【自嗨笔记#3】B站 后浪 评论分析
[ 自嗨笔记#3] 后浪 评论分析
B站的宣传片《后浪》引起了很大反响,从各方面的了解,目前观众们的反馈,负面的情绪比较多,那么真的是这样吗?因此想通过爬取评论,利用snownlp,看下数据下真实的样子!
一、爬取
- 页面分析

这里直接访问,会被拒绝,百度一下后,了解到去掉中间的信息,而且jsonp格式不可以用json解析
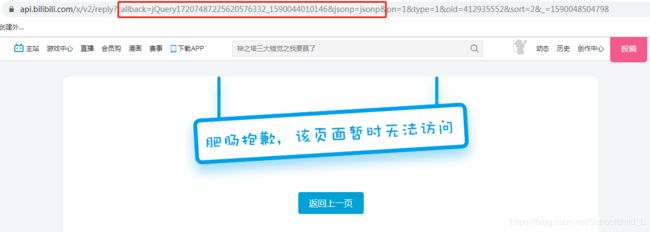
去掉后可以获取到json格式信息,方便信息提取
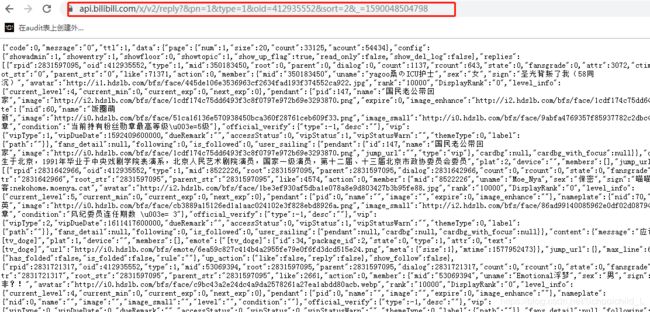
找到评论所在位置提取,也可以提取到其他需要的信息
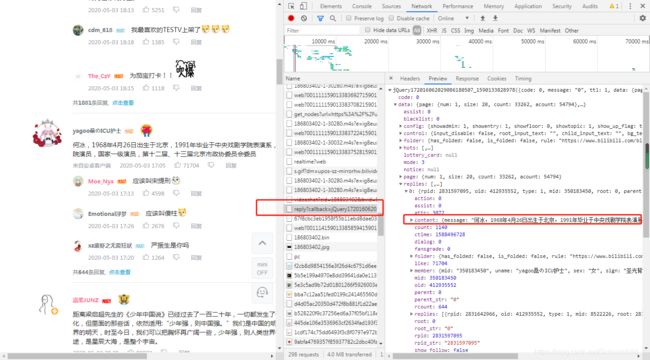
- 代码框架
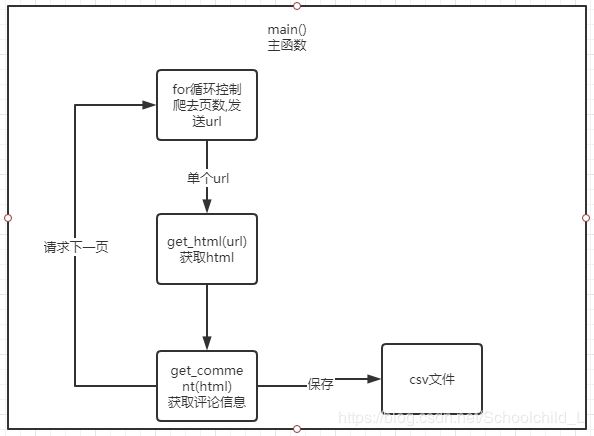
- 全部代码
# -*- coding: utf-8 -*-
"""
Created on Wed May 13 11:52:11 2020
@author: Administrator
"""
import requests
import time
import json
def get_html(n):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
"cookie": "_uuid=3BEB537F-A423-3339-ADAE-B9F98CE2F1A614498infoc; buvid3=E8D76FBA-069D-49DC-8F88-787C9513FEB9190975infoc; LIVE_BUVID=AUTO2815753467172931; CURRENT_FNVAL=16; stardustvideo=1; rpdid=|(u)~km)Rm)l0J'ul~lJRY~lk; laboratory=1-1; sid=j6rx3drb; CURRENT_QUALITY=32; PVID=2; bfe_id=61a513175dc1ae8854a560f6b82b37af",
'Referer': 'https://www.bilibili.com/video/BV1FV411d7u7?from=search&seid=9323669094129958607',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
url = 'https://api.bilibili.com/x/v2/reply?&pn='+str(n)+'&type=1&oid=412935552&sort=2&_=1589337097696'
r = requests.get(url,headers=headers)
r.raise_for_status()
return r.content
def get_comment(html):
h = json.loads(html)
f = open('houlang_comment.csv','a',encoding='utf-8')
for i in h['data']['replies']:
ls = []
comment = i['content']['message'].replace(',',' ').replace('↵','').replace('\n','')
like_count = i['like']
mid = i['member']['mid']
name = i['member']['uname']
sex = i['member']['sex']
d=i['ctime']
data = time.strftime('%Y/%m/%d %H:%M:%S',time.localtime(d)) #10位的时间戳,需要time.locltime()
ls = [str(comment)]+[str(like_count)]+[mid]+[name]+[sex]+[data]
a = ','.join(ls)
try:
f.write(a+'\n')#获取评论
except:
continue
def main():
start = time.time()
f = open('houlang_comment.csv','a',encoding='utf-8')
l = '评论,点赞,id,昵称,性别,评论时间'+'\n'
f.write(l)
f.close()
for n in range(1,50):
print('开始爬取第',n,'页')
html = get_html(n) #获取html
get_comment(html)
time.sleep(0.5)
print('爬取成功')
print('****************')
end = time.time()
use_time = end-start
print('程序结束,用时',use_time,'秒')
main()
二、数据分析
-
词云
用词语造个句:“后浪”,“视频”,“不是”,“我们”,“自己”,“生活” ???哈哈哈!!!

-
先来看下基本数据
这里只爬取了前50页的数据
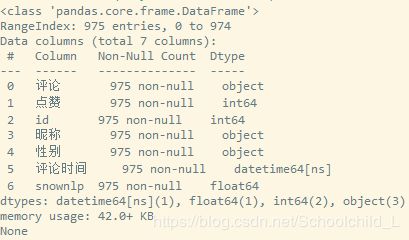
-
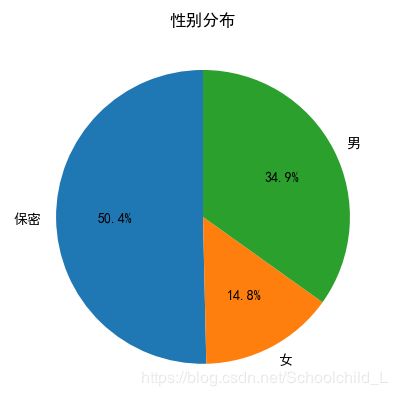
评论的性别构成
B站上有保密这个选项,还有很有意思的
-
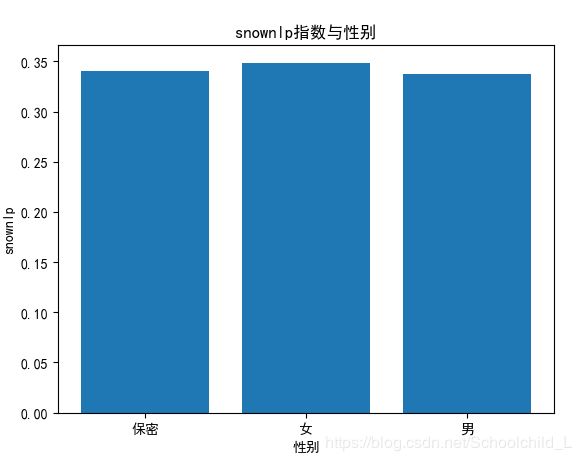
snownlp指数与性别关系
女性的反馈要比男性正向一些
-
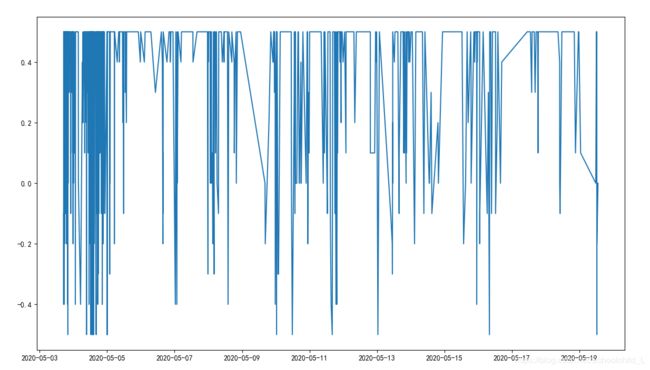
评论snownlp统计
区间为[-0.5,0.5],-0.5代表评论为负向,反之0.5为正向

-
时间与snownlp指数的关系
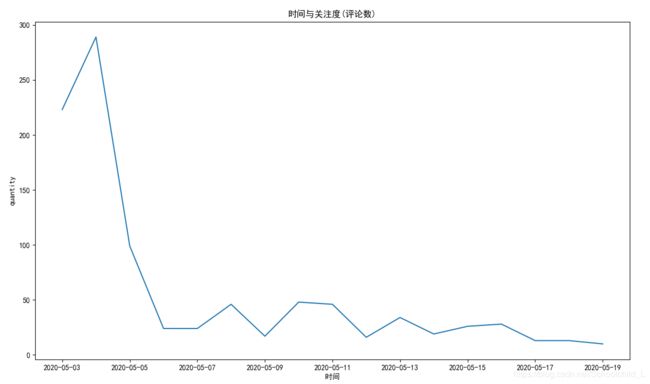
可以看出,基本趋于正向评论,另外评论数量随着时间变化而减少
-
时间与关注度(评论数)
-
分析部分完整代码,按需要自取
# -*- coding: utf-8 -*-
"""
Created on Mon May 18 17:48:11 2020
@author: Administrator
"""
import pandas as pd
from snownlp import SnowNLP
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif']=['SimHei']#设置中文显示
plt.rcParams['axes.unicode_minus'] =False
df = pd.read_csv("E:/lance/sql/Python/'后浪'评论/houlang_comment.csv",encoding='utf-8')
df['评论时间']=pd.to_datetime(df['评论时间'])
def snownlp_c(element):
try:
sn=SnowNLP(element)
return round(sn.sentiments,1)-0.5
except:
pass
df['snownlp']=df['评论'].transform(snownlp_c) #不需要时注释掉,以免浪费性能
# print(df.info())
# snownlp指数与数量
'''
q1 = df.groupby(by='snownlp')['评论'].count().reset_index()
plt.figure()
plt.plot(q1['snownlp'],q1['评论'])
plt.xlabel('snownlp')
plt.ylabel('quantity')
plt.title('snownlp指数与数量')
plt.show()
'''
# snownlp指数与性别
'''
q2 = df.groupby(by='性别')['snownlp'].mean().reset_index()
plt.figure()
plt.bar(q2['性别'],q2['snownlp'])
plt.xlabel('性别')
plt.ylabel('snownlp')
plt.title('snownlp指数与性别')
plt.show()
'''
# 性别分布情况
'''
a=df.groupby(by='性别')['评论'].count().reset_index()
plt.pie(a['评论'],labels=a['性别'],
labeldistance = 1.1,autopct = '%3.1f%%',shadow = False,
startangle = 90,pctdistance = 0.6)
plt.title('性别分布')
plt.show()
'''
# 时间与关注度(评论数)
'''
df['date'] = df['评论时间'].dt.date
f = df.groupby(by='date')['评论'].count().reset_index().sort_values(by='date',axis=0,ascending=True)
plt.figure()
plt.plot(f['date'],f['评论'])
plt.xlabel('时间')
plt.ylabel('quantity')
plt.title('时间与关注度(评论数)')
plt.show()
'''
# 时间与snownlp的关系
'''
df1 = df.sort_values(by = '评论时间',axis=0,ascending=True)
plt.plot(df1['评论时间'],df1['snownlp'])
plt.show()
'''
三、写在最后
个人觉得《后浪》总体是不错的,展示了年轻人的精彩生活,也展示了B站的多元性。虽然,视频里举得例子,我们可能不曾拥有过,但那种勇于冒险,喜爱追求新鲜事物,对待兴趣爱好的极客精神,又何尝不曾在我们的身上出现过!
四、相关链接
[ 自嗨笔记#1] 微博疫情舆情分析—爬取部分
[ 自嗨笔记#2] 微博疫情舆情分析—舆情分析部分