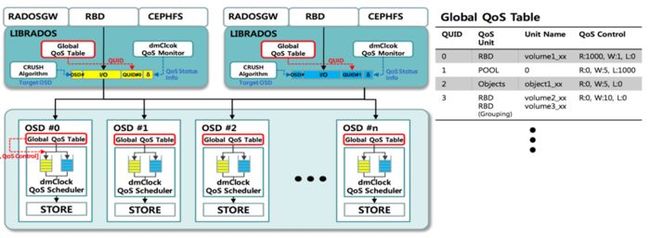
ceph_mclok_qos
mClock是一种基于时间标签的I/O调度算法,最先被Vmware提出来的用于集中式管理的存储系统。(目前官方QOS模块属于半成品)。
基本思想:
reservation 预留,表示客户端获得的最低I/O资源。
weight 权重,表示客户端所占共享I/O资源的比重。
limit 上限,表示客户端可获得的最高I/O资源。
6.4 定制化QOS原理
6.4.1 令牌桶算法介绍
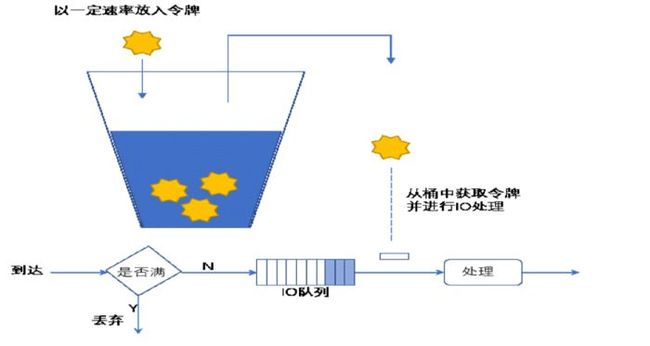
ceph_token_qos
基于令牌桶算法(TokenBucket)实现了一套简单有效的qos功能,满足了云平台用户的核心需求。
基本思想:
按特定的速率向令牌桶投放令牌。
根据预设的匹配规则先对报文进行分类,不符合匹配规则的报文不需要经过令牌桶的处理,直接发送。
符合匹配规则的报文,则需要令牌桶进行处理。当桶中有足够的令牌则报文可以被继续发送下去,同时令牌桶中的令牌量按报文的长度做相应的减少。
当令牌桶中的令牌不足时,报文将不能被发送,只有等到桶中生成了新的令牌,报文才可以发送。这就可以限制报文的流量只能是小于等于令牌生成的速度,达到限制流量的目的。
6.4.2 RBD令牌桶算法流程
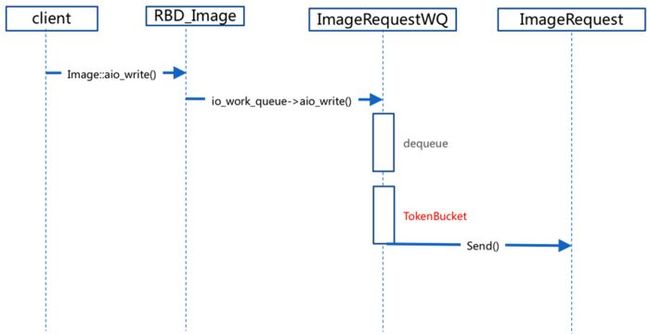
ceph_token1
步骤:
用户发起请求异步IO到达Image中。
请求到达ImageRequestWQ队列中。
在ImageRequestWQ出队列的时候加入令牌桶算法TokenBucket。
通过令牌桶算法进行限速,然后发送给ImageRequest进行处理。
6.4.3 RBD令牌桶算法框架图
现有框架图:
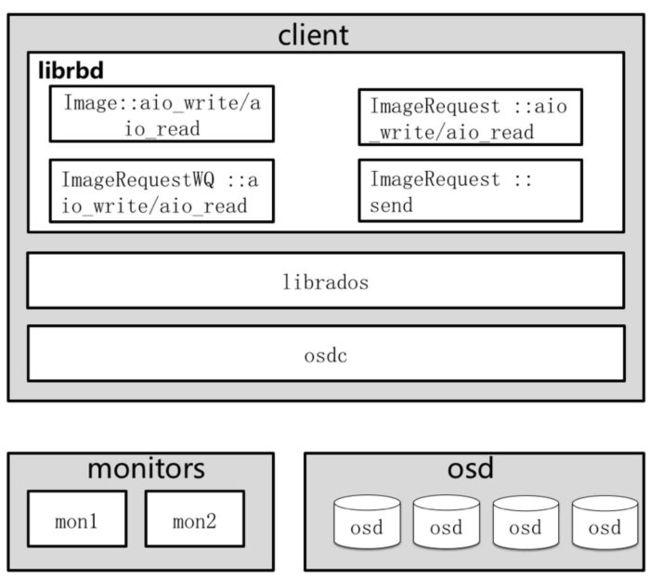
ceph_qos2
令牌图算法框架图:
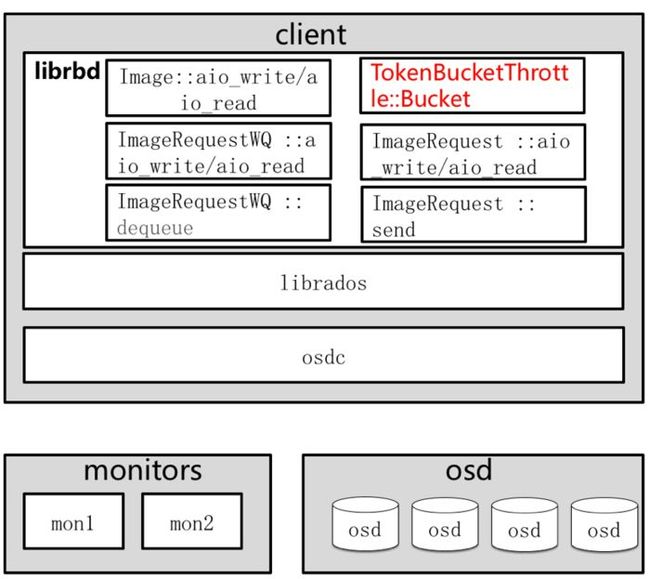
ceph_qos_token2
关注 民工哥技术之路 微信公众号对话框回复关键字:1024 可以获取一份最新整理的技术干货。

我在网盘中看到了无数人泄露的私密文件
sonar+Jenkins 构建代码质量自动化分析平台
警惕!又一疑似东南亚“黑砖窑”人才输送基地
不想起标题,只想发红包~|读者福利
使用 zabbix 监控 tomcat(包含jvm监控)
怎么选?毕竟可以上网的浏览器只剩下四款了...
这 8 个 Python 技巧让你的数据分析提升数倍!

点击【阅读原文】和民工哥一起聊技术、搞事情~~
点“在看”一定不能放弃啊!