textRank杂谈
转自:这些文章
1. PageRank算法概述
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名。
是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,自从Google在商业上获得空前的成功后,该 算法也成为其他搜索引擎和学术界十分关注的计算模型。目前很多重要的链接分析算法都是在PageRank算法基础上衍生出来的。PageRank是 Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。在揉合了诸如Title标识和 Keywords标识等所有其它因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中另网站排名获得提 升,从而提高搜索结果的相关性和质量。其级别从0到10级,10级为满分。PR值越高说明该网页越受欢迎(越重要)。例如:一个PR值为1的网站表明这个 网站不太具有流行度,而PR值为7到10则表明这个网站非常受欢迎(或者说极其重要)。一般PR值达到4,就算是一个不错的网站了。Google把自己的网站的PR值定到10,这说明Google这个网站是非常受欢迎的,也可以说这个网站非常重要。
2. 从入链数量到 PageRank
在PageRank提出之前,已经有研究者提出利用网页的入链数量来进行链接分析计算,这种入链方法假设一个网页的入链越多,则该网页越重要。早期的很多搜索引擎也采纳了入链数量作为链接分析方法,对于搜索引擎效果提升也有较明显的效果。 PageRank除了考虑到入链数量的影响,还参考了网页质量因素,两者相结合获得了更好的网页重要性评价标准。
对于某个互联网网页A来说,该网页PageRank的计算基于以下两个基本假设:
l 数量假设:在Web图模型中,如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
l 质量假设:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
利用以上两个假设,PageRank算法刚开始赋予每个网页相同的重要性得分,通过迭代递归计算来更新每个页面节点的PageRank得分,直到得分稳定为止。 PageRank计算得出的结果是网页的重要性评价,这和用户输入的查询是没有任何关系的,即算法是主题无关的。假设有一个搜索引擎,其相似度计算函数不考虑内容相似因素,完全采用PageRank来进行排序,那么这个搜索引擎的表现是什么样子的呢?这个搜索引擎对于任意不同的查询请求,返回的结果都是相同的,即返回PageRank值最高的页面。
3. PageRank算法原理
PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下:
1)在初始阶段:网页通过链接关系构建起Web图,每个页面设置相同的PageRank值,通过若干轮的计算,会得到每个页面所获得的最终PageRank值。随着每一轮的计算进行,网页当前的PageRank值会不断得到更新。
2)在一轮中更新页面PageRank得分的计算方法:在一轮更新页面PageRank得分的计算中,每 个页面将其当前的PageRank值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值。而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的PageRank得分。当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
3.2 基本思想:
如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/L(T)
其中PR(T)为T的PageRank值,L(T)为T的出链数
则A的PageRank值为一系列类似于T的页面重要性得分值的累加。
即一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
3.3 PageRank简单计算:
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。
![]()
继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
![]()
换句话说,根据链出总数平分一个页面的PR值。
![]()
例子:
如图1 所示的例子来说明PageRank的具体计算过程。

3.4 修正PageRank计算公式:
由于存在一些出链为0,也就是那些不链接任何其他网页的网, 也称为孤立网页,使得很多网页能被访问到。因此需要对 PageRank公式进行修正,即在简单公式的基础上增加了阻尼系数(dampingfactor)q, q一般取值q=0.85。
其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。 1-q= 0.15就是用户停止点击,随机跳到新URL的概率)的算法被用到了所有页面上,估算页面可能被上网者放入书签的概率。
最后,即所有这些被换算为一个百分比再乘上一个系数q。由于下面的算法,没有页面的PageRank会是0。所以,Google通过数学系统给了每个页面一个最小值。

这个公式就是.S Brin和 L. Page 在《The Anatomy of aLarge- scale Hypertextual Web Search Engine Computer Networks and ISDN Systems 》定义的公式。
所以一个页面的PageRank是由其他页面的PageRank计算得到。Google不断的重复计算每个页面的PageRank。如果给每个页面一个随 机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于正常和稳定。这就是搜索引擎使用它的原因。
4. PageRank幂法计算(线性代数应用)
4.1 完整公式:
关于这节内容,可以查阅:谷歌背后的数学
首先求完整的公式:
Arvind Arasu 在《Junghoo Cho Hector Garcia - Molina, Andreas Paepcke, SriramRaghavan. Searching the Web》 更加准确的表达为:

是被研究的页面,是链入页面的数量,是链出页面的数量,而N是所有页面的数量。
PageRank值是一个特殊矩阵中的特征向量。这个特征向量为:
R是如下等式的一个解:
如果网页i有指向网页j的一个链接,则
否则=0。
4.2 使用幂法求PageRank
那我们PageRank 公式可以转换为求解的值,
其中矩阵为 A = q × P + ( 1 一 q) * /N 。 P 为概率转移矩阵,为 n 维的全 1 行. 则 =
幂法计算过程如下:
X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1.
R = AX;
while (1 )(
if ( l X - R I < ){ //如果最后两次的结果近似或者相同,返回R
returnR;
} else {
X =R;
R = AX;
}
}
4.3 求解步骤:
一、 P概率转移矩阵的计算过程:
先建立一个网页间的链接关系的模型,即我们需要合适的数据结构表示页面间的连接关系。
1) 首先我们使用图的形式来表述网页之间关系:
现在假设只有四张网页集合:A、B、C,其抽象结构如下图1:
图1 网页间的链接关系
显然这个图是强连通的(从任一节点出发都可以到达另外任何一个节点)。
2)我们用矩阵表示连通图:
用邻接矩阵 P表示这个图中顶点关系 ,如果顶(页面)i向顶点(页面)j有链接情况 ,则pij = 1 ,否则pij = 0 。如图2所示。如果网页文件总数为N , 那么这个网页链接矩阵就是一个N x N 的矩 阵 。
3)网页链接概率矩阵
然后将每一行除以该行非零数字之和,即(每行非0数之和就是链接网个数)则得到新矩阵P’,如图3所示。 这个矩阵记录了 每个网页跳转到其他网页的概率,即其中i行j列的值表示用户从页面i 转到页面j的概率。图1 中A页面链向B、C,所以一个用户从A跳转到B、C的概率各为1/2。
4)概率转移矩阵P
采用P’ 的转置矩 阵进行计算, 也就是上面提到的概率转移矩阵P 。 如图4所示:
图2 网页链接矩阵: 图3 网页链接概率矩阵:
图4 P’ 的转置矩 阵
二、 A矩阵计算过程。
1)P概率转移矩阵 :
2)/N 为:
3)A矩阵为:q × P + ( 1 一 q) * /N = 0.85 × P + 0.15 */N
初始每个网页的 PageRank值均为1 , 即X~t = ( 1 , 1 , 1 ) 。
三、 循环迭代计算PageRank的过程
第一步:
因为X 与R的差别较大。继续迭代。
第二步:
继续迭代这个过程...
直到最后两次的结果近似或者相同,即R最终收敛,R 约等于X,此时计算停止。最终的R 就是各个页面的 PageRank 值。
用幂法计算PageRank 值总是收敛的,即计算的次数是有限的。
Larry Page和Sergey Brin 两人从理论上证明了不论初始值如何选取,这种算法都保证了网页排名的估计值能收敛到他们的真实值。
由于互联网上网页的数量是巨大的,上面提到的二维矩阵从理论上讲有网页数目平方之多个元素。如果我们假定有十亿个网页,那么这个矩阵就有一百亿亿个元素。这样大的矩阵相乘,计算量是非常大的。Larry Page和Sergey Brin两人利用稀疏矩阵计算的技巧,大大的简化了计算量。
5. PageRank算法优缺点
优点:
是一个与查询无关的静态算法,所有网页的PageRank值通过离线计算获得;有效减少在线查询时的计算量,极大降低了查询响应时间。
缺点:
1)人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题性降低
2)旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多上游链接,除非它是某个站点的子站点。
TextRankPageRank关键词提取算法
本文主要用于实现使用TextRank算法的关键字提取
TextRank是PageRank算法的变种,用于文本关键字 关键句的提取
主要参考为原作者Rada Mihalcea论文《TextRank:Bring Order into texts》
整个算法步骤:
【1】文本分词
可以使用常见的Java分词,本例使用的是IKAnalyer
【2】词性标注
这个暂时没有实现 【只是对提取效果会有一定的影响 一般会选择名次和动词作为关键字】 不影响算法思想实现
【3】构建初始转置矩阵【图的一种表示方式】
我们以文本对象中的每一个独立文本分词作为一个顶点,采用邻接矩阵来表示文本之间的关联,比如:
“A B C D”
"BC A"
"AC
|
|
A |
B |
C |
D |
| A |
0 |
0 |
0 |
0 |
| B |
1 |
0 |
0 |
0 |
| C |
1 |
1 |
0 |
0 |
| D |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(不知道怎么搞的 这表格删除不了多余 请无视)
words=【A,B,C,D】整个文档的单词数(去重复)
(每个单元格的含义:M[i,j]代表从j->i有指向意即单词words[j] 后面有单词words[i])
假设上面为3段待提取的文字,分词以空格形式切分,那么我们可以得到下面的一个矩阵M
对上面的矩阵稍作处理 使 每一列的值结果如下:[有点像单元化处理m[i][j]=m[i][j]/(sum[0-N][j])
|
|
A |
B |
C |
D |
| A |
0 |
0 |
0 |
0 |
| B |
1/2 |
0 |
0 |
0 |
| C |
1/2 |
1 |
0 |
0 |
| D |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
具体实现:部分源码
[java] view plaincopy
- /**
- * 传入经过分词处理后的wordsWrapper对象
- *matrix[i][j]代表从j->i有指向 现在为未带权处理
- * @param wordsWrapper
- * @return 返回生成的double矩阵
- */
- public static double[][] listToGraph(WordsWrapper wordsWrapper) {
- int wordCount = wordsWrapper.wordcount;
- List
nodulWords = Arrays.asList(wordsWrapper.nodulWords); - double[][] a = new double[wordCount][wordCount];
- ArrayList
content = wordsWrapper.words; - for (String x : content) {
- String xs[] = x.split(" ");
- int curindex = -1, preindex = -1, nextindex = -1;
- for (int i = 0; i < xs.length; i++) {
- String tx = xs[i];
- int index = nodulWords.indexOf(tx);
- if (i != 0) {
- preindex = nodulWords.indexOf(xs[i - 1]);
- }
- if (preindex != -1) {
- a[index][preindex] = 1d;
- }
- }
- }
- //just for test
- // System.out.println("before ...");
- //~~~test end here
- //初始矩阵处理
- for (int j = 0; j < wordCount; j++) {
- //这里可以修正 为带权值的
- int nozero = 0;
- for (int i = 0; i < wordCount; i++) {
- if (a[i][j] != 0) {
- nozero++;
- }
- }
- if (nozero != 0) {
- for (int i = 0; i < wordCount; i++) {
- a[i][j] = a[i][j] / nozero;
- }
- }
- }
- return a;
- }
【4】迭代运算
采用最大迭代次数和误差控制判断是否要求迭代
关于每个单词的PR(PageRank)值计算,在论文总是得分计算公式:
其中各个参数含义:
S(Vi)--顶点i的得分 可以理解为单词i的PR值
d-----阻尼系数 默认为;0.85
In(Vi)---所有指向顶点i的顶点 【比如:单词A 面跟着单词B 那么A属于In(B)】
|Out(Vj)|---节点j的出度【与图算法中的出度意义一样 上面的是入度】
具体实现:【最大迭代次数(20)和 最大容错率由自己指定(0.000001)】
[java] view plaincopy
- /**
- * 判断是否需要下一次pagerank迭代 会进行精度计算和总的迭代次数考虑
- *
- * @param before 之前迭代结果 PR值
- * @param cur当前迭代结果 PR值
- * @param curIteration 已经迭代次数
- * @return 是否需要下一次迭代
- */
- public static boolean neededDoNext(double[] before, double[] cur, int curIteration) {
- //先检查迭代次数是否已经超过最大迭代次数
- if (curIteration > MAX_ITERATE_NUM) {
- return false;
- } else {
- //精度要求
- int n = before.length;
- for (int i = 0; i < n; i++) {
- if (Math.abs(cur[i] - before[i]) > DEFAULT_ERROR_RATE) {
- return true;
- }
- }
- System.out.println("All is ok???");
- outputArray(before);
- outputArray(cur);
- //所有都满足精度要求
- return false;
- }
- }
迭代计算处理核心:
double []prevPR//记录前一次的算出来的pr值初始值设置为全0
double []curPR//记录当前算出的PR值初始值设定为全1/wordCount;
[java] view plaincopy
- while (neededDoNext(prevPR, curPR, iterationCount)) {
- //计算下一次迭代
- prevPR=curPR;
- curPR = doPageRank(transMatrix,prevPR,outDegrees);
- System.out.println("当前迭代次数:"+iterationCount+"RESULT:");
- outputArray(curPR);
- iterationCount++;
- }
效果演示:
总共迭代次数为:21
word->d score->0.4023749808259771
word->b score->0.3210029191796684
word->c score->0.5938468678121206
word->a score->0.4023749808259771
可以看出本文的关键字应该是C 注意pagerank可能不会收敛 所以设置最大迭代次数
【5】后处理
提供将临近的关键字 结合起来形成新的关键字【未完成】
【6】写在最后
由于看的是英文的论文 可能有的理解有失偏颇有的地方理解的不到位还望指教,
还有如果使用带权图可以获得更好的计算效果【论文中有叙述】实现起来也就是修改PR[i] 或者score的计算,原理是一样
Textrank算法介绍
先说一下自动文摘的方法。自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
- 基于整数规划:将文摘问题转为整数线性规划,求全局最优解。
textrank算法
TextRank算法基于PageRank,用于为文本生成关键字和摘要。
PageRank
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:
S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。
根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
|
1
2
3
4
5
6
7
8
9
10
11
|
PR = [
PR =
disp(iter);
disp(PR);
|
运行结果(省略部分):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
95
0
0
0
96
0
0
0
97
0
0
0
98
0
0
0
99
0
0
0
100
0
0
0
|
最终A的PR值为0.4050,B和C的PR值为0.1500。
如果把上面的有向边看作无向的(其实就是双向的),那么:
|
1
2
3
4
5
6
7
8
9
10
11
|
PR = [
PR =
disp(iter);
disp(PR);
|
运行结果(省略部分):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
98
1
0
0
99
1
0
0
100
1
0
0
|
依然能判断出A、B、C的重要性。
TextRank
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:

其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
1. 基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中是保留后的候选关键词。
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
TextRank源码解析
1.读入文本,并切词,对切词结果统计共现关系,窗口默认为5,保存大cm中
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
cm
=
defaultdict(
int
)
#切词
words
=
tuple
(
self
.tokenizer.cut(sentence))
for
i, wp
in
enumerate
(words):
#(enumerate枚举的方式进行)
#过滤词性,停用词等
if
self
.pairfilter(wp):
for
j
in
xrange
(i
+
1
, i
+
self
.span):
if
j >
=
len
(words):
break
if
not
self
.pairfilter(words[j]):
#过滤
continue
#保存到字典中
if
allowPOS
and
withFlag:
cm[(wp, words[j])]
+
=
1
else
:
cm[(wp.word, words[j].word)]
+
=
1
|
TextRank算法提取关键词的Java实现
谈起自动摘要算法,常见的并且最易实现的当属TF-IDF,但是感觉TF-IDF效果一般,不如TextRank好。
TextRank是在Google的PageRank算法启发下,针对文本里的句子设计的权重算法,目标是自动摘要。它利用投票的原理,让每一个单词给它的邻居(术语称窗口)投赞成票,票的权重取决于自己的票数。这是一个“先有鸡还是先有蛋”的悖论,PageRank采用矩阵迭代收敛的方式解决了这个悖论。TextRank也不例外:
PageRank的计算公式:
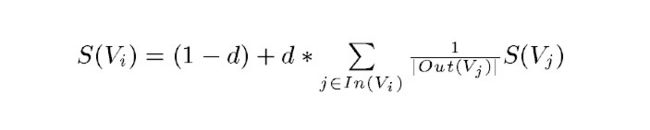
正规的TextRank公式
正规的TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。

但是很明显我只想计算关键字,如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,这里称关键字提取算法为PageRank也不为过。
另外,如果你想提取关键句(自动摘要)的话,请参考姊妹篇《TextRank算法自动摘要的Java实现》。
TextRank的Java实现
先看看测试数据:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
我取出了百度百科关于“程序员”的定义作为测试用例,很明显,这段定义的关键字应当是“程序员”并且“程序员”的得分应当最高。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
[程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, 开发/v, 、/w, 维护/v, 的/uj, 专业/n, 人员/n, 。/w, 一般/a, 将/d, 程序员/n, 分为/v, 程序/n, 设计/vn, 人员/n, 和/c, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/r, 的/uj, 界限/n, 并/c, 不/d, 非常/d, 清楚/a, ,/w, 特别/d, 是/v, 在/p, 中国/ns, 。/w, 软件/n, 从业/b, 人员/n, 分为/v, 初级/b, 程序员/n, 、/w, 高级/a, 程序员/n, 、/w, 系统/n, 分析员/n, 和/c, 项目/n, 经理/n, 四/m, 大/a, 类/q, 。/w]
然后去掉里面的停用词,这里我去掉了标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
[程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理]
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:
{开发=[专业, 程序员, 维护, 英文, 程序, 人员],
软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员],
程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国],
分析员=[程序员, 系统, 项目, 经理, 高级],
维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员],
系统=[程序员, 分析员, 项目, 经理, 分为, 高级],
项目=[程序员, 分析员, 系统, 经理, 高级],
经理=[程序员, 分析员, 系统, 项目],
分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员],
英文=[专业, 开发, 程序员, 维护, 程序],
程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员],
特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员],
专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员],
设计=[程序员, 编码, 分为, 程序, 人员],
编码=[设计, 界限, 程序, 中国, 特别, 人员],
界限=[软件, 编码, 程序, 中国, 特别, 人员],
高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员],
中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员],
人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]}
然后开始迭代投票:
- for (int i = 0; i < max_iter; ++i)
- {
- Map<String, Float> m = new HashMap<String, Float>();
- float max_diff = 0;
- for (Map.Entry<String, Set<String>> entry : words.entrySet())
- {
- String key = entry.getKey();
- Set<String> value = entry.getValue();
- m.put(key, 1 - d);
- for (String other : value)
- {
- int size = words.get(other).size();
- if (key.equals(other) || size == 0) continue;
- m.put(key, m.get(key) + d / size * (score.get(other) == null ? 0 : score.get(other)));
- }
- max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));
- }
- score = m;
- if (max_diff <= min_diff) break;
- }
排序后的投票结果:
[程序员=1.9249977,
人员=1.6290349,
分为=1.4027836,
程序=1.4025855,
高级=0.9747374,
软件=0.93525416,
中国=0.93414587,
特别=0.93352026,
维护=0.9321688,
专业=0.9321688,
系统=0.885048,
编码=0.82671607,
界限=0.82206935,
开发=0.82074183,
分析员=0.77101076,
项目=0.77101076,
英文=0.7098714,
设计=0.6992446,
经理=0.64640945]
程序员果然荣登榜首,并且分数也有区分度,嗯,勉勉强强。
开源项目地址
本文代码已集成到HanLP中开源:http://www.hankcs.com/nlp/hanlp.html
目前能够提供分词、词性标注、命名实体识别、关键字提取、短语提取、自动摘要、自动推荐,依存关系、句法树等功能。