WGAN学习笔记
WGAN学习笔记
刚刚接触深度学习三个月的小白,从现在开始记录自己的学习过程,希望各位能提出一些宝贵的意见。。
Wasserstein GAN
一、Introducion
无监督学习
如何学习一个可能的分布?学习一个density,通过定义一个参数densities,找到可以最大化似然我们数据的Pθ(θ是R中的d维向量)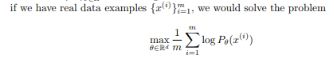
如果真实数据是分布Pr ,Pθ是参数密度分布,目的就是要最小化KL(Pr||Pθ)
但KL distance 很容易逼近无穷大。
通常的解决办法是add 一个噪声约束model的分布,这就是为什么实际上所有的生成模型都include a noise component.最简单的情况是假设一个高带宽的高斯噪声去覆盖所有的example,但是噪声的存在降低了sample的质量(make them blurry-模糊)比如recent paper23中…噪声的数量很大,(这一块我没太明白,也没有深究)
定义Z服从分布p(z),并定义映射gθ:Z→X,生成sample服从分布Pθ,通过改变θ可以改变分布,并且使它接近于真实数据的分布Pr。VAEs和GAN都是用这种方法。GAN在目标函数的定义上更加具有灵活性,including 所有F散度和exotic combinations
#f散度:用来衡量两个概率密度p和q的区别,也就是衡量这两个分布的相似程度

我们的重点是去衡量生成模型的分布与真实数据的分布之间的差距,或者说如何定义一个距离去衡量。为了优化参数ϴ,希望定义模型的分布Pθ,使得映射Pθ连续,也就是当ϴt趋近于ϴ,Pϴt趋近于Pθ。然而,分布Pθt是否收敛取决于我们计算这两个分布之间的距离的方式,distance越weaker,越容易找到一个ϴ空间到Pθ空间的映射,因为这样有利于分布的收敛。如果我们定义ρ是两个分布之间的distance,我们应该找到一个损失函数。
这篇文章的贡献主要有:
在section2,我们提供了一种理论分析,对于EM距离的表现和几种流行的可能的距离和散度对比
在section3,定义了Wasserstein GAN最小化EM距离
在section4,我们展示了WGAN解决了GAN在训练中的问题。在训练WGAN的时候不需要在生成器和判别器之间保持一种极度小心的平衡,也不需要一种十分谨慎的网络结构设计,在GAN中的的moda dropping现象也得到改善,WGAN最优点在于,在训练判别器至最优的过程中能够连续评估EM距离。
二、Different Distance
Χ是一个紧集,∑代表χ的所有波伊尔子集,Prob(χ)代表the space of probability measures defined onχ,定义:


(sup上确界,inf下确界)
γ(x,y)意思是要使分布Pr转换成Pg,x对应于y的变化。EM距离就是最优的转换计划的损失。
Example1
例1证明了was距离(即EM距离)相比于JS,KL,TV距离的优越性。并且W(Pθ,P0)是一个在θ上连续的损失函数
Theorem1
讲了最小化EM距离在神经网络中是可行的,比JS散度更好,这几种距离or散度由强到弱依次是:KL,JS,TV,EM是最弱的
Theorem2
讲了在高维度上,JS,KL,TV,Was距离都趋近于0,即都可以做cost,但是在low dimensional manifolds只有Was距离合适
三、Wasserstein GAN
推论2证明了W(Pr,Pθ)比JS更好优化,但是下确界难以控制。 KRduality告诉我们,
![]() 在K维Lipschitz连续上,对某些K,我们要解决大的问题就是:
在K维Lipschitz连续上,对某些K,我们要解决大的问题就是:
![]()
如果上确界对某些w∈W可以得到(一种非常强的相似假设当证明评估的一致性的时候),这个过程会产生一个W(Pr,Pθ)的calulation up to a 增加的constant。
推论3
让Pr是任何可能的分布,Pθ是gθ(Z)的分布,Z是随机变量,密度是p,gθ是一个符合假设1的函数,
(证明在附录C)
现在要找到函数f并解决最大值问题
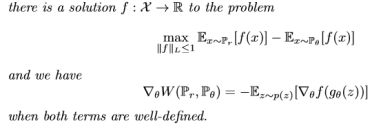
我们要训练一个参数化的神经网络with权重w在紧空间W中,通过反向传播,就像在GAN中一样。W is compact implies that 所有函数fw对于只依赖于W而不是单独权重的K都K-Lipschitz, 为了有存在于紧空间中的参数w,我们可以做的就是在每次梯度更新后约束权重到一个固定范围内,(比如W=[-0.01,0.01]l)
Weight clipping是一个强迫Lipschitz约束的糟糕的方法。如果clipping参数太大,就会花很长时间去训练,若clipping太小,当层数较深时会梯度消失,or BN层没用到

EM距离是连续可微的,训练判别器越多,我们可以得到更可靠的梯度 of Was距离(WAS几乎处处可微。JS散度会出现梯度消失。GAN的生成器学习去鉴别真实图片和生成图片非常迅速,and provide no reliable gradients information,WGAN的critic,不会饱和,且处处有明确的梯度。事实就是我们约束函数限制函数的增长 使其在不同的空间中维持线性,强迫最优的critic有这个行为。(?)
或许更重要的是,在训练critic至最优的过程中不会出现模态坍塌(moda collapse), This is due to the fact that mode collapse comes from the fact that the optimal generator for a fixed discriminator is a sum of deltas on the points the discriminator assigns the highest values, as observed by [4] and highlighted in [11].
WGAN梯度处处明晰
四、实证结果
两点主要benefits:
a.更好的损失度量方法,与生成器的收敛性和样本质量相关联
b.提高了优化过程的稳定性
4.1 实验进程
目标分布学习的是LSUN-BEDROOMS,基线对照是DCGAN,生成样本是3通道 64X64,用了A1中的超参数
4.2有意义的损失度量
因为WGan演示算法尝试训练critic f well before 每一个生成器更新,损失函数是估计的EM距离。
第一个实验说明了估计距离和生成样本质量的相关性,除了DCGAN,还跑了修改了生成器or生成器判别器都修改的(by 4-layer ReLU-mlp with 512个隐藏单元。训练曲线和样本在不同时期的训练表现,在lower errors和高样本质量之间有明显的相关性。
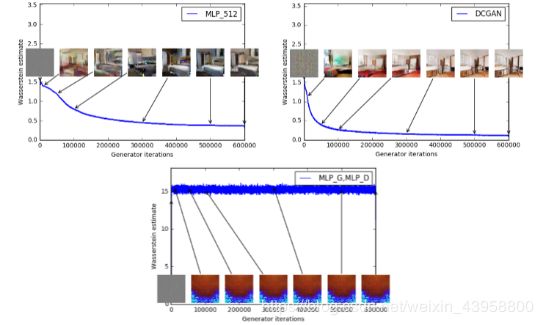
上左:生成器 MLP ,4个隐藏层,每层512单元。随着训练过程,loss连续不断的降低,伴随着样本质量的提升。上右,生成器是DCGAN,loss降低得非常快,图片质量也有提升,这两种的critic都是没有sigmoid的DCGAN所以loss可以做比较。下面的图:生成器和判别器都是MLPs ,高学习率(所以训练失败),损失和样本都是constant,曲线通过中值滤波( median filter)
中值滤波:中值滤波法是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值。
图三展示了通过三种结构训练的WGAN通过EM距离的评估
据我们所知,这是第一次GAN作品的这样一种特性的展示,即GAN的损失函数展示了其收敛性。这种特性是极其有用的,This property is extremely useful when doing research in adversarial networks as one does not need to stare at the generated samples to figure out failure modes and to gain information on which models are doing better over others。
然而我们并不是声称这是评估生成模型的新方法,The constant scaling factor that depends on the critic’s architecture means it’s hard to compare models with different critics连续不断的缩放因子依赖于critic的结构,意味着用不同的critic很难比较模型。并且critic没有确定的容量,这使得我们很难根据EM距离的远近得知我们的真实距离是多少。也就是说,我们成功的运用这个loss量度去证实我们实验在不失败前提下的可重复性,这是在训练GANs时一个巨大的提升,以前的GANs没有这种能力。
图四是训练GAN过程中的JS散度,在训练GANs期间,生成器就是去最大化which is is a lower bound of 2JS(Pr, Pθ)−2 log 2. In the figure, we plot the quantity 1/2 L(D, gθ) + log 2, which is a lower bound of the JS distance

图:JS 上左:一个MLP生成器 上右:一个DCGAN生成器,都是用标准GAN过程训练,都有一个DCGAN判别器,两张图的错误率都有提升,右图样本变得更好但是JS散度升高或保持不变,样本质量和loss之间没有直接的相关性。下图:生成器和判别器都是MLP,曲线不停的上升和下降,和图片质量无关。所有的曲线都经过了相同的中值滤波。
这些图片表明,随着图片质量的变化,。JS散度常常保持不变或者上升而不是下降。实际上JS散度保持在接近于log2约等于0.69,也是JSdistance的最大值。也就是说JSdistance饱和了,判别器的loss是0,生成器有时meaningful,有时出现模态坍塌。
当用高学习率,或者 uses a momentum based optimizer such as Adam [8] (with β1 > 0)
on the critic,WGAN训练会变得不稳定,所以我们用RMSProp优化。
4.3提升稳定性
WGAN的一个优点是允许我们训练critic直到稳定
后面没怎么看。。。