Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning 深入了解半监督学习的图卷积网络GCN
文章目录
- 1 简介
- 2 相关工作
- 2.1 Graph-Based Semi-Supervised Learning 基于图的半监督学习
- 2.2 Graph Convolutional Networks 图卷积网络
- 2.3 Semi-Supervised Classification with GCNs 用GCN进行半监督节点分类
- 3 分析
- 3.1 Why GCNs Work ?
- Laplacian Smoothing
- Multi-layer Structure
- 3.2 When GCNs Fail ?
- 4 解决方案
- 4.1 Co-Train a GCN with a Random Walk Model 用随机游走模型和GCN协同训练
- 4.2 GCN Self-Training GCN的自训练
- Combine Co-Training and Self-Training
- 训练一个比较好的GCN分类器需要多少标签数据?
- 5 实验
- 5.1 Experimental Setup
- 5.2 Results Analysis
- Comparison with GCNs 和GCNs的对比
- Comparison with other methods 和其他方法的对比
- Influence of the Parameters 参数的影响
- Computational Cost 计算代价
- 6 小结
论文题目:Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning 深入了解半监督学习的图卷积网络
作者:来自香港理工大学的Qimai Li, Zhichao Han, Xiao-Ming Wu等人
时间:2018
期刊:AAAI
论文链接:https://arxiv.org/abs/1801.07606
这篇论文比较有趣,是关于图卷积网络应用在半监督学习方面的深度见解,为图卷积网络的理解提供了独特的视角。主要针对于GCN堆叠过多后,分类效果变差的问题。作者分析了一下为什么会变差,主要是因为 GCN 的本质实际上是对每个结点的邻居特征和自身特征做线性组合,权重和邻接矩阵相关,所以对于顶点分类问题来说,如果堆得层数多了,就会让一个结点的特征聚合越来越多邻居的特征,让大家都变得相似,从而使得类间的相似度增大,自然分类效果就差了。为了解决这个问题,作者提出了两个解决办法,使用co-training和self-training方法来训练 GCNs。
1 简介
众所周知,深度学习模型一般需要大量的标记数据,在很多标记训练数据代价很大的场景就无法满足这样的要求。为了减少用于训练的数据的数量,最近的研究开始关注 few-shot learning (Lake, Salakhutdinov, and Tenenbaum 2015; Rezende et al. 2016)——从每个类只有很少的样本中学习一个分类模型。和 few-shot learning 相近的是半监督学习,其中有大量的未标记样本可以用来和很少量的标记样本一起用于训练。
很多研究者已经证实了如果使用恰当,在训练中利用未标记样本可以显著地提升学习的精度 (Zhu and Goldberg 2009)。提高样本分类精度的关键问题是最大化未标记样本的结构和特征信息的有效利用。近些年,由于强大的特征抽取能力和深度学习的成功,已经有很多人使用基于神经网络的方法处理半监督学习,包括ladder network (Rasmus et al. 2015), semi-supervised embedding (Weston et al. 2008),planetoid (Yang, Cohen, and Salakhutdinov 2016),GCN (Kipf and Welling 2017)。
最近发展的图卷积神经网络 (GCNNs) (Defferrard, Bresson, and Vandergheynst 2016) 是一个将欧氏空间中使用的卷积神经网络 (CNNs) 泛化到对图结构数据建模的成功尝试。Kifp and Welling (2017)提出了一个 GCNNs 的简化类型,称为图卷积网络 (GCNs),应用于半监督分类。GCN 模型很自然地将图结构数据的连接模式和特征集成起来,而且比很多 state-of-the-art 方法在 benchmarks 上好很多。尽管如此,它也有很多其他基于神经网络的模型遇到的问题。用于半监督学习的 GCN 模型的工作机理还不清楚,而且训练 GCNs 仍然需要大量的标记样本用于调参和模型选择,这就和半监督学习的理念相违背。
在这篇论文的目的在于弄清楚了用于半监督学习的 GCN 模型。
GCN 模型中的图卷积是拉普拉斯平滑的一种特殊形式,这种平滑操作可以聚合一个顶点和它周围顶点的特征,使得同一类簇内顶点的特征相似,因此使分类任务变得简单,这使为什么 GCNs 表现的这么好的关键原因。然而,这也会带来 over-smoothing 的问题。如果 GCN 有很多卷积层后变深了,那么输出的特征可能会变得过度平滑,且来自不同类簇的顶点可能变得无法区分。这种聚合在小的数据集且只有很少的卷积层时,发生的很快,如图2所示。而且,给 GCN 模型增加更多的层也会使它变得难以训练。
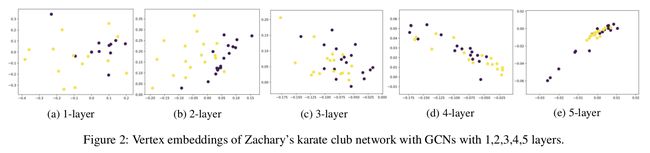
- 上图是GCN在空手道俱乐部数据集上层数为1,2,3,4,5层时顶点的embedding生成示意图
- 可以看出层数越多,顶点的embedding更难区分,网络分类效果变差
然而,即使是像 Kipf & Welling 2017 使用的两层 GCN 这样的浅层的 GCN 模型也有它自身的限制。除此以外它还需要很多额外的标签数据来验证,它也会遇到卷积核局部性等问题。当只有少数标签的数据的时候,一个浅层的 GCN 模型不能有效的将标签传播到整个图上。如图1所示,即使有500个额外标记用来验证,GCNs 的表现会随着训练size的减少急速下降。
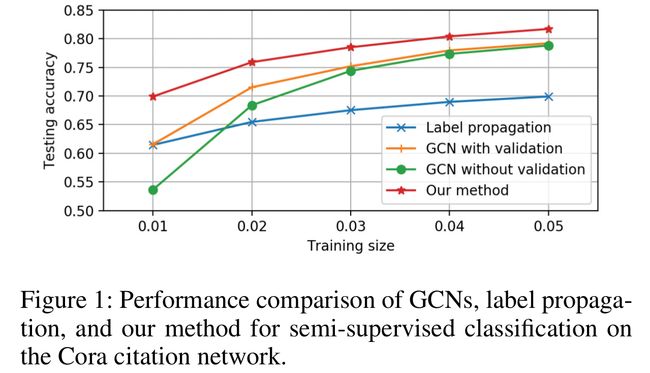
- 上图是Cora数据集上不同GCN方法性能对比
为了克服限制并实现 GCN 模型的全部潜能,文中提出了一种co-training方法和self-training方法来训练 GCNs。通过使用随机游走模型来协同训练一个 GCN,随机游走模型可以补充 GCN 模型在获取整个图拓扑结构上的能力。通过自训练一个 GCN,可以挖掘它的特征提取能力来克服它的局部性(localized nature)。融合协同训练和自训练方法可以从本质上提升 GCN 模型在只有少量标记的半监督学习的效果,而且使它不用使用额外的标记样本用来验证。如图1所示,此文的方法比 GCNs 好了很多。
总而言之,这篇论文的关键创新有:
- 对半监督学习的 GCN 模型提供了新的视角和新的分析
- 提出了对半监督学习的 GCN 模型提升的解决方案
2 相关工作
首先,定义一些符号
- 图表示为 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E)
- V \mathcal{V} V 是顶点集, ∣ V ∣ = n \vert \mathcal{V} \vert = n ∣V∣=n, E \mathcal{E} E 是边集。在这篇论文中,考虑的是无向图。
- A = [ a i j ] ∈ R n × n A = [a_{ij}] \in \mathbb{R}^{n \times n} A=[aij]∈Rn×n 是邻接矩阵,且为非负的
- D = d i a g ( d 1 , d 2 , … , d n ) D = \mathrm{diag}(d_1, d_2, …, d_n) D=diag(d1,d2,…,dn) 表示度矩阵, d i = ∑ j a i j d_i = \sum_j a_{ij} di=∑jaij 是顶点 i i i 的度
- 图拉普拉斯矩阵 (Chung 1997) 定义为 L : = D − A L := D - A L:=D−A,归一化的图拉普拉斯矩阵的两个版本分别定义为: L s y m : = D − 1 2 L D − 1 2 L_{sym} := D^{-\frac{1}{2}} L D^{-\frac{1}{2}} Lsym:=D−21LD−21 和 L r w : = D − 1 L L_{rw} := D^{-1}L Lrw:=D−1L。
2.1 Graph-Based Semi-Supervised Learning 基于图的半监督学习
这篇论文中考虑的问题是图上的半监督分类任务。给定一个图 G = ( V , E , X ) \mathcal{G} = (\mathcal{V}, \mathcal{E}, X) G=(V,E,X),其中 X = [ x 1 , x 2 , … , x n ] T ∈ R n × c X = \mathrm{[x_1, x_2, …, x_n]^T} \in R^{n \times c} X=[x1,x2,…,xn]T∈Rn×c 是特征矩阵, x i ∈ R c \mathrm{x}_i \in R^c xi∈Rc 是顶点 i i i 的 c c c 维特征向量。假设给定了一组顶点 V l \mathcal{V}_l Vl 的标记,目标是预测其余顶点 V u \mathcal{V}_u Vu 的标记。
基于图的半监督学习在过去的二十年成为了一个流行的研究领域。通过挖掘图或数据的流形结构,是可以通过少量标记进行学习的。很多基于图的半监督学习方法形成了类簇假设 (cluster assumption) (Chapelle and Zien 2005),假设了一个图上临近的顶点倾向于有共同的标记。顺着这条路线的研究包括 min-cuts (Blum and Chawla 2001) 和 randomized min-cuts (Blum et al. 2004),spectral graph transducer (Joachims 2003),label propagation (Zhu, Ghahramani, and Lafferty 2003) and its variants (Zhou et al. 2004; Bengio, Delalleau, and Le Roux 2006),modified adsorption (Talukdar and Crammer 2009),还有 iterative classification algorithm (Sen et al. 2008)。
但是图只表示数据的结构信息。在很多应用,数据的样本是以包含信息的特征向量表示,而不是在图中表现。比如,在引文网络中,文档之间的引用链接描述了引用关系,但是文档是由 bag-of-words 向量表示的,这些向量描述的内容是文档的内容。很多半监督学习方法寻求对图结构和数据的特征属性共同建模。一个常见的想法是使用一些正则项对一个监督的学习器进行正则化。比如,manifold regularization (LapSVM) (Belkin, Niyogi, and Sindhwani 2006) 使用一个拉普拉斯正则项对 SVM 进行正则化。Deep semi-supervised embeddin (Weston et al. 2008) 使用一个基于embedding的正则项对深度神经网络进行正则化。Planetoid (Yang, Cohen, and Salakhutdinov 2016) 也通过共同地对类标记和样本的上下文预测对神经网络进行正则化。
2.2 Graph Convolutional Networks 图卷积网络
图卷积神经网络 (GCNNs) 将传统的卷积神经网络泛化到图域中。主要有两类 GCNNs (Bronstein et al. 2017): spatial GCNNs 和 spectral GCNNs。空间 GCNNs 将卷积看作是 “patch operator”,对每个顶点使用它的邻居信息构建新的特征向量。
接下来介绍的都是谱域GCN的内容,详见:Semi-Supervised Classification with Graph Convolutional Networks用图卷积进行半监督分类
最后的GCN公式为
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) Θ ( l ) ) (4) \tag{4} H^{(l + 1)} = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} \Theta^{(l)}) H(l+1)=σ(D~−21A~D~−21H(l)Θ(l))(4)
其中
- H ( l ) H^{(l)} H(l)是第 l l l层的激活值矩阵, H ( 0 ) = X H^{(0)} = X H(0)=X
- Θ ( l ) ∈ R c × f \Theta^{(l)} \in \mathcal{R}^{c \times f} Θ(l)∈Rc×f是第 l l l层的可训练的权重矩阵
- σ \sigma σ是激活函数,比如 R e L U ( ⋅ ) = m a x ( 0 , ⋅ ) ReLU(\cdot) = max(0, \cdot) ReLU(⋅)=max(0,⋅)
2.3 Semi-Supervised Classification with GCNs 用GCN进行半监督节点分类
在 Kipf and Welling 2017 中,GCN 模型以一种优雅的方式做半监督分类任务。模型是一个两层 GCN,在输出时使用一个 softmax:
Z = s o f t m a x ( A ^ R e L U ( A ^ X Θ ( 0 ) ) Θ ( 1 ) ) (5) \tag{5} Z = \mathrm{softmax}(\hat{A} ReLU (\hat{A} X \Theta^{(0)}) \Theta^{(1)} ) Z=softmax(A^ReLU(A^XΘ(0))Θ(1))(5)
其中
- A ^ = D ~ − 1 2 A ~ D ~ − 1 2 \hat{A} = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} A^=D~−21A~D~−21
- s o f t m a x ( x i ) = 1 Z e x p ( x i ) \mathrm{softmax}(x_i) = \frac{1}{\mathcal{Z}} exp(x_i) softmax(xi)=Z1exp(xi)
- Z = ∑ i e x p ( x i ) \mathcal{Z} = \sum_i exp(x_i) Z=∑iexp(xi)
损失函数是所有标记样本上的交叉熵:
L : = − ∑ i ∈ V l ∑ f = 1 F Y i f l n Z i f (6) \tag{6} \mathcal{L} := - \sum_{i \in \mathcal{V}_l} \sum^F_{f=1} Y_{if} \mathrm{ln} Z_{if} L:=−i∈Vl∑f=1∑FYiflnZif(6)
其中
- V l \mathcal{V}_l Vl是标记顶点的下标
- F F F是输出特征的维数,等价于类别数
- Y ∈ R ∣ V l ∣ × F Y \in \mathcal{R}^{\vert \mathcal{V}_l \vert \times F} Y∈R∣Vl∣×F 是标记矩阵
- 权重参数 Θ ( 0 ) \Theta^{(0)} Θ(0) 和 Θ ( 1 ) \Theta^{(1)} Θ(1)可以通过梯度下降训练
GCN 模型在卷积中自然地融合了图的结构和顶点的特征,未标记的顶点的特征和临近的标记顶点的混合在一起,然后通过多个层在网络上传播。GCNs 在 Kipf & Welling 2017 中比很多 state-of-the-art 方法都好很多,比如在引文网络上。
3 分析
尽管GCN的性能很好,但是用于半监督学习的 GCN 模型的机理还没有弄明白。在这部分为分析GCN 模型为什么好用,并指出它的限制。
3.1 Why GCNs Work ?
此节证明了图卷积是一种特殊形式的拉普拉斯平滑。
将 GCN 和最简单的全连接神经网络 (FCN) 进行比较,传播规则是:
H ( l + 1 ) = σ ( H ( l ) Θ ( l ) ) (7) \tag{7} H^{(l + 1)} = \sigma(H^{(l)} \Theta^{(l)}) H(l+1)=σ(H(l)Θ(l))(7)
GCN 和 FCN 之间的唯一的一个区别是图卷积矩阵 A ^ = D ~ − 1 2 A ~ D ~ − 1 2 \hat{A} = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} A^=D~−21A~D~−21 用在特征矩阵 X X X的左边。在 Cora 数据集上,每类 20 个 标签,做了半监督分类的测试。如表1所示。即便是只有一层的 GCN 也比一层的 FCN 好很多。

Laplacian Smoothing
考虑一个一层的 GCN。实际有两步:
- 从矩阵 X X X通过一个图卷积得到新的特征矩阵 Y Y Y:
Y = D ~ − 1 2 A ~ D ~ − 1 2 X (8) \tag{8} Y = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}X Y=D~−21A~D~−21X(8)
- 将新的特征矩阵 Y Y Y放到一个全连接层。很明显,图卷积是性能提升的关键。
下面来检测一下图卷积。假设给图中的每个结点增加一个自连接,新的图的邻接矩阵就是 A ~ = A + I \tilde{A} = A + I A~=A+I。输入特征的每个通道的拉普拉斯平滑 (Taubin 1995,Spectral graph theory) 定义为:
y ^ i = ( 1 − γ ) x i + γ ∑ j a ~ i j d i x j ( for 1 ≤ i ≤ n ) (9) \tag{9} \hat{\mathrm{y}}_i = (1 - \gamma) \mathrm{x}_i + \gamma \sum_j \frac{\tilde{a}_{ij}}{d_i} \mathrm{x}_j \quad (\text{for} \quad 1 \leq i \leq n) y^i=(1−γ)xi+γj∑dia~ijxj(for1≤i≤n)(9)
其中
- 0 < γ < 1 0 < \gamma < 1 0<γ<1是控制当前结点的特征和它的邻居的特征之间的权重
可以将拉普拉斯平滑写成矩阵形式:
Y ^ = X − γ D ~ − 1 L ~ X = ( I − γ D ~ − 1 L ~ ) X (10) \tag{10} \hat{Y} = X - \gamma \tilde{D}^{-1} \tilde{L} X = (I - \gamma \tilde{D}^{-1} \tilde{L})X Y^=X−γD~−1L~X=(I−γD~−1L~)X(10)
其中
- L ~ = D ~ − A ~ \tilde{L} = \tilde{D} - \tilde{A} L~=D~−A~
通过设定 γ = 1 \gamma = 1 γ=1,也就是只使用邻居的特征,可得 Y ^ = D ~ − 1 A ~ X \hat{Y} = \tilde{D}^{-1} \tilde{A} X Y^=D~−1A~X,也就是拉普拉斯平滑的标准形式。
现在如果把归一化的拉普拉斯矩阵 D ~ − 1 L ~ \tilde{D}^{-1} \tilde{L} D~−1L~ 替换成对阵的归一化拉普拉斯矩阵 D ~ − 1 2 L ~ D ~ − 1 2 \tilde{D}^{-\frac{1}{2}} \tilde{L} \tilde{D}^{-\frac{1}{2}} D~−21L~D~−21,让 γ = 1 \gamma = 1 γ=1,可得 Y ^ = D ~ − 1 2 A ~ D ~ − 1 2 X \hat{Y} = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} X Y^=D~−21A~D~−21X,这恰好就是式8中的图卷积。因此称图卷积是一种特殊形式的拉普拉斯平滑——对称拉普拉斯平滑。注意,平滑仍然会包含顶点特征,因为每个顶点有一个自连接,还有它自己的邻居。
拉普拉斯平滑计算了顶点的新的特征,也就是顶点自身和邻居的加权平均。因为同一类簇的顶点倾向于连接的更紧密,这使得分类任务变得更简单。因为我们可以从表1看出只使用一次平滑就很有效了。
Multi-layer Structure
可以从表1看出尽管两层的 FCN 比 一层的 FCN 有了些许的提升,两层的 GCN 却比 一层的 GCN 好了很多。这是因为在第一层的激活值上再使用平滑使得同一个类簇中的顶点特征变得更相似了,使分类任务更简单。
3.2 When GCNs Fail ?
已经证明了图卷积本质上就是一种拉普拉斯平滑。那 GCN 中应该放多少层呢?当然不是越多越好。GCN 层多了会不好训练。而且重复使用拉普拉斯平滑可能会混合不同类簇中的顶点的特征,使得它们区分不清。
举个例子,在 Zachary 的 karate club dataset (Zachary 1977) 上跑几个层数不同的模型。这个数据集有 34 个结点,两类,78 条边。GCN 的参数像 (Glorot and Bengio 2010) 中的一样随机初始化。隐藏层的维数是 16,输出层的维度是2(输出层维度和类别数一样)。每个结点的特征向量是一个 one-hot 向量。每个 GCN 的输出绘制在图2中。可以看到图卷积的影响(图2a)。使用两次平滑(两层GCN),分类效果相对较好。再次使用平滑,节点点就会混合(mixing)(图2c,2d,2e)。因为这是个小的数据集,两类之间的顶点有很多连接,所以很快就发生了混合。
接下来,证明重复使用拉普拉斯平滑,顶点的特征以及图的每个连通分量会收敛到相同的值。对于对称的拉普拉斯平滑,收敛到的值与顶点度数的二分之一次幂成正比。
假设图 G \mathcal{G} G有 k k k 个连通分量 { C i } i = 1 k \lbrace C_i\rbrace ^k_{i=1} {Ci}i=1k,对于第 i i i 个连通分量的指示向量表示为 1 ( i ) ∈ R n \mathbf{1}^{(i)} \in \mathbb{R}^n 1(i)∈Rn。这个向量表示顶点 j j j是否在分量 C i C_i Ci中,即:
1 j ( i ) = { 1 , v j ∈ C i , 0 , v j ∉ C i (11) \tag{11} \mathbf{1}^{(i)}_j = \begin{cases} 1, v_j \in C_i,\\ 0, v_j \notin C_i \end{cases} 1j(i)={1,vj∈Ci,0,vj∈/Ci(11)
Theorem 1
如果一个图没有二分连通分量,那么对于任意 w ∈ R n \mathrm{w} \in \mathbb{R}^n w∈Rn, α ∈ ( 0 , 1 ] \alpha \in (0, 1] α∈(0,1],
lim m → + ∞ ( I − α L r w ) m w = [ 1 ( 1 ) , 1 ( 2 ) , … , 1 ( k ) ] θ 1 \lim_{m \rightarrow + \infty} (I - \alpha L_{rw})^m \mathrm{w} = [\mathbf{1}^{(1)}, \mathbf{1}^{(2)}, …, \mathbf{1}^{(k)}]\theta_1 m→+∞lim(I−αLrw)mw=[1(1),1(2),…,1(k)]θ1
lim m → + ∞ ( I − α L s y m ) m w = D − 1 2 [ 1 ( 1 ) , 1 ( 2 ) , … , 1 ( k ) ] θ 2 \lim_{m \rightarrow + \infty} (I - \alpha L_{sym})^m \mathrm{w} = D^{-\frac{1}{2}}[\mathbf{1}^{(1)}, \mathbf{1}^{(2)}, …, \mathbf{1}^{(k)}]\theta_2 m→+∞lim(I−αLsym)mw=D−21[1(1),1(2),…,1(k)]θ2
其中, θ 1 ∈ R k , θ 2 ∈ R k \theta_1 \in \mathbb{R}^k, \theta_2 \in \mathbb{R}^k θ1∈Rk,θ2∈Rk,也就是它们分别收敛到 { 1 ( i ) } i = 1 k \lbrace \mathbf{1}^{(i)}\rbrace ^k_{i=1} {1(i)}i=1k 和 { D − 1 2 1 ( i ) } i = 1 k \lbrace D^{-\frac{1}{2}} \mathbf{1}^{(i)} \rbrace ^k_{i=1} {D−211(i)}i=1k。
Proof
L r w L_{rw} Lrw 和 L s y m L_{sym} Lsym 有相同的对应于不同特征向量的 n n n 个特征值 (Von Luxbury 2007)。如果一个图没有二分的连通分量,那么特征值就会在 [ 0 , 2 ) [0, 2) [0,2) 区间内 (Chung 1997)。
L r w L_{rw} Lrw 和 L s y m L_{sym} Lsym 对应于特征值0的特征空间分别由 { 1 ( i ) } i = 1 k \lbrace \mathbf{1}^{(i)}\rbrace ^k_{i=1} {1(i)}i=1k 和 { D − 1 2 1 ( i ) } i = 1 k \lbrace D^{-\frac{1}{2}} \mathbf{1}^{(i)} \rbrace ^k_{i=1} {D−211(i)}i=1k展开组成(Von Luxburg 2007)。
当 α ∈ ( 0 , 1 ] \alpha \in (0, 1] α∈(0,1]时, ( I − α L r w ) (I - \alpha L_{rw}) (I−αLrw)和 ( I − α L s y m ) (I - \alpha L_{sym}) (I−αLsym)特征值取值范围为 ( − 1 , 1 ] (-1,1] (−1,1],对应于特征值1的特征空间分别由 { 1 ( i ) } i = 1 k \lbrace \mathbf{1}^{(i)}\rbrace ^k_{i=1} {1(i)}i=1k 和 { D − 1 2 1 ( i ) } i = 1 k \lbrace D^{-\frac{1}{2}} \mathbf{1}^{(i)} \rbrace ^k_{i=1} {D−211(i)}i=1k展开组成。
由于所有 ( I − α L r w ) (I - \alpha L_{rw}) (I−αLrw)和 ( I − α L s y m ) (I - \alpha L_{sym}) (I−αLsym)的特征值的绝对值都小于等于1,在左边重复乘以它们后,结果收敛于特征值1的特征向量的线性组合,也就是 { 1 ( i ) } i = 1 k \lbrace \mathbf{1}^{(i)}\rbrace ^k_{i=1} {1(i)}i=1k 和 { D − 1 2 1 ( i ) } i = 1 k \lbrace D^{-\frac{1}{2}} \mathbf{1}^{(i)} \rbrace ^k_{i=1} {D−211(i)}i=1k的线性组合。
注意,由于每个顶点都添加了一个额外的自循环,所以图中没有二分量。基于上述定理,over-smoothing(过度平滑)会使特征难以区分,影响分类精度。
上述分析指出了在GCN中叠加多层卷积层的潜在问题。此外,一个深层GCN更难以训练。(Kipf和Welling 2017)中使用的GCN也只是一个2层GCN。然而,由于图卷积是一个局部滤波器——邻域特征向量的线性组合,一个浅层的GCN不能只用少量的有标签的数据将标签信息充分地传播到整个图。如图1所示,随着训练规模的缩小,GCNs(无论是否有validation))的性能都会迅速下降。事实上,GCNs的精度比标签传播的精度下降得更快。由于标签传播(Zhu, Ghahramani, and Lafferty 2003)只使用图信息,而GCNs同时利用结构和顶点特征,这反映了GCN模型在探索全局图结构方面的无能。
GCN模型(Kipf和Welling 2017)的另一个问题是,它需要额外的验证集来提前停止训练,这本质上是使用验证集上的预测精度来选择模型。如果在不使用验证集的情况下对训练集上优化GCN,那么它的性能将会显著下降。如图1所示,没有validation的GCN的性能比有validation的GCN下降得厉害。在(Kipf和Welling 2017)中,作者使用了另外一组500个带标签的数据进行验证,这远远超过了训练数据的总数。这当然是不可取的,因为它违背了半监督学习的目的。此外,它使得GCNs与其他方法的比较不公平,因为其他方法,如标签传播(Zhu, Ghahramani, and Lafferty 2003),可能根本不需要验证数据。
4 解决方案
GCN Model advantages
- 图的卷积-拉普拉斯平滑使分类问题变得容易
- 多层神经网络是一种功能强大的特征提取器
GCN Model disadvantages
- 图卷积是一种局部滤波器,如果有标记的数据过少,则性能不理想
- 神经网络需要大量有标记的数据进行验证和模型选择
改进的思想就是充分利用GCN模型的优势去克服它的局限性,这就产生了一个co-training (Blum and Mitchell 1998)的想法。
4.1 Co-Train a GCN with a Random Walk Model 用随机游走模型和GCN协同训练
文中提出了用随机游走模型来协同训练一个GCN,因为随机游走模型可以探索全局图结构,这是对GCN模型的补充。首先使用一个随机游走模型来找到最可靠的顶点——每个类的标记顶点的最近邻居,然后将它们添加到标签集以训练GCN。与in (Kipf和Welling 2017)不同,这种方法直接在训练集上优化了GCN的参数,不需要额外的标签数据进行验证。
文中使用一个 partially absorbing random walks (ParWalks)(Wu et al. 2012) 来捕获网络的全局结构。ParWalks在每个状态都由部分吸收的二阶马尔科夫链。算法1描述了使用ParWalks扩展标签集。

- 首先,计算归一化的吸收概率矩阵 P = ( L + α Λ ) − 1 P = (L + \alpha \Lambda)^{-1} P=(L+αΛ)−1
- P i , j P_{i, j} Pi,j 是从顶点 i i i 出发被吸收到顶点 j j j 的概率,表示 i i i 和 j j j 有多大的可能性属于同一类
- 将有标签的点划分为 S 1 , S 2 , . . . , S k S_1,S_2,...,S_k S1,S2,...,Sk,其中 S k S_k Sk定义为类 k k k中有标签的顶点的集合
- 然后,对每个类 k k k,计算可信向量 p = ∑ j ∈ S k P : , j \mathbf{p} = \sum_{j \in S_k} P_{:, j} p=∑j∈SkP:,j,其中 p ∈ R n \mathbf{p} \in \mathbb{R}^n p∈Rn, p i p_i pi 是顶点 i i i 属于类 k k k 的概率
- 最后,找到 t t t 个最可信的顶点把它们加到训练集的类 k k k 中。
4.2 GCN Self-Training GCN的自训练
另一种让GCN“see”更多训练样本的方法是self-train a GCN。首先用给定标签集(有标签的数据集)训练一个GCN,然后通过比较softmax分数,为每个类选择最有把握(confident)的预测,并将它们添加到标签集中。然后,将预先训练好的GCN作为初始化,继续用扩展的标签集训练GCN。这个过程见算法2。

通过GCN对每个类选择最有把握的预测,将它们添加到标记集将有助于训练一个更健壮和准确的分类器。此外,它co-training在一个图有许多孤立的部分,不能传播标签与随机游走的情况进行了补充和完善。
Combine Co-Training and Self-Training
为了提高标签的多样性,训练一个更强的分类器,文中提出了Co-Training和Self-Training相结合的方法。
- “Union”方法:分别使用random walk和GCN找到最有把握的预测来扩展标签集,然后使用扩展的标签集继续训练GCN
- “Intersection”方法:为了找到更准确的标签添加到标签集,添加由随机游走和GCN找到的的最可靠的预测来扩展标签集
使用上面两种训练方法以后就不需要再要求使用额外的验证集了。只要扩展的标签集有足够多的标签就可以训练一个比较好的GCN分类器。
训练一个比较好的GCN分类器需要多少标签数据?
文中假设GCN的层数是 t t t,图的平均度数是 d ^ \hat d d^,则可以通过 ( d ^ ) t ∗ η ≈ n (\hat d)^t *\eta \approx n (d^)t∗η≈n估计标签数据的数量的下限为 η = ∣ V l ∣ \eta =|\mathcal{V_l}| η=∣Vl∣。文中说这样估计的原理就是能够使得这些标签对 t t t层GCN的标签传播能够覆盖整张图。
5 实验
对比的baseline
- GCN with validation (GCN+V)
-GCN without validation (GCN-V) - GCN with Chebyshev filter (Cheby) (Kipf and Welling 2017)
- label propagation using ParWalks (LP) (Wu et al. 2012)
- Planetoid (Yang, Cohen,and Salakhutdinov 2016)
- DeepWalk (Perozzi, Al-Rfou, and Skiena 2014)
- manifold regularization (ManiReg) (Belkin,Niyogi, and Sindhwani 2006)
- semi-supervised embedding (SemiEmb) (Weston et al. 2008)
- iterative classification algorithm (ICA) (Sen et al. 2008)
5.1 Experimental Setup
数据集:CiteSeer, Cora, and PubMed
For ParWalks
- Λ = I , α = 1 0 − 6 \Lambda=I,\alpha=10^{-6} Λ=I,α=10−6
For GCNs
- 学习率0.001
- epoch最大数量:200
- dropout rate:0.5
- L2正则化权重: 5 × 1 0 − 4 5 \times 10^{-4} 5×10−4
- 2个卷积层
- 16 hidden units
- 每一次训练都将有标签的数据集划分到一个小的集合去训练
- 测试样本数:1000
- GCN+V使用类似GCN中的500个额外的标签数据去验证
For Cheby:K=2(2阶多项式)
在Cora 和 CiteSeer数据集上用0.5%, 1%,
2%, 3%, 4%, 5% 的training size测试;在PubMed数据集上用0.03%, 0.05%, 0.1%, 0.3%的training size测试
5.2 Results Analysis
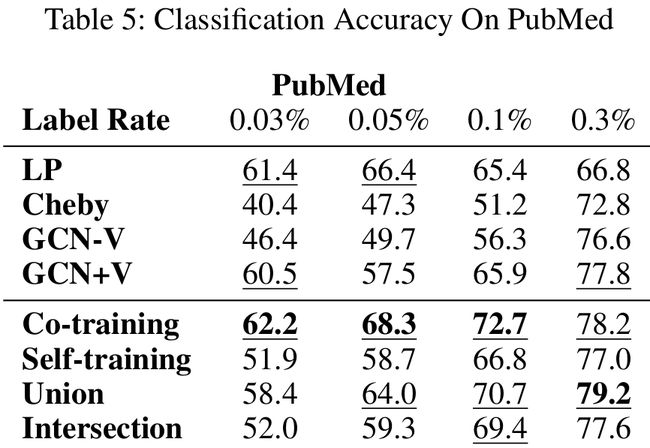
- Co-Training和LP性能相近
- Co-Training,在数据有很强的流结构(manifold structure)时,例如PubMed数据集,性能最好
- Co-Training在CiteSeer数据集表现最差
- Self-Training在PubMed数据集上性能最差,因为它不能充分利用图的结构
- Self-Training在CiteSeer数据集表现最好
- Intersection在training size特别大的时候表现得更好
- Union在许多情况下都表现得最好,因为这种方法可以使训练集中增加更多不一样的标签
Comparison with GCNs 和GCNs的对比
- 当training size比较小的时候,文中的方法比GCN-V和GCN+V在大多数情况都好
- 当training size在增大的时候,文中的方法比GCN+V在大多数情况都好
- 当training size足够大的时候,文中的方法和GCNs效果相似,说明所给的标签足以训练出良好的GCN分类器。
- Cheby在大多数情况下都由于过拟合而表现很差

Comparison with other methods 和其他方法的对比
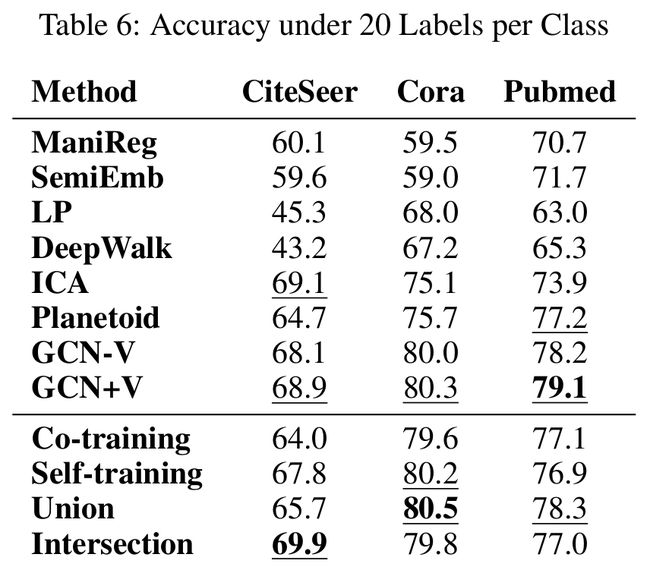
除了数据集外,其他实验设置都相同,对每个类采样20个标签,分别对应于CiteSeer、Core和PubMed数据集中有标签的样本的百分比为3.6%、5.1%和0.3%。baselines的实验结果从(Kipf and Welling 2017)这篇文章而来。
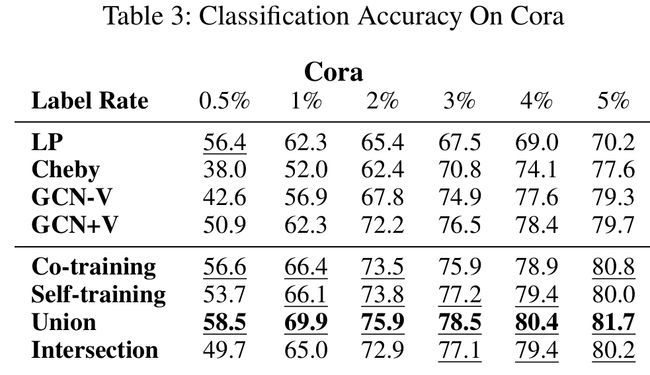
- 可以从表3,4,5中看出,在标签数据很少的情况下,文中的方法比大多数baselines效果都好,例如表3中Union的方法在标签率为2%的Cora数据集上(54个标签)效果比表6中其他所有的有140个标签的方法效果都好
Influence of the Parameters 参数的影响
考虑一个有标签的数据的数量的参数 η \eta η( ( d ^ ) t ∗ η ≈ n (\hat d)^t *\eta \approx n (d^)t∗η≈n),实验中使用的是 3 η 3\eta 3η,并且发现使用 2 η , 3 η , 4 η 2\eta,3\eta,4\eta 2η,3η,4η在实验中效果差不多,卷积层数为2。
实验表明,2层GCN效果最好,当卷积层的层数增加时,可能由于过拟合导致分类准确率较低。
Computational Cost 计算代价
- 只用几千个节点,在Cora、CiteSeer数据集上的训练时间是可以忽略不计的
- 在PubMed数据集上,运行时间小于0.38秒
- 使用vertex-centric graph engines可以进一步加快计算速度(Guo等,2017),因此文中的方法的可扩展性不是问题
- 对于Self-Training,只需要运行几个epoch而不是训练一个GCN。Self-Training的收敛速度很快,因为它建立在一个预先训练的GCN上。因此,Self-Training的运行时间与GCN相当。
6 小结
- 证明了图卷积GCN是一种特殊形式的拉普拉斯平滑
- 分析了图卷积GCN的优势和局限性
- 针对图卷积GCN随着卷积层的叠加导致分类准确率性能下降的问题,提出了两种训练方法:Co-Train a GCN with a Random Walk Model和GCN Self-Training
- 未来的工作:提出新的适合于深层架构的卷积核;利用更高级的深度学习方法提高更多GCN基于图的一些应用