使用early stopping解决神经网络过拟合问题
神经网络训练多少轮是一个很关键的问题,训练轮数少了欠拟合(underfit),训练轮数多了过拟合(overfit),那如何选择训练轮数呢?
Early stopping可以帮助我们解决这个问题,它的作用就是当模型在验证集上的性能不再增加的时候就停止训练,从而达到充分训练的作用,又避免过拟合。
一、在Keras中使用early stopping
完整代码
Keras中有EarlyStopping类,可以直接拿来使用,非常方便
from keras.callbacks import EarlyStopping
earlystop = EarlyStopping(monitor = 'val_loss',
mode='min',
min_delta = 0,
patience = 3,
verbose = 1,
)- monitor。想要监控的指标,比如在这里我们主要看的是验证集上的loss,当loss不再降低的时候就停止
- mode。想要最大值还是最小值,在这里我们使用的min,当时loss越小越好
- min_delta。指标的变化超过min_delta才认为产生了变化,否则都认为不再上升或下降
- patience。多少轮不发生变化才停止
- verbose。设置为1的时候,训练结束会打印出epoch的情况
二、保存最佳模型
完整代码
在early stopping结束后得到模型不一定是最佳模型,所以我们需要把训练过程中表现最好的模型保存下来,以便使用。在这里我们可以使用Keras提供的另一callback来实现:
from keras.callbacks import ModelCheckpoint
mc = ModelCheckpoint(file_path='./best_model.h5',
monitor='val_accuracy',
mode='max',
verbose=1,
save_best_only=True)- filepath,模型存储的路径
- monitor,监控的指标
- mode,最大还是最小模式
- verbose,日志显示控制
- save_best_only,是否只存储最好的模型
通过使用这个方法我们就可以把最好的模型存储下来,在使用的时候直接load就可以了。
三、在IMDB数据集上使用Early Stopping
完整代码
IMDB是一个情感分析数据集,我们首先在这个数据集上使用一个简单的CNN看看效果,然后再使用Early Stopping作为对比。首先看看CNN代码。先对句子embedding, 然后使用一层Conv1D+Maxpooling。
# Build model
sentence = Input(batch_shape=(None, max_words), dtype='int32', name='sentence')
embedding_layer = Embedding(top_words, embedding_dims, input_length=max_words)
sent_embed = embedding_layer(sentence)
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)
sent_pooling = GlobalMaxPooling1D()(sent_conv)
sent_repre = Dense(250)(sent_pooling)
sent_repre = Activation('relu')(sent_repre)
sent_repre = Dense(1)(sent_repre)
pred = Activation('sigmoid')(sent_repre)
model = Model(inputs=sentence, outputs=pred)
rmsprop = optimizers.rmsprop(lr=0.0003)
model.compile(loss='binary_crossentropy', optimizer=rmsprop, metrics=['accuracy'])最终在数据集上的结果如下,在训练集上基本达到了100,而在测试集上还不到90,看起来有点过拟合了
Training Accuracy: 100%
Test Accuracy: 88.50%我们再看Loss曲线,大约在第8轮的时候,验证集上的Loss达到最低,但是在往后Loss开始升高,这就更加确定发生了过拟合,我们需要提前停止训练,最好在第8轮之后就停下来。
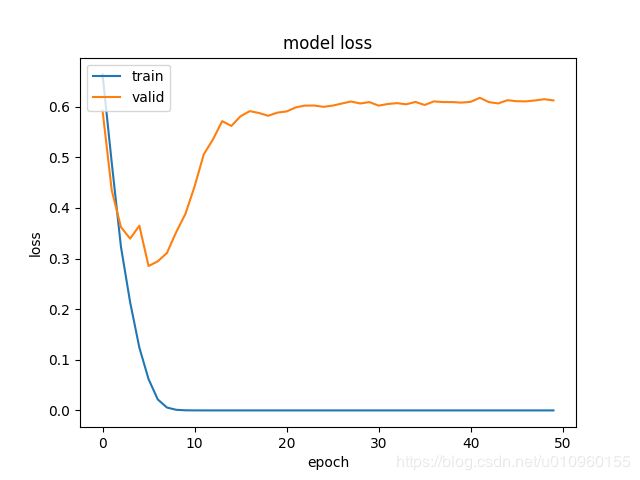
在IMDB数据集上使用Early Stopping
我们再训练过程中加上一个patience=10的earlystop,监控验证集loss。当验证集的loss在近10轮都没有下降的话就停止。
#early stopping
earlystop = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=10,
verbose=1)
# fit the model
history = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks[earlystop])结果如下,我们可以看到训练最终在第16轮停止了,停止时在测试集上的准确率为88.40%,并没有高于不使用Early Stopping的情况,但是在训练的第12轮模型的准确达到了89.30%,超过了Baseline。所以我们需要加上存储最好模型的callback。
Epoch 2/50
5000/5000 [==============================] - 5s 951us/step - loss: 0.4851 - acc: 0.7986 - val_loss: 0.4320 - val_acc: 0.8170
Epoch 3/50
5000/5000 [==============================] - 5s 918us/step - loss: 0.3193 - acc: 0.8802 - val_loss: 0.3599 - val_acc: 0.8370
Epoch 4/50
5000/5000 [==============================] - 4s 882us/step - loss: 0.2093 - acc: 0.9322 - val_loss: 0.3392 - val_acc: 0.8530
Epoch 5/50
5000/5000 [==============================] - 4s 880us/step - loss: 0.1209 - acc: 0.9702 - val_loss: 0.4001 - val_acc: 0.8260
Epoch 6/50
5000/5000 [==============================] - 4s 887us/step - loss: 0.0600 - acc: 0.9884 - val_loss: 0.2900 - val_acc: 0.8710
Epoch 7/50
5000/5000 [==============================] - 4s 865us/step - loss: 0.0208 - acc: 0.9986 - val_loss: 0.2978 - val_acc: 0.8840
Epoch 8/50
5000/5000 [==============================] - 4s 883us/step - loss: 0.0053 - acc: 1.0000 - val_loss: 0.3180 - val_acc: 0.8840
Epoch 9/50
5000/5000 [==============================] - 4s 856us/step - loss: 0.0011 - acc: 1.0000 - val_loss: 0.3570 - val_acc: 0.8830
Epoch 10/50
5000/5000 [==============================] - 4s 845us/step - loss: 1.7574e-04 - acc: 1.0000 - val_loss: 0.4035 - val_acc: 0.8800
Epoch 11/50
5000/5000 [==============================] - 4s 869us/step - loss: 2.0190e-05 - acc: 1.0000 - val_loss: 0.4490 - val_acc: 0.8820
Epoch 12/50
5000/5000 [==============================] - 4s 846us/step - loss: 1.6874e-06 - acc: 1.0000 - val_loss: 0.5164 - val_acc: 0.8930
Epoch 13/50
5000/5000 [==============================] - 4s 860us/step - loss: 2.6231e-07 - acc: 1.0000 - val_loss: 0.5429 - val_acc: 0.8840
Epoch 14/50
5000/5000 [==============================] - 4s 870us/step - loss: 1.4614e-07 - acc: 1.0000 - val_loss: 0.5754 - val_acc: 0.8810
Epoch 15/50
5000/5000 [==============================] - 4s 888us/step - loss: 1.2477e-07 - acc: 1.0000 - val_loss: 0.5744 - val_acc: 0.8850
Epoch 16/50
5000/5000 [==============================] - 4s 876us/step - loss: 1.1823e-07 - acc: 1.0000 - val_loss: 0.5909 - val_acc: 0.8840
Epoch 00016: early stopping
Accuracy: 88.40%
存储最好模型
我们使用ModelCheckPoint存储最好的模型,具体如下,通过监控验证集上的准确率,我们把准确率最高的模型存储下来
from keras.callbacks import EarlyStopping, ModelCheckpoint
mc = ModelCheckpoint(filepath='best_model.h5',
monitor='val_acc',
mode='max',
verbose=1,
save_best_only=True)然后在使用的时候进行load,然后就可以进行预测了
from keras.models import load_model
saved_model = load_model('best_model.h5')
# evaluate the model
_, train_acc = saved_model.evaluate(x_train, y_train, verbose=0)
_, test_acc = saved_model.evaluate(x_test, y_test, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))最终的结果如下
Train: 1.000, Test: 0.893正确使用Early Stopping加上存储最佳模型可以帮助我们减轻过拟合,从而训练出表现更好的模型。
完整代码