用最新技术优化深度学习BTC交易机器人
本文翻译自Adam King的《Optimizing deep learning trading bots using state-of-the-art techniques》,英语好的建议读原文,本译本只是学习记录,翻译水平有限,如果专业术语错误还望指正。
教会我们的机器人用特征工程和Bayes优化赚更多的钱。
在上篇文章中,我们创建了不会亏钱的BTC交易机器人。尽管agents是赚钱的,但收益率一般,所以这次更上一层楼,大幅提升模型性能。
再次强调,本系列文章只是为了考察最新深度学习技术是否能够创建正收益BTC交易机器人。关闭任何创建强化学习算法的企图似乎是现状,因为创建一个交易算法是行不通的。然而,相关领域最新进展表明面对相同问题RL程序常常变现优于监督学习。基于此,我写了本系列文章,来考察这些交易程序收益率如何或者考察下现状是否合理。
我们首先优化提升政策网络,平稳输入数据集,这样才能从小数据集中学出更多信息。
然后,我们用前沿特征工程提升agent的观察空间,微调奖励函数产生更优策略。
最后,我们在训练、测试最终程序收益率前,用Bayes优化技术来确定最优超参数。各位看官拿好瓜,尽情欣赏疯狂之旅。
-
修改
首先改善上文中代码,提升模型盈利水平。代码见我的Github。
-
RNN递归神经网络
首先调整策略,用递归的LSTM(Long Short-Term Memory)网络替换先前的多层感知机(MLP,MultiLayer Perceptron)。因为RNN能够不受时间影响保持内部结构,我们不再需要哟弄个华东回测窗口捕捉价格波动。相反,采用神经网络的内部递归来捕捉。每个时间步,输入数据以及最新输出数据一同传给算法。

这让LSTM再每个时间步保持内部状态,就像程序能够“记住”或“忘记”特殊的数据关系。

from stable_baselines.common.policies import MlpLstmPolicy
model = PPO2(MlpLstmPolicy, train_env, tensorboard_log="./tensorboard")
-
平稳数据
上篇文章有人指出我们的时间序列数据是不平稳的。因此任何机器学习模型都很难预测未来价值。
平稳时间序列指均值、方差、自相关系数均为常数。
最主要的是我们的时间序列包含明显的趋势性和季节性,这两点都会影响算法预测准确性。我们可以通过差分和变换技术产生一个更正态分布的时间序列。
差分是将每个时间步减去其导数(收益率)。这样可以去除趋势性,不过依然保留季节性。季节性可以通过再每次差分前先取导数来去除。这样就产生最终的平稳时间序列。下面右图。

df['diffed'] = df['Close'] - df['Close'].shift(1) df['logged_and_diffed'] = np.log(df['Close']) - np.log(df['Close']).shift(1)可以用 Augmented Dickey-Fuller Test测试时间序列的平稳性。测试给出p值为0.00,使我们拒绝测试的空假设,确认时间序列是平稳的。
from statsmodels.tsa.stattools import adfuller df['logged_and_diffed'] = np.log(df['Close']) - np.log(df['Close']).shift(1) result = adfuller(df['logged_and_diffed'].values[1:], autolag="AIC") print('p-value: %f' % logged_and_diffed_result[1])这个问题就解决了,下面我们采用特征工程来进一步优化观测空间。
-
特征工程
为进一步优化模型,我们做一些特征工程。
特征工程是用领域特定只是创造额外输入数据来提升机器学习模型。
本例中,我们会为数据集添加一些常见但有效的技术因子,以及从StatsModels SARIMAX预测模型得到的输出。技术因子会给数据集带来一些尽管滞后却相关的信息。我们的预测模型预测的信息会对其提供很好的支持。此多特征综合会为模型提供一个有用的观测平衡。
-
技术分析
为选取技术因子集,我们会比较
ta库中的32个因子(58个特征)。采用pandas分析同类(动量、成交量、趋势、波动性)因子两两间的相关性,然后只选取每种类型中相关性最低的因子作为特征。此法,我们可以从这些技术因子中获得尽可能多的好处,而不对观测空间增加过多噪音。

结果表明波动性指标都高度相关,几个动量指标也是。当我们删除所有重复特征(在集群中相关性绝对值>0.5)。最终剩38个技术特征加入到观测空间中。完美,我们创建一个add_indicators实用方法将上述特征加到我们的数据集中,并在环境初始化中调用它以免再每个时间步计算这些值。
def __init__(self, df, initial_balance=10000, commission=0.0003, reward_func='profit', **kwargs):
super(BitcoinTradingEnv, self).__init__()
self.df = df.fillna(method='bfill')
self.df = add_indicators(self.df.reset_index())
self.stationary_df = log_and_difference(
self.df, ['Open', 'High', 'Low', 'Close', 'Volume BTC', 'Volume USD'])
-
统计分析
下一步是添加预测模型,我们选用Seasonal Auto Regressive Integrated Moving Average (SARIMA)模型提供价格预测,因为其每步计算很快,SARIMA在我们的平稳数据集上准确性好。还有个额外好处,他的实现非常简单,并允许我们为预测结果创建一个置信区间,这通常比一个单值更好。举例说明,agent会学出对置信区间小的预测谨慎信任,当置信区间大时承担更多风险。
def _next_observation(self): ... obs = scaled_features[-1] past_df = self.stationary_df['Close'][:self.current_step + self.n_forecasts + 1] forecast_model = SARIMAX(past_df.values) model_fit = forecast_model.fit(method='bfgs', disp=False) forecast = model_fit.get_forecast(steps=self.n_forecasts, alpha=(1 - self.confidence_interval)) obs = np.insert(obs, len(obs), forecast.predicted_mean, axis=0) obs = np.insert(obs, len(obs), forecast.conf_int().flatten(), axis=0)现在我们已经用一个更合适的递归神经网络更新策略,并用上下文特征工程优化观测空间,是时候做整体优化了。
-
奖励优化

可能会有人认为上文提到的奖励函数已经是最优选,其实进一步检查就会发现这是不对的。尽管上次的简单奖励函数已经可以盈利,但它经常产出会造成资本损失的不稳定策略。为改善,我们除了未计利润还要考虑其他奖励度量。
上文评论中有人给出了一个简单优化方法:不仅奖励持BTC币待涨,也奖励空仓BTC价跌。例如,我们可以为anget持有BTC/USD仓位时净值增长给与奖励,也可以在其不持有任何仓位时BTC/USD下跌而给出奖励。
虽然这个策略在奖励回报增长方面表现良好,但是并未考虑产生高额收益的风险。投资者长期内会通过简单的收益指标发现这些问题,并习惯上转向经风险调整的回报度量来给与解释。
-
基于波动率的度量
最常见的风险调整收益度量是夏普率。这是投资组合在一段特殊时期内超额收益对波动率的简单比率。为保持高夏普率,一项投资需同时保持高收益和低波动。对应的数学公式是:
S h a r p e = R P − R B σ P = P o r t i f o l i o r e t u r n s − B e n c h m a r k r e t u r n s S t a n d a r d d e v i a t i o n o f p o r t f o l i o Sharpe=\frac{R_P-R_B}{\sigma_P}=\frac{Portifolio\; returns - Benchmark \;returns}{Standard\;deviation \; of\;portfolio} Sharpe=σPRP−RB=StandarddeviationofportfolioPortifolioreturns−Benchmarkreturns
这个度量久经考验,不过对我们的目的而言略有缺陷,因为它惩罚了上行波动。对于BTC,这很成问题,因为上行波动(价格猛涨)经常是有利可图的。这就把我们引向agents测试的第一项奖励度量。Sortino率与Sharpe率类似,只是它只把下行波动视为风险,而非全波动。作为结果,Sortino率不惩罚上行波动。数学公式如下:
S o r t i n o = R P − R B σ D = P o r t f o l i o r e t u r n s − B e n c h m a r k r e t u r n s S t a n d a r d d e v i a t i o n o f d o w n s i d e Sortino=\frac{R_P-R_B}{\sigma_D}=\frac{Portfolio\;returns-Benchmark\;returns}{Standard\;deviation\;of\;downside} Sortino=σDRP−RB=StandarddeviationofdownsidePortfolioreturns−Benchmarkreturns -
额外指标
在此数据集上测试的第二个奖励度量是Calmar率。至此我们所有的度量都没有考虑回撤。
回撤是资产组合一种特殊损失的度量,从高到低
大的回撤对成功的交易策略不利,因为长期的高额收益会被一次突然的大额回撤折损殆尽。

为鼓励策略积极主动组织大额回撤,我们可以用一个奖励指标来解释那些资本损失,比如Calmar率。这个比率与Sharpe率相同,只是用最大回撤代替资产组合值的标准差。
C a l m a r = R P − R B μ D = P r o t f o l i o r e t u r n s − B e n c h m a r k r e t u r n s M a x i m u m d r a w d o w n o f p o r t f o l i o Calmar=\frac{R_P-R_B}{\mu_D}=\frac{Protfolio\;returns-Benchmark\;returns}{Maximum\;drawdown\;of\;portfolio} Calmar=μDRP−RB=MaximumdrawdownofportfolioProtfolioreturns−Benchmarkreturns
我们的最后一个指标,也是在对冲基金业普遍应用的,Omega率。理论上,就度量risk vs. return来说,Omega率比Sortino率和Calmar率都好。因为它可以在单个指标中解释收益分布的全部。为计算它,我们需要先计算资产组合基于特定基准上下波动的概率分布,然后取两者比率。比率越高,上升空间高于下降空间的概率就越高。
O m e g a = ∫ R B b 1 − F ( R P ) d x ∫ a R B F ( R P ) d x = U p s i d e P o t e n t i a l D o w n s i d e P o t e n t i a l Omega=\frac{\int_{R_B}^b1-F(R_P)dx}{\int_a^{R_B}F(R_P)dx}=\frac{Upside\;Potential}{Downside\;Potential} Omega=∫aRBF(RP)dx∫RBb1−F(RP)dx=DownsidePotentialUpsidePotential
-
代码
虽然编写上述奖励度量听起来挺有趣,不过我还是倾向于用
empyrical库来直接计算它们。幸运的是这个库中恰好包含我们上述定义的3个度量。在每个时间步获取比率就像给相关Empyrical函数提供一系列阶段收益和基准收益一样简单。import numpy as np from empyrical import sortino_ratio, calmar_ratio, omega_ratio def _reward(self): length = min(self.current_step, self.reward_len) returns = np.diff(self.net_worths)[-length:] if self.reward_func == 'sortino': reward = sortino_ratio(returns) elif self.reward_func == 'calmar': reward = calmar_ratio(returns) elif self.reward_func == 'omega': reward = omega_ratio(returns) else reward = np.mean(returns) return reward if abs(reward) != inf and not np.isnan(reward) else 0现在我们已经知道如何去衡量一个成功的交易策略,是时候找出是哪些指标最能衡量优质结果。将上述度量函数逐一放入Optuna并用Bsyes优化方法来找出数据集的最优策略。
-
工具集
宝刀配英雄。充分利用前辈呕心沥血的工作,不要重复早轮子。对今天的工作,最重要的工具之一就是
optuna库,这是一个用 Tree-structured Parzen Estimators (TPEs)实现Bayes优化的库。TPEs可并行,大大减少搜索时长,充分利用GPU。简言之,Bayes优化是一项高效搜索超空间,寻找最大化目标函数参数集的技术。
简言之,Bayes优化是一种提升任何黑盒模型的高效方法。它的工作方式是通过代理函数或代理函数分布对目标函数建模。分布会随着时间提升,因为算法会探索产生最大值的超空间和区域。
如何将其用于我们的BTC交易机器人?本质上我们可以用此技术找到让模型最优的超参数集。我们正在大海捞针,Bayes优化就是我们的磁铁。让我们开始吧!
-
部署
Optuna

用Optuna优化超参数相当简单。首先,创建一个optuna研究,它是所有超参数探索的母容器。一项试验包含特定的超参数配置和由目标函数造成 的成本。然后可调用study.optimize()并传给目标函数,Optuna会采用Bayes优化来找到产生最低成本的超参数配置。
import optuna
def optimize(n_trials = 5000, n_jobs = 4):
study = optuna.create_study(study_name='optimize_profit', storage='sqlite:///params.db', load_if_exists=True)
study.optimize(objective_fn, n_trials=n_trials, n_jobs=n_jobs)
此例中,目标函数由在我们的BTC交易环境中训练和测试PPO2模型构成。目标函数返回的成本是测试期的平均奖励,是负数。我们需要取平均奖励的负数,因为Optuna把低回报当为更优尝试。optimize函数为我们的目标函数提供一个实验对象,我们用该对象制定需要优化的变量。
def objective_fn(trial):
env_params = optimize_envs(trial)
agent_params = optimize_ppo2(trial)
train_env, validation_env = initialize_envs(**env_params)
model = PPO2(MlpLstmPolicy, train_env, **agent_params)
model.learn(len(train_env.df))
rewards, done = [], False
obs = validation_env.reset()
for i in range(len(validation_env.df)):
action, _ = model.predict(obs)
obs, reward, done, _ = validation_env.step(action)
rewards += reward
return -np.mean(rewards)
optimize_ppo2()和optimize_envs()方法接受一个实验对象并返回一个测试词典。每个变量的搜索空间由对试验调用的特殊suggest函数和传给函数的参数确定。
例如,trial.suggest_loguniform('n_steps', 16, 2048)以对方方式提示一个新的介于16-2048之间的对数(16, 32, 64, …, 1024, 2048)。更进一步,trial.suggest_uniform('cliprange', 0.1, 0.4)会建议一个简单、累计形式的会当属(0.1, 0.2, 0.3, 0.4).此处用不到,不过Optuna也会为建议分类变量提供方法:suggest_categorical('categorical', ['option_one', 'option_two']).
def optimize_ppo2(trial):
return {
'n_steps': int(trial.suggest_loguniform('n_steps', 16, 2048)),
'gamma': trial.suggest_loguniform('gamma', 0.9, 0.9999),
'learning_rate': trial.suggest_loguniform('learning_rate', 1e-5, 1.),
'ent_coef': trial.suggest_loguniform('ent_coef', 1e-8, 1e-1),
'cliprange': trial.suggest_uniform('cliprange', 0.1, 0.4),
'noptepochs': int(trial.suggest_loguniform('noptepochs', 1, 48)),
'lam': trial.suggest_uniform('lam', 0.8, 1.)
}
def optimize_envs(trial):
return {
'reward_len': int(trial.suggest_loguniform('reward_len', 1, 200)),
'forecast_len': int(trial.suggest_loguniform('forecast_len', 1, 200)),
'confidence_interval': trial.suggest_uniform('confidence_interval', 0.7, 0.99),
}
稍后,在用一个不错的CPU/GPU组合运行我们的优化函数一夜之后,我们可以用Optuna创建的sqlite数据库中载入研究。该研究从测试中跟踪最佳试验,我们可以用这些测试为环境抓取最佳超参数集。
study = optuna.load_study(study_name='optimize_profit', storage='sqlite:///params.db')
params = study.best_trial.params
env_params = {
'reward_len': int(params['reward_len']),
'forecast_len': int(params['forecast_len']),
'confidence_interval': params['confidence_interval']
}
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, **env_params)])
model_params = {
'n_steps': int(params['n_steps']),
'gamma': params['gamma'],
'learning_rate': params['learning_rate'],
'ent_coef': params['ent_coef'],
'cliprange': params['cliprange'],
'noptepochs': int(params['noptepochs']),
'lam': params['lam']
}
model = PPO2(MlpLstmPolicy, train_env, **model_params)
我们已经修改模型、提升特征集、优化所有超参数。现在是时候见证我们的agent如何应对新的奖励机制。我已经训练了一个agent适应前述4中收益度量:简单收益、Sortino率、Calmar率、Omega率。让我们在一个用他们从未训练过的价格数据初始化的测试环境中运行每一个优化后的agent,看看收益率怎么样。
-
基准
在查看结果之前,我们需要知道一个成功的策略应该是什么样的。基于此,我们将用几个常见但有效的BTC盈利交易策略作为基准。信不信由你,过去十年来最有效的BTC策略之一就是简单的买入然后持有。我们将测试的两外另个策略是用非常简单但有效的技术分析来创建买卖信号。
-
买入并持币
尽可能多的买入并持币到天荒地老。虽然这个策略不复杂,但是在过去它取得了成功的收益率。
-
RSI
当RSI持续下跌而连续的收盘价持续上涨时,是一个负的反转趋势(卖)信号。当RSI连续上涨而收盘价连续下跌时,一个争相反转信号(买)就出现了。
-
SMA(Simple Moving Average)交叉
当长期移动平均线穿越短期移动平均线,是一个负趋势反转信号(卖)。
当短期移动平均线穿越长期移动平均线,是一个正的趋势反转信号(买)。
测试这些简单基准的目的是证明我们的深度学习
agent正在市场上创建alpha。如果我们不能那白那些简单基准,那么我们就是在浪费开发时间浪费GPU,而只是做了一个看起来炫酷的科学项目。让我们它的价值。
-
-
结果
我必须提前说明,下面部分的正向收益是错误代码的直接结果。因为数据时间的存储方式防止agent总可以提前12小时看到价格信息,这是明显的前视偏差。问题已经得到修正,但还需要时间替换下面的结果集。请理解这些结果是完全无效且无法复制的。
话虽如此,本文依然有大量研究且本系列文章的目的本就不是为了赚大钱,而是探讨在最新强化学习和优化技术下可以达到什么研究深度。因此为了让本文原汁原味,我还是把旧有(不正确)结果留下了,等后续实践充分我会用新的正确的结果再行更替。
用从CryptoDataDownload下载的小时级数据集(OHCLV)的钱80%训练
agent,并用后20%测试观察策略在新数据上的效果。这种简单的交叉验证足以满足需要,因为当我们最终发布算法时,可以在整个数据集上训练并用新输入的数据集作为新的测试集。让我们快速浏览失败者以便找到成功者。首先我们来看Omega策略,在数据集上相当无用。
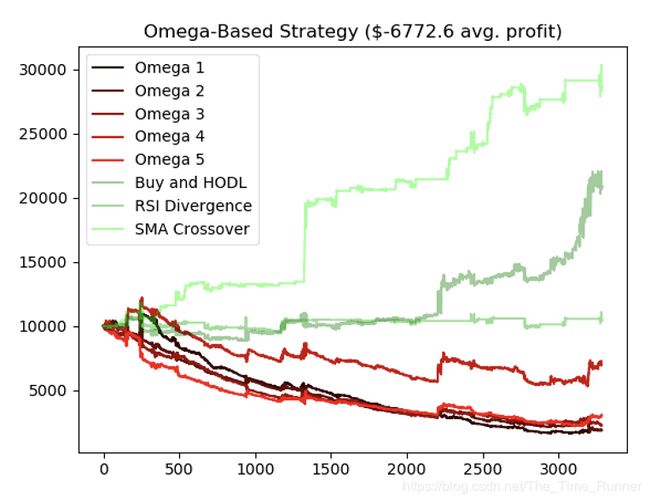
看看这个agent,明显这种奖励机制产生了过度交易策略,无法捕捉市场机会。
基于Calmar的策略略优于Omega策略,但最终结果类似。看起来我们投入大量时间和精力只是让事情变得更糟糕。
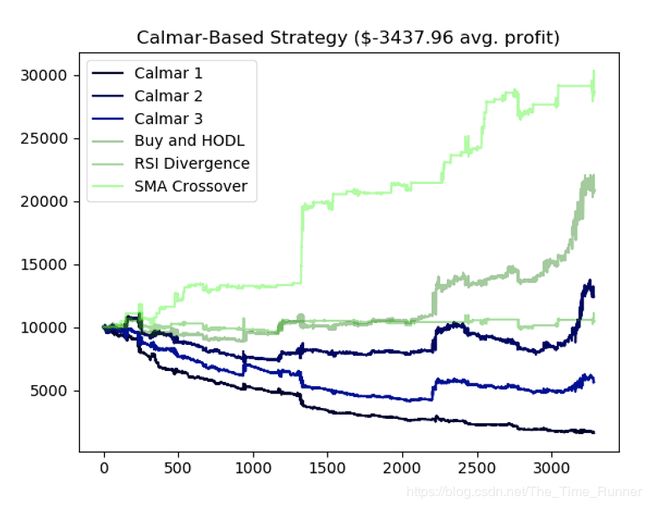
还记得我们的老朋友简单增量利润么?最然在上文这种奖励机制并未证明很成功,我们所作的修改和优化似乎大幅提升了agent的成功。
在四个月的测试期,平均收益350%。如果你不了解什么是平均市场收益,只要知道是一个疯狂的结果就可以了。当然,这是我们用强化学习的到的最好结果,对吧?

错。Sortino奖励的agent平均收益可达850%。当我看到这些策略的成功,我吓得赶紧检查下有没有错。(温馨提醒:接受下面这句话的讽刺吧)。己经排查,没有bug,此agent在交易BTC上就是这么牛逼。

不是过度交易和资本降低,这些agents似乎能理解低买高卖同时降低持币风险的重要性。不考虑agent具体学出了什么策略,我们的交易机器人明确学会了交易BTC赚钱。如果你不信,自己回测看看。
我不傻,我知道这样成功的回测应该不会再实际交易中发生。话虽如此,但这结果是我迄今见过最好的(这可能也是表明哪里有点不对劲的第一条线索)。想想蛮震惊的,这些程序没有任何金融市场如何工作或者如何做交易的先验知识,仅仅凭着尝试、犯错(也伴随这一些前视偏差)就能获的如此大的成功。当然是大量、大量、大量的尝试和犯错。
-
结论
本文中,优化了我们的强化学习agents使其在BTC交易中表现的更好,赚更多钱。工作量不小,不过我们根据如下步骤终是完成了:
- 用迭代的,LSTM网络及平稳数据更新现存的模型
- 用特定领域技术和统计分析为agent学习筛选出40+特征
- 提升agent原来的简单收益奖励系统以解释风险
- 用Bayes优化技术微调模型的超参数
- 以基础交易策略为基准,确保机器人总能打败市场
理论上,一个高收益的机器人是伟大的。然而,我收到了不少反馈说这些agents知识简单的学习拟合曲线,并不会在实盘中真正盈利。我们关于数据集切分成训练集/测试集的方式应该可以解释这个问题,的确我们的模型可能在这个数据集上过度拟合,不能在新数据集上表象良好。话虽如此,我的第六感告诉我,这些agent并非仅仅在拟合曲线,因此会在实盘中获利的。
为了实验这个假设,下篇文章会专注于将这些RLagents部署到真实环境。我们首先会更新环境以支持更多加密货币对如ETH/USD和LTC/USD。然后将其部署到Coinbase Pro交易所实盘交易。不管最终是否赚钱,这都是件令人兴奋的事儿,你一并不想错过。
顺便一提,要想改进agent表现还有很多工作要做,但我时间有限,而且已经为其投入甚多,如果你有兴趣可以在我工作的基础上继续改进,如果结果比我做的还好,可以底下留言,我们共同探讨。
再次声明,本系列文章用于教育,不作为实盘交易建议。你不应该基于本文的任何策略实盘交易,除非你想拿自己的真金白银打水漂。
感谢阅读,一如既往,本文所有代码都在以在我的Github上看到。如有问题及反馈,欢迎地下留言,期待你的声音。