【AI视野·今日CV 计算机视觉论文速览 第156期】Mon, 9 Sep 2019
AI视野·今日CS.CV 计算机视觉论文速览Mon, 9 Sep 2019
Totally 32 papers
?上期速览✈更多精彩请移步主页

Interesting:
?基于语义相关性形状可变上下文的分割方法, 提出了一种多尺度、多形状变体的语义掩膜来定义上下文区域,并基于配对卷积预测出语义关系,生成形状掩膜。最后利用可变形卷积,在形状掩膜的控制下聚合语义相关区域的上下文信息来获得更为准确的语义区域(from 南洋理工 亚马逊、阿里)
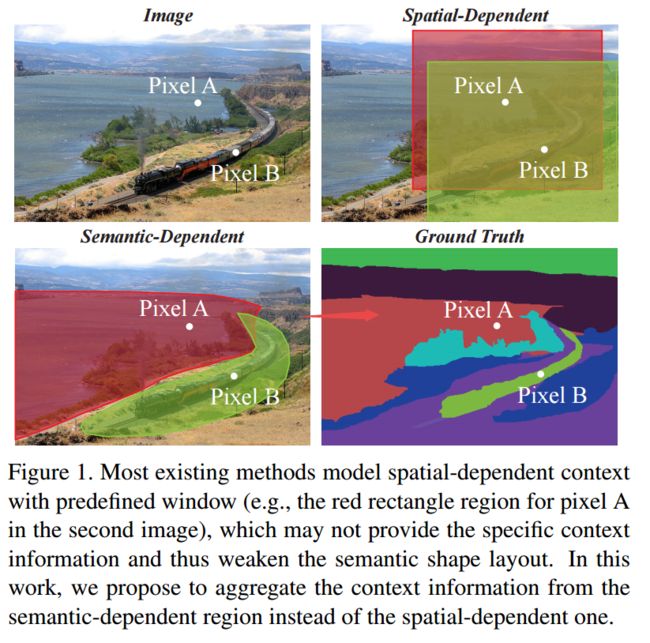
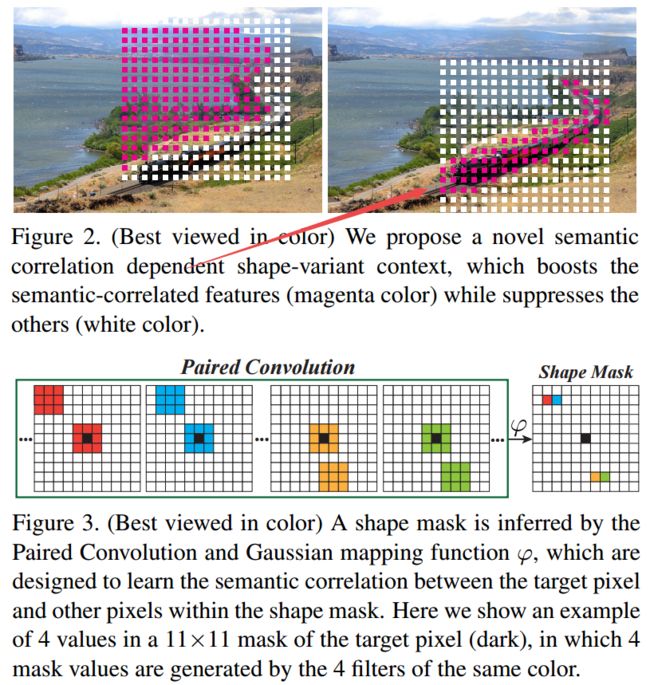
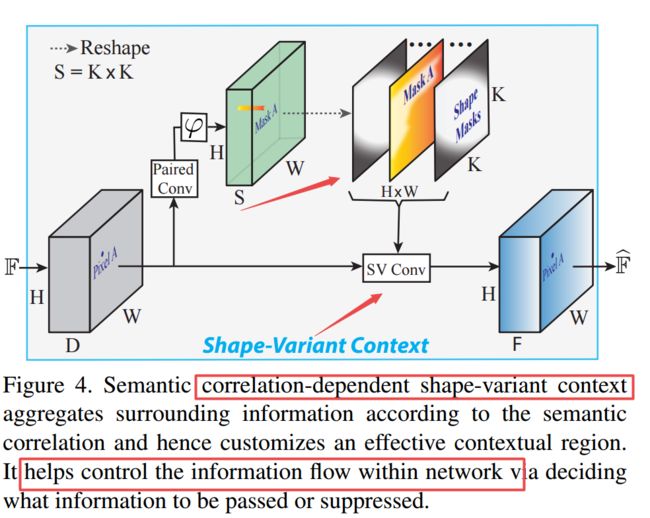
形状可变形卷积SV Conv,其中上半部分用于学习语义相关性,用于得到语义形状掩膜:
一些最后的实验结果:

?文本关系解译方法, (from 杨百翰大学)
?TFCheck一个用于检测训练问题的tensorflow工具包, (from 蒙特利尔理工)

?DeepEvolution基于搜索的深度学习测试新方法,基于元启发方法保证测试集最大的多样性, (from 蒙特利尔理工)

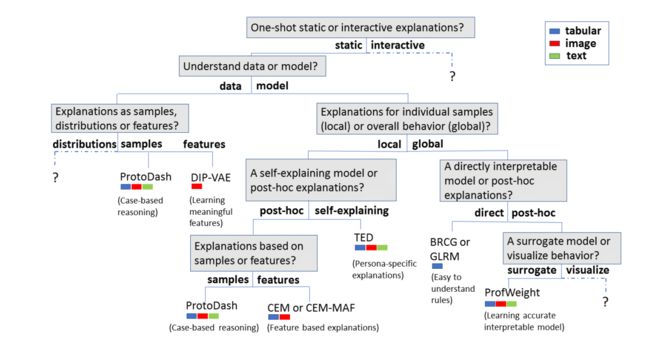
?AIX360:AI可解释性工具箱以及可解释性分类学方法, (from IBM research)
https://github.com/IBM/AIX360/
http://aix360.mybluemix.net/
Daily Computer Vision Papers
| Explicit Facial Expression Transfer via Fine-Grained Semantic Representations Authors Zhiwen Shao, Hengliang Zhu, Junshu Tang, Xuequan Lu, Lizhuang Ma 两个未配对图像之间的面部表情转移是一个具有挑战性的问题,因为细粒度表达通常与其他面部属性(例如身份和姿势)纠缠在一起。大多数现有方法将表达转移视为表达操纵的应用,并使用源图像的预测面部表情,界标或动作单元AU来指导目标图像的表达编辑。然而,表达式,地标尤其是AU的预测可能是不准确的,这限制了传递细粒度表达式的准确性。我们建议通过将两个不成对的图像直接映射到具有交换表达式的两个合成图像来代替使用中间估计指导。由于每个AU在语义上描述了本地表达式细节,因此我们可以通过将AU自由特征与交换的AU相关特征相结合来合成具有保留的标识和交换表达式的新图像。为了将图像分解为AU相关特征和AU自由特征,我们提出了一种新的对抗训练方法,可以解决多类分类问题的对抗性学习。此外,为了获得未配对输入的可靠表达转移结果,我们引入交换一致性损失以使合成图像和自重建图像难以区分。对RaFD,MMI和CFD数据集的广泛实验表明,我们的方法可以在不成对的图像之间生成照片逼真的表达转移结果,这些图像具有不同的表情外观,包括性别,年龄,种族和姿势。 |
| Discriminative and Robust Online Learning for Siamese Visual Tracking Authors Jinghao Zhou, Peng Wang, Haoyang Sun 视觉对象跟踪的问题传统上由变体跟踪范例处理,要么专门在线学习对象外观的模型,要么在离线训练的嵌入空间中将对象与目标匹配。尽管最近取得了成功,但每种方法都因其内在约束而苦恼。在线唯一方法遭受缺乏对他们所学习的模型的泛化因此在目标回归中较差,而离线仅接近例如,信号暹罗跟踪器缺乏视频特定上下文信息因此不足以区别对待处理干扰物。因此,我们提出了一个并行框架,将离线训练的连体网络与轻量级在线模块集成,以增强辨别能力。我们进一步为暹罗网络应用简单但强大的模板更新策略,以处理对象变形。通过对三个暹罗基线SiamFC,SiamRPN和SiamMask的持续改进,可以验证其稳健性。除此之外,我们基于SiamRPN的模型在六个流行的跟踪基准测试中获得了最佳结果。虽然在跟踪过程中配备了在线模块,但我们的方法继承了暹罗基线的高效率,并且可以超越实时运行。 |
| Knowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding Authors Xuejing Liu, Liang Li, Shuhui Wang, Zheng Jun Zha, Li Su, Qingming Huang 弱监督引用表达基础REG旨在根据语言查询定位图像中的引用实体,其中图像区域提议与查询之间的映射在训练阶段是未知的。在引用表达式中,人们通常根据其与其他上下文实体的关系以及视觉属性来描述目标实体。然而,以前弱监督的REG方法很少关注实体之间的关系。在本文中,我们提出了一个知识引导的成对重建网络KPRN,它模拟目标实体主体和上下文实体对象之间的关系,并为这两个实体奠定了基础。具体来说,我们首先设计一个知识提取模块来指导主题和对象的提议选择。以每个提议与主题对象之间的特定形式的语义相似性获得先验知识。其次,在这些知识的指导下,我们设计了主题和对象注意模块来构建主题对象提议对。主题注意力排除了候选提案中不相关的提案。对象注意选择最合适的提议作为上下文提议。第三,我们引入成对注意和自适应加权方案来学习这些提议对与查询之间的对应关系。最后,成对重建模块用于测量弱监督学习的基础。对四个大型数据集进行的大量实验表明,我们的方法在很大程度上优于现有技术方法。 |
| Discriminative Video Representation Learning Using Support Vector Classifiers Authors Jue Wang, Anoop Cherian 用于视频中动作识别的最流行的深度模型生成短片的独立预测,然后以启发式方式汇集以将动作标签分配给完整视频片段。由于并非所有帧都可以表征基础动作,因此许多在多个动作中共同使用,对所有帧施加相同重要性的池化方案可能是不利的。为了解决这个问题,我们提出了判别性池化,基于这样一种观念,即在所有短片段中生成的深层特征中,至少有一个表征该动作。为了识别这些有用的特征,我们求助于由已知不相关的特征组成的负包,例如,它们是从与我们感兴趣的动作无关的数据集中采样的,或者是通过随机噪声作为输入产生的CNN特征。通过视频作为正面包的功能和作为负包的无关功能,我们设计了一个目标,即学习非线性超平面,在支持向量机设置中的多实例学习公式中将未知有用特征与其余特征分开。我们使用此分离超平面的参数作为完整视频片段的描述符。由于这些参数与最大边际框架中的支持向量直接相关,因此可以将它们视为来自袋的特征的加权平均汇集,对非支持向量赋予零权重。我们的汇集计划在深度学习框架内端到端训练。我们报告了八个计算机视觉基准数据集的实验结果,这些数据集涵盖了各种视频相关任务,并展示了这些任务的最新技术性能。 |
| Running Event Visualization using Videos from Multiple Cameras Authors Yeshwanth Napolean, Priadi Teguh Wibowo, Jan van Gemert 通过在比赛中的不同点收集的视频可视化多个跑步者的轨迹可以用于运动表现分析。视频和轨迹也可以帮助运动员健康监测。虽然跑步者的唯一ID和它们的外观是截然不同的,但是任务并不简单,因为视频数据不包含关于哪些跑步者出现在每个视频中的明确信息。跟踪运动员没有直接监督模型,只有过滤步骤才能删除不相关的检测。其他受关注的因素包括跑步者的阻塞和严酷的照明。为此,我们确定了两种方法,用于在事件的不同点识别跑步者,以确定他们的轨迹。一种是场景文本检测,其通过检测附着在其衣服上的唯一的号码识别跑步者,另一种是基于其外观检测跑步者的人物识别。我们训练我们的方法没有基本事实但是为了评估提出的方法,我们创建了一个地面实况数据库,其中包括跑步者出现的视频和帧间隔信息。在马拉松比赛期间,数据集中的视频由位于不同位置的九台摄像机记录。此数据使用每个视频中出现的跑步者号码进行注释。已知在框架中出现的跑步者的围兜数量用于过滤不相关的文本和检测到的数字。除了该滤波步骤之外,不使用监控信号。实验证据表明,场景文本识别方法达到了74分。结合两种方法,即使用文本识别器收集的样本来训练重新识别模型,得到更高的F1得分为85.8。重新训练具有识别的内点的人识别模型使得性能F1得分略有改善87.8。 |
| Image anomaly detection with capsule networks and imbalanced datasets Authors Claudio Piciarelli, Pankaj Mishra, Gian Luca Foresti 图像异常检测包括查找相对于一组正常数据具有异常,异常模式的图像。异常检测可以应用于几个领域,并且具有许多实际应用,例如,在工业检测,医学成像,安全执法等方面。异常检测技术通常仍然依赖于传统方法,例如一类支持向量机,而在现代深度学习方法的背景下,该主题尚未完全开发。在本文中,我们提出了一种基于胶囊网络的图像异常检测系统,假设异常数据可用于训练,但其数量很少。 |
| +++Video Interpolation and Prediction with Unsupervised Landmarks Authors Kevin J. Shih, Aysegul Dundar, Animesh Garg, Robert Pottorf, Andrew Tao, Bryan Catanzaro 长距离视频数据的预测和插值涉及对每个可见对象,遮挡和遮挡以及由于视点和光照引起的外观变化的运动轨迹建模的复杂任务。基于光流的技术概括但仅适用于短时间范围。许多方法选择将视频帧投影到低维潜在空间,从而实现长距离预测。然而,这些潜在的表征通常是不可解释的,因此难以操纵。这项工作将视频预测和插值作为无监督潜在结构推断,然后在该潜在空间中进行时间预测。潜在表示捕获前景语义而没有诸如关键点或姿势之类的明确监督。此外,由于每个界标可以被映射到指示语义部分位于何处的坐标,我们可以在坐标域内可靠地插值以实现可预测的运动插值。给定能够将这些界标映射回图像域的图像解码器,我们能够通过在界标表示空间上操作来实现高质量的远程视频插值和外推。 |
| +++Automatic Weight Estimation of Harvested Fish from Images Authors Dmitry A. Konovalov, Alzayat Saleh, Dina B. Efremova, Jose A. Domingos, Dean R. Jerry 在澳大利亚昆士兰州的三个不同地点收集了大约2,500个重量和相应的收获的Lates calcarifer亚洲海鲈或澳洲肺鱼的图像。对LinkNet 34分割卷积神经网络CNN的两个实例进行了训练。第一个是在200个手动分割的鱼面具上进行训练,其中排除了翅膀和尾巴。第二个是用100个全鱼面具训练的。将两个CNN应用于其余图像并自动生成分段掩模。来自区域模型的单因素和双因子简单数学权重被拟合在来自前两个位置的1072个区域权重对上,其中区域值是从自动分割的掩模中提取的。当应用于来自第三位置的1,400个测试图像时,单因子全鱼模型模型达到最佳平均绝对百分比误差MAPE,MAPE 4.36。还训练了来自图像回归CNN的直接权重,其中基于无鳍的CNN在具有MAPE 4.28的测试图像上表现最佳。 |
| Visual Semantic Reasoning for Image-Text Matching Authors Kunpeng Li, Yulun Zhang, Kai Li, Yuanyuan Li, Yun Fu 图像文本匹配一直是弥合视觉和语言领域的热门研究课题。它仍然具有挑战性,因为图像的当前表示通常缺乏全局语义概念,如在其相应的文本标题中。为了解决这个问题,我们提出了一个简单且可解释的推理模型来生成可视化表示,捕获场景的关键对象和语义概念。具体来说,我们首先在图像区域之间建立连接,并使用图形卷积网络执行推理,以生成具有语义关系的特征。然后,我们建议使用门和记忆机制对这些关系增强特征进行全局语义推理,选择判别信息并逐步生成整个场景的表示。实验验证了我们的方法为MS COCO和Flickr30K数据集上的图像文本匹配实现了新的技术水平。对于图像检索,它优于当前最佳方法6.8相对于使用1K测试集的MS COCO Recall 1上的字幕检索相对于4.8。在Flickr30K上,我们的模型将图像检索提高了12.6,相对于Recall 1提高了字幕检索。我们的代码可在 |
| Coarse2Fine: A Two-stage Training Method for Fine-grained Visual Classification Authors Amir Erfan Eshratifar, David Eigen, Michael Gormish, Massoud Pedram 小的类间和大的类内变化是细粒度视觉分类的主要挑战。来自不同类的对象共享视觉上相似的结构,并且同一类中的对象可以具有不同的姿势和视点。因此,正确提取有区别的局部特征,例如鸟嘴或车头灯是至关重要的。最近关于这个问题的大多数成功是基于可以定位和参与局部判别对象部分的注意力模型。在这项工作中,我们提出了一种视觉注意网络的训练方法,Coarse2Fine,它创建了从输入空间到有人值守特征图的可区分路径。 Coarse2Fine学习从有人值守的特征图到原始图像中的信息区域的逆映射函数,这将引导注意力图更好地参与细粒度特征。我们展示了Coarse2Fine,注意权重的正交初始化可以超越普通细粒度分类任务的现有技术精度。 |
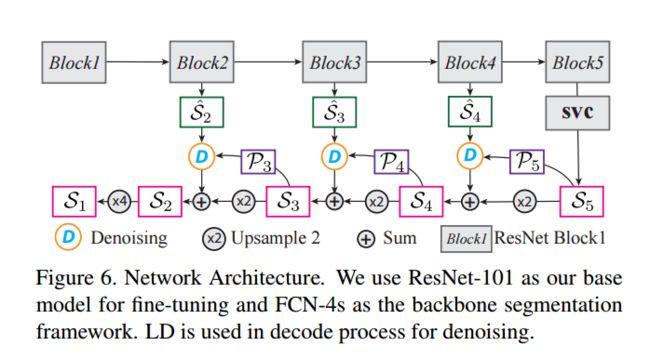
| ++++Semantic Correlation Promoted Shape-Variant Context for Segmentation Authors Henghui Ding, Xudong Jiang, Bing Shuai, Ai Qun Liu, Gang Wang 上下文对于语义分割至关重要。由于物体的形状多样及其在各种场景图像中的复杂布局,不同物体的场景的空间尺度和形状具有非常大的变化。因此,从预定义的固定区域聚合各种上下文信息是无效的或低效的。在这项工作中,我们建议为每个像素生成一个比例和形状变体语义掩码,以限制其上下文区域。为此,我们首先提出一种新的成对卷积来推断该对的语义相关性,并基于此生成形状掩模。使用上下文区域的推断空间范围,我们提出了形状变体卷积,其中感受场由形状掩模控制,该形状掩模随输入的外观而变化。以这种方式,所提出的网络从其语义相关区域而不是预定义的固定区域聚合像素的上下文信息。此外,这项工作还提出了一种标记去噪模型,以减少由嘈杂的低级特征引起的错误预测。在没有花里胡哨的情况下,所提出的分割网络在六个公共分割数据集上一致地实现了新的技术状态。 |
| Deep Iterative Frame Interpolation for Full-frame Video Stabilization Authors Jinsoo Choi, In So Kweon 视频稳定是高质量视频的基础和重要技术。之前的工作已广泛探索视频稳定,但其中大多数涉及裁剪帧边界并引入适度的失真水平。我们提出了一种新颖的视频稳定深度方法,可以生成没有裁剪和低失真的视频帧。所提出的框架利用帧内插技术在帧之间生成,从而减少帧间抖动。一旦以迭代方式应用,稳定效果变得更强。一个主要优点是我们的框架是以无人监督的方式端到端训练的。此外,我们的方法能够以近实时15 fps的速度运行。据我们所知,这是第一个提出无监督深度全帧视频稳定方法的工作。与现有技术方法相比,我们通过定量和定性评估显示了我们方法的优势。 |
| Multi-layer Domain Adaptation for Deep Convolutional Networks Authors Ozan Ciga, Jianan Chen, Anne Martel 尽管它们在许多计算机视觉任务中取得了成功,但卷积网络往往需要大量标记数据才能实现泛化。此外,如果网络在培训时未暴露于来自该域的类似样本,则无法保证在测试时来自未见域的样本的性能。这阻碍了在成像数据稀缺的临床环境中采用这些技术,并且数据的帧内和域间方差可能很大。我们提出了一种域自适应技术,该技术特别适用于深度网络,以减轻对标记数据的这种要求。我们的方法利用梯度反转层和Squeezeand Excite模块来稳定深层网络中的训练。所提出的方法应用于公众可获得的组织病理学和胸部X射线数据库,并且在具有和不具有域适应的现有技术网络中实现了优越的性能。根据应用,与2014年Ganin中引入的DANN相比,我们的方法可以将多级分类精度提高5 20。 |
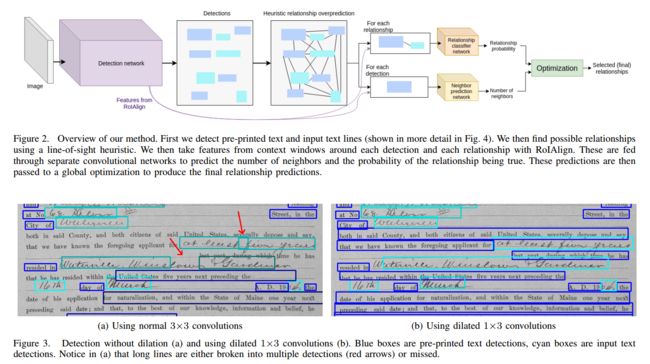
| ++++Deep Visual Template-Free Form Parsing Authors Brian Davis, Bryan Morse, Scott Cohen, Brian Price, Chris Tensmeyer 由于表单布局的多样性,从表单图像中自动地从模板中提取信息是具有挑战性的。由于噪音和退化,这对历史形式来说更具挑战性。提取过程的关键部分是将输入文本与预打印标签相关联。我们提供了一种学习的,无模板的解决方案,用于检测预打印文本和输入文本手写以及预测它们之间的配对关系。虽然以前解决这个问题的方法主要集中在干净的图像和清晰的布局上,但我们表明我们的方法在嘈杂,退化和变化的图像领域是有效的。我们在19世纪晚期,20世纪初引入了一个新的历史形式图像数据集,用于培训和验证我们的方法。我们的方法使用卷积网络来检测预打印文本和输入文本行。我们汇集来自检测网络的功能,以语言无关的方式对可能的关系进行分类。我们表明,我们提出的配对方法优于启发式规则,视觉特征对于获得高精度至关重要。 |
| ++++One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques Authors Vijay Arya, Rachel K. E. Bellamy, Pin Yu Chen, Amit Dhurandhar, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Q. Vera Liao, Ronny Luss, Aleksandra Mojsilovi , Sami Mourad, Pablo Pedemonte, Ramya Raghavendra, John Richards, Prasanna Sattigeri, Karthikeyan Shanmugam, Moninder Singh, Kush R. Varshney, Dennis Wei, Yunfeng Zhang 随着人工智能和机器学习算法进一步深入社会,这些算法的多个利益相关者的呼声越来越多,以解释他们的输出。与此同时,这些利益相关者,无论是受影响的公民,政府监管机构,领域专家还是系统开发人员,都对解释提出了不同的要求。为了满足这些需求,我们引入了AI Explainability 360 |
| Unsupervised Clustering of Quantitative Imaging Phenotypes using Autoencoder and Gaussian Mixture Model Authors Jianan Chen, Laurent Milot, Helen M. C. Cheung, Anne L. Martel 定量医学图像计算放射组学已被广泛应用于从医学图像建立预测模型。然而,过度拟合是传统放射学中的一个重要问题,其中大量放射学特征直接用于训练和测试预测基因型或临床结果的模型。为了解决这个问题,我们提出了一种无监督学习流水线,它由用于射线照相特征表示学习的自动编码器和基于最小消息长度准则的高斯混合模型组成。通过结合概率建模,已经考虑了疾病异质性。在108名患有结直肠癌肝转移的患者的机构MRI队列中评估了所提出的管道的性能。我们的方法能够自动选择最佳簇数并将患者分配成具有显着不同存活率的簇成像亚型。我们的方法优于其他无监督的聚类方法,这些聚类方法已用于放射性组学分析,并且具有与现有技术成像生物标记物相当的性能。 |
| Supervised Multimodal Bitransformers for Classifying Images and Text Authors Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, Davide Testuggine 诸如BERT之类的自监督双向变压器模型已经导致各种文本分类任务的显着改进。然而,现代数字世界越来越多模式,文本信息通常伴随着其他形式,如图像。我们引入了一种监督多模式位变换器模型,该模型融合了来自文本和图像编码器的信息,并获得了各种多模式分类基准任务的最新性能,优于强基线,包括专门用于测量多模态性能的硬测试集。 |
| Astroalign: A Python module for astronomical image registration Authors Martin Beroiz, Juan B. Cabral, Bruno Sanchez 我们提出了一个在astroalign Python模块中实现的算法,用于天文学中的图像配准。我们的模块不依赖于WCS信息,而是在图像上匹配3点星形三角形,以找到两者之间最准确的线性变换。在堆叠或执行差异图像分析之前对齐图像的情况下,它尤其有用。 Astroalign可以匹配不同点扩散函数,视觉和大气条件的图像。 |
| Blackbox Attacks on Reinforcement Learning Agents Using Approximated Temporal Information Authors Yiren Zhao, Ilia Shumailov, Han Cui, Xitong Gao, Robert Mullins, Ross Anderson 最近关于强化学习的研究表明,训练有素的特工容易受到恶意制作的对抗性样本的攻击。在这项工作中,我们展示了如何将针对RL代理的对抗样本从白盒子和灰盒子攻击推广到一个强大的黑盒子案例,即攻击者不了解代理人及其训练方法。我们使用序列对模型进行排序,以预测受过训练的代理人将要执行的单个操作或一系列未来操作。我们的近似模型基于来自代理的时间序列信息,成功预测了代理商未来的行为,在广泛的游戏和培训方法上始终高于80准确度。其次,我们发现尽管这种对抗性样本是可转移的,但它们并不优于随机高斯噪声作为降低训练的RL代理的游戏分数的手段。这凸显了先前关于此类药剂的工作中严重的方法学缺陷,应将随机干扰作为评估的基准。第三,我们确实发现了对抗性样本的新用途,在这种情况下,它们可以用来触发训练有素的特工在特定延迟后行为不端。这似乎是一种真正的新型攻击,它可能使攻击者使用由RL代理控制的设备作为定时炸弹。 |
| ACFM: A Dynamic Spatial-Temporal Network for Traffic Prediction Authors Lingbo Liu, Jiajie Zhen, Guanbin Li, Geng Zhan, Liang Lin 作为智能交通系统的关键组成部分,人流预测最近引起了人工智能AI领域的广泛研究兴趣,随着大规模交通移动数据的日益普及。其关键挑战在于如何整合时态规律和空间依赖性等多种因素来推断人群流动的演变趋势。为了解决这个问题,我们提出了一种称为Attentive Crowd Flow Machine ACFM的统一神经网络,它可以通过注意机制有效地学习人群流的空间时间特征表示。特别是,我们的ACFM由两个与卷积层相连的渐进式ConvLSTM单元组成。具体地,第一LSTM单元将正常的人群流动特征作为输入,并在每个时间步骤产生隐藏状态,其进一步馈送到连接的卷积层以用于空间注意力图推断。第二个LSTM单元旨在从注意加权的人群流动特征中学习动态空间时间表示。此外,我们开发了两个基于ACFM的深度框架,通过自适应地整合顺序和周期性数据以及其他外部影响来预测全市短期长期人群流动。对两个标准基准的广泛实验很好地证明了所提出的人群流量预测方法的优越性。此外,为了验证我们的方法的一般化,我们还应用定制的框架来预测乘客皮卡下降需求并在该交通预测任务中显示其优越的性能。 |
| Geolocation of an aircraft using image registration coupling modes for autonomous navigation Authors Nima Ziaei 本文提出研究固定翼飞机GPS系统的替代技术,利用集成在飞机中的腹侧单目摄像机的景观空中拍摄,并基于飞机地理定位目的的图像配准技术。不同类型的图像配准技术的使用存在相对注册和绝对注册。相对的一个能够通过知道飞机的图像1的位置和两个图像之间的重叠来从两个连续的空中拍摄中重新调整飞机的位置。绝对配准将实时空中拍摄与存储在数据库中的预先参考图像进行比较,并允许飞行器在将空中拍摄与数据库图像进行比较时进行地理定位。各种图像配准技术都有其自身的缺陷,使其无法单独用于飞机地理定位。本研究建议根据不同物理参数评估飞机速度,飞行高度,图像感兴趣点的密度,这些不同类型图像配准的耦合。最后,本研究还旨在量化一些图像配准性能,特别是其执行时间或漂移。 |
| Deep CNN frameworks comparison for malaria diagnosis Authors Priyadarshini Adyasha Pattanaik INTERMEDIA , Zelong Wang TSP , Patrick Horain INTERMEDIA 我们比较深度卷积神经网络DCNN框架,即AlexNet和VGGNet,用于分析大型,灰度,低质量和低分辨率显微图像中的健康和疟疾感染细胞,在这种情况下,只有一小部分训练集可用。实验结果在未染色图像中快速,自动和精确分类的路径上提供了有希望的结果。 |
| Deep Learning for Brain Tumor Segmentation in Radiosurgery: Prospective Clinical Evaluation Authors Boris Shirokikh, Alexandra Dalechina, Alexey Shevtsov, Egor Krivov, Valery Kostjuchenko, Amayak Durgaryan, Mikhail Galkin, Ivan Osinov, Andrey Golanov, Mikhail Belyaev 立体定向放射外科手术是一种针对大量颅内肿瘤患者的微创治疗选择。作为治疗治疗的一部分,准确描绘脑肿瘤非常重要。然而,在T1c MRI上逐片手动分割可能是耗时的,特别是对于多发转移和主观尤其是脑膜瘤。在我们的工作中,我们比较了几种深度卷积网络架构和训练程序,并评估了放射治疗部门针对三种脑肿瘤脑膜瘤,神经鞘瘤和多发脑转移瘤的最佳模型。开发的半自动分割系统将轮廓加工过程平均加速2.2倍,并将标记间协议从92增加到96.5。 |
| HNMTP Conv: Optimize Convolution Algorithm for Single-Image Convolution Neural Network Inference on Mobile GPUs Authors Zhuoran Ji 卷积神经网络广泛用于移动应用。然而,GPU卷积算法是针对小批量神经网络训练而设计的,移动GPU上的单图像卷积神经网络推理算法尚未得到很好的研究。在讨论了使用差异并检查现有的卷积算法之后,我们提出了HNTMP卷积算法。据我们所知,HNTMP卷积算法比最流行的textit im2col卷积算法实现了14.6倍的加速,并且比最快的现有卷积算法直接卷积算法加速了2.1倍。 |
| A new operation mode for depth-focused high-sensitivity ToF range finding Authors Sebastian Werner, Henrik Sch fer, Matthias Hullin 我们介绍了脉冲相关飞行时间PC ToF传感,这是一种新的飞行距离传感器相关时间操作模式,它将亚纳秒激光脉冲源与传感器侧的矩形解调相结合。与之前的工作相比,我们提出的测量方案试图在整个测量过程中不优化深度精度。使用PC ToF,我们用标准C ToF设置的全局灵敏度来交换具有强烈局部化高灵敏度的测量,我们大大提高了采集的深度分辨率场景特征围绕期望的兴趣深度。使用真实世界的实验,我们表明我们的技术能够使用低至10MHz的调制频率和低至1mW的光功率实现低至2mm的深度分辨率。这使得PC ToF特别适用于低功率应用。 |
| Eelgrass beds and oyster farming at a lagoon before and after the Great East Japan Earthquake 2011: potential to apply deep learning at a coastal area Authors Takehisa Yamakita 沿海地区有少量自动土地覆盖分类的案例研究。在这里,我通过比较手动追踪,简单的图像分割和使用深度学习的图像变换来测试日本宫城县Mangoku ura Lagoon的海草床,沙地,牡蛎养殖筏的提取。结果用于提取地震和海啸之前和之后的变化。在图像变换方法中输出分辨率最佳,通过使用独立测试数据上的随机点评估,显示了超过69个植被分类准确度。通过分割模型检测牡蛎养殖筏的分布。通过人工跟踪和图像变换结果评估地震前后的变化,发现沙区面积增加,植被减少。通过分割模型,仅检测到牡蛎养殖的减少。这些结果证明了在地震和海啸之后提取这些元素的空间格局的潜力。 2011年东日本大地震,土地利用土地覆盖LULC,Zosteracea海草,养殖牡蛎,深度学习,Mangoku Bay |
| Invisible Backdoor Attacks Against Deep Neural Networks Authors Shaofeng Li, Benjamin Zi Hao Zhao, Jiahao Yu, Minhui Xue, Dali Kaafar, Haojin Zhu 深度神经网络DNN已被证明易受后门攻击,其中隐藏的特征模式训练为正常模型,并且仅由称为触发器的某些特定输入激活,欺骗模型产生意外行为。在本文中,我们设计了一个优化框架来创建后门攻击的隐蔽和分散触发器,textit隐形后门,其中触发器可以放大特定的神经元激活,同时对后门检测方法和人工检查都不可见。我们使用感知对抗性相似性得分PASS引用rozsa2016adversarial来定义人类用户的隐身性,并将L 2和L 0正则化应用于优化过程以隐藏输入数据中的触发器。我们通过测量它们的攻击成功率和隐形得分,表明所提出的隐形后门在各种DNN模型以及三个数据集CIFAR 10,CIFAR 100和GTSRB中都相当有效。 |
| A Baseline for Few-Shot Image Classification Authors Guneet S. Dhillon, Pratik Chaudhari, Avinash Ravichandran, Stefano Soatto 对标准交叉熵损失训练的深度网络进行微调是少数镜头学习的强大基线。当进行微调时,其性能优于标准数据集,如Mini Imagenet,Tiered Imagenet,CIFAR FS和FC 100,具有相同的超参数。这种方法的简单性使我们能够在Imagenet 21k数据集上演示前几个镜头学习结果。我们发现,即使对于大量的测试类,使用大量的元训练课也会导致很少的射击精度。我们并不主张我们的方法作为少数镜头学习的解决方案,而只是使用结果来突出当前基准测试的限制和很少的镜头协议。我们对基准数据集进行了广泛的研究,以提出量化测试事件硬度的指标。该度量可用于以更系统的方式报告少数镜头算法的性能。 |
| Intensity augmentation for domain transfer of whole breast segmentation in MRI Authors Linde S. Hesse, Grey Kuling, Mitko Veta, Anne L. Martel 从胸壁分割乳房是分析乳房磁共振图像的重要的第一步。已经示出3D网络获得高分割精度,并且当在一种扫描仪类型上训练并且在另一扫描仪上测试时看起来很好地概括,只要使用非常类似的T1加权MR协议。然而,当训练集和看不见的测试集之间的图像强度或患者取向显着不同时,解决域适应问题的工作很少。为了克服域移位,我们建议在训练期间除了几何增强之外还应用广泛的强度增强。我们探讨了样式转换和新颖的强度重映射方法作为强度增强策略。对于我们的实验,我们在T1加权扫描上训练3D U网并在T2加权扫描上进行测试。通过应用强度增强,我们从DSC的0.71到0.90增加了分割性能。该性能非常接近T2加权扫描0.92的训练和测试的基线性能。此外,我们将网络应用于一个独立的测试装置,该测试装置由使用T1加权TWIST序列和不同线圈配置获得的公共扫描组成。在该数据集上,我们获得了0.89的性能,接近于地面实况分割0.92的观察者间变异性。我们的结果表明,除了几何增强之外,使用强度增强是克服强度域移位的合适方法,并且我们期望它对于广泛的分割任务是有用的。 |
| DeepEvolution: A Search-Based Testing Approach for Deep Neural Networks Authors Houssem Ben Braiek, Foutse khomh 越来越多的深度学习DL模型包含在自动驾驶汽车等安全关键系统中,这导致了基于多种模型的DL测试技术的发展。这些测试技术的一个共同点是自动生成测试用例,例如,从原始训练数据转换的新输入,目的是优化一些测试充分性标准。到目前为止,这些方法的有效性受到了依赖于随机模糊测试或转换的阻碍,这种模糊测试或转换并不总能产生具有良好多样性的测试用例。为了克服这些限制,我们提出DeepEvolution,一种基于搜索的新方法,用于测试依赖于元启发式的DL模型,以确保生成的测试用例具有最大的多样性。我们评估了DeepEvolution在测试计算机视觉DL模型中的有效性,发现它显着增加了生成的测试用例的神经元覆盖率。此外,使用DeepEvolution,我们可以成功找到几个角落案例行为。最后,DeepEvolution在Tensorfuzz上的表现优于Google Brain开发的覆盖引导模糊测试工具,用于检测模型量化过程中引入的潜在缺陷。这些结果表明,基于搜索的方法可以帮助为DL系统构建有效的测试工具。 |
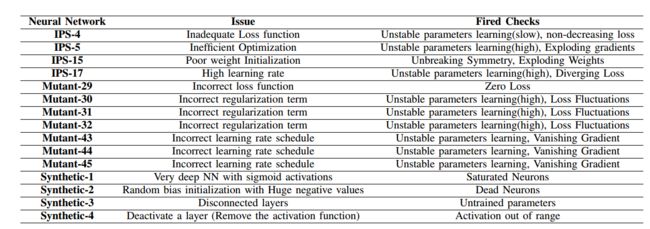
| TFCheck : A TensorFlow Library for Detecting Training Issues in Neural Network Programs Authors Houssem Ben Braiek, Foutse Khomh 机器学习ML模型越来越多地应用于自动驾驶汽车等安全关键系统,这导致了多种基于模型的ML测试技术的发展。这些测试技术的一个共同点是他们假设培训计划充足且没有错误。这些技术仅侧重于使用手动标记的数据或自动生成的数据来评估构建的模型的性能。但是,他们对培训计划的假设并不总是正确的,因为培训计划可能包含不一致和错误。在本文中,我们检查ML程序中的培训问题,并提出可用于自动检测已识别问题的验证例程目录。我们在名为TFCheck的基于Tensorflow的库中实现了这些例程。使用TFCheck,从业者可以自动检测上述问题。为了评估TFCheck的有效性,我们进行了一个案例研究,包括现实世界,突变体和综合培训计划。结果表明,TFCheck可以成功检测ML代码实现中的训练问题。 |
| DurIAN: Duration Informed Attention Network For Multimodal Synthesis Authors Chengzhu Yu, Heng Lu, Na Hu, Meng Yu, Chao Weng, Kun Xu, Peng Liu, Deyi Tuo, Shiyin Kang, Guangzhi Lei, Dan Su, Dong Yu 在本文中,我们提出了一种通用且强大的多模态合成系统,可同时产生高度自然的语音和面部表情。该系统的关键组成部分是持续时间知情注意网络DurIAN,这是一种自回归模型,其中输入文本和输出声学特征之间的对齐是从持续时间模型推断出来的。这与所使用的端到端注意机制不同,并且在现有的端到端语音合成系统(例如Tacotron)中考虑了各种不可避免的伪像。此外,Durian可用于生成高质量的面部表情,其可与生成的语音同步而无需并行语音和面部数据。为了提高语音生成的效率,我们还提出了基于WaveRNN模型的多波段并行生成策略。所提出的多波段WaveRNN有效地将总计算复杂度从9.8降低到5.5 GFLOPS,并且能够在单个CPU核心上生成比实时快6倍的音频。我们表明,DurIAN可以产生高度自然的语音,与当前最先进的端到端系统相当,同时避免在这些系统中跳过重复错误的单词。最后,介绍了一种简单而有效的方法,用于细粒度控制语音和面部表情的表现力。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from huawei