【selenium爬虫】Yhen手把手带你用selenium自动化爬虫爬取海贼王动漫图片
以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,转载请说明出处,谢谢合作!
大噶好!我是python练习时长一个月的Yhen.很高兴能在这里和大家分享我的学习经验。作为小白,我在写代码的时候可能会遇到各种各样的BUG,我把我的一些经验分享给大家,希望对大家能有所帮助!
今天要带大家用一个比较特别的爬虫方式——selenium来实现爬取百度图片里的海贼王图片。后面会把源码也给到大家哦,因为比较详细,所以篇幅可能会较长,所以如果只想看结果的同学可以直接去看后面的源码哦。
———————— 手动分割线————————————————
好啦,马上开始今天的分享
闲来无事想爬点动漫图片玩玩
爬什么动漫好呢?
打开了百度图片 搜索了壁纸
在动漫专栏专栏分区浏览一通
嘿咻~就决定是你了
“海贼王”
虽然我没怎么看过这部动漫
但对它的精湛画工早有耳闻
相信很多小伙伴都很钟爱这部动漫作品吧
里面的图片都是很酷的
url :
壁纸 卡通动漫 海贼王
要知道,这里可不止这几十张图
一直翻到到最底部
一共是有447多张的图片
我们今天的目标就是把这447张图片一张不漏的都爬取下来
有了需求,就来开始思路分析了:
既然我们要爬的图片
自然就很容易想到一种普遍的思路:
1.先对首页界面发送请求,获取页面数据
2.进行数据提取,获取图片的链接
3.对图片链接发送请求,获取图片数据
4.把图片保存到本地
这不是就跟之前爬表情包一样嘛?so easy 啦,10分钟给你搞定!
但是…事实真的这么简单吗?
来,我先带你用爬图片的通用方法进行演示
首先是简单的导包和发送请求
# 导入爬虫库
import requests
# 导入pyquery数据提取库
from pyquery import PyQuery as pq
# 首页网址
url = "https://image.baidu.com/search/index?ct=&z=&tn=baiduimage&ipn=r&word=%E5%A3%81%E7%BA%B8%20%E5%8D%A1%E9%80%9A%E5%8A%A8%E6%BC%AB%20%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0&istype=2&ie=utf-8&oe=utf-8&cl=&lm=-1&st=-1&fr=&fmq=1587020770329_R&ic=&se=&sme=&width=1920&height=1080&face=0&hd=&latest=©right="
# 请求头
headers ={"User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36"}
#对首页地址发送请求,返回文本数据
response = requests.get(url).text
print(response)
是可以正常的得到数据的

然后就是数据提取了
首先打开检查工具
定位到第一张照片
在右边可以看到在class 类选择器为main_img img-hover 里面的data-imgurl属性 对应着有一个链接 https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=1296489273,320485179&fm=26&gp=0.jpg
我们访问一下
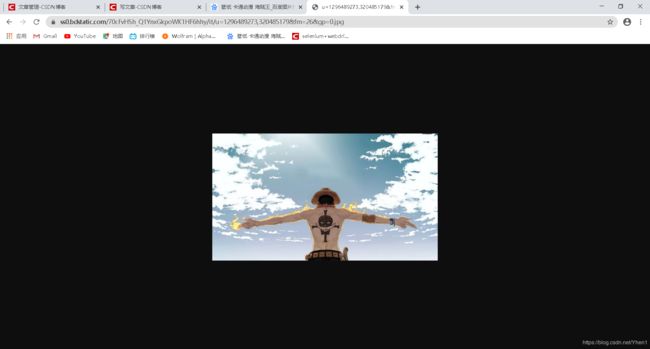
原来就是我们要找的图片详情页的
所以接下来我们用pyquery来进行数据提取
看看能不能把刚刚的链接提取出来
因为这个不是今天的重点,我就直接给你们演示代码了。
如果想知道pyquery怎么使用,
可以去看我前面几篇博文
# 数据初始化
doc = pq(response)
# 通过类选择器main_img img-hover 来提取数据 注意:中间的空格用.代替
main_img = doc(".main_img.img-hover").text()
print(main_img)
打印下看看能不能得到我们想要的数据

oh no,怎么什么都没有呢?!
在确定我们写的代码没有问题后,
我的第一反应是:被反爬了!!!
不要紧,如果是被反爬,我们在请求头加多几个参数就好了
我把请求数据类型,用户信息,防盗链都加进请求头里
# 请求头
# 浏览器类型
headers ={"User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36",
# 请求数据类型
"Accept':'application/json, text/javascript, */*; q=0.01",
# 用户信息
"Cookie':'BIDUPSID=19D65DF48337FDD785B388B0DF53C923; PSTM=1585231725; BAIDUID=19D65DF48337FDD770FCA7C7FB5EE199:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; indexPageSugList=%5B%22%E9%AB%98%E6%B8%85%E5%A3%81%E7%BA%B8%22%2C%22%E5%A3%81%E7%BA%B8%22%5D; delPer=0; PSINO=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BCLID=8092759760795831765; BDSFRCVID=KH_OJeC62A1E9y7u9Ovg2mkxL2uBKEJTH6aoBC3ekpDdtYkQoCaWEG0PoM8g0KubBuN4ogKK3gOTH4AF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tJCHoK_MfCD3HJbpq45HMt00qxby26niWNO9aJ5nJDoNhqKw2jJhef4BbN5LabvrtjTGah5FQpP-HJ7tLTbqMn8vbhOkahoy0K6UKl0MLn7Ybb0xynoDLRLNjMnMBMPe52OnaIbp3fAKftnOM46JehL3346-35543bRTLnLy5KJYMDcnK4-XD653jN3P; ZD_ENTRY=baidu; H_PS_PSSID=30963_1440_21081_31342_30824_26350_31164",
# 防盗链
"Referer':'https://image.baidu.com/search/index?ct=&z=&tn=baiduimage&ipn=r&word=%E5%A3%81%E7%BA%B8%20%E5%8D%A1%E9%80%9A%E5%8A%A8%E6%BC%AB%20%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0&istype=2&ie=utf-8&oe=utf-8&cl=&lm=-1&st=-1&fr=&fmq=1587020770329_R&ic=&se=&sme=&width=1920&height=1080&face=0&hd=&latest=©right="
}
再次请求,看看能否得到我们要的数据
。。。。。。
不是吧…还不行?
自闭了…
没事,这点挫折怎么能难倒我!!!
我们来逆向分析一波
我们是通过类选择器main_img img-hover来定位数据的
但是没有获取到任何的数据
在代码正确且没有被反爬的前提下
还出现这种情况
那么
…真相只有一个!
我们一开始请求到的首页数据根本就没有main_img img-hover这个类选择器!!!
我们来验证下这个首页数据是不是罪魁祸首
首先打印请求到的首页数据,然后在里面搜索main_img img-hover
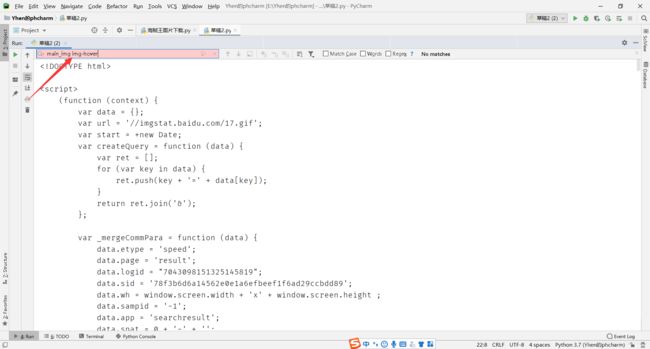
搜索发现,冒红了
果然是这个家伙在搞鬼啊
长能耐了!居然不给我数据!
那么事实证明,首页页面是动态数据,他的数据接口并不是首页的网址!
现在这种情况后,有两种解决方法
一.在这些茫茫接口中,找到首页页面数据的接口
二.直接用selenium对页面进行请求
不知你们选择哪一种,反正让我在这么多的数据中找一个接口,我是拒绝的!!!多费事费力
selenium它不香吗?
为什么呢?
因为用selenium把网页打开,所有信息就都会加载到了Elements那里,之后,就可以把动态网页用静态网页的方法爬取了。
意思就是
我们只要selenium对首页进行请求,获取到的数据,就是我们按f12后在控制台看到的源码!就不用在辛辛苦苦的找接口啦!
关于selenium,最常用的用法还是自动化,selenium可以真实的自动开始一个浏览器,模拟用户操作,例如实现自动登录,自动翻页等等。
想了解更多的同学可以参照这个中文翻译文档
https://selenium-python-zh.readthedocs.io/en/latest/
OK说干就干
首先是导包
然后是配置浏览器,selenium有可视模式(真实的打开一个浏览器,你可以看到浏览器的操作)和静默模式(在后台运行,不可见)
我们今天采用静默模式。因为如果重点是爬虫,不需要看到浏览器操作,而且每次都打开一个浏览器太烦了,也耗内存。
还有一个重要的点就是,要使用selenium首先要装一个对应你浏览器的webdriver驱动,并放到你py文件同路径下,这样selenium才能实现模拟浏览器操作
各种浏览器驱动的下载地址,可参考
https://www.jianshu.com/p/6185f07f46d4
webdriver要和py文件放在一起

下面是selenium的静默模式配置
比较麻烦,但是都是死操作,大家熟悉即可
from selenium import webdriver #调用webdriver模块
from selenium.webdriver.chrome.options import Options # 调用Options类
chrome_options = Options() # 实例化Option
chrome_options.add_argument('--headless') # 设置浏览器启动类型为静默启动
driver = webdriver.Chrome(options = chrome_options) # 设置浏览器引擎为Chrome
你要是问我具体每一步为什么这么设置,我也不知道,人家就是这么规定的。想要了解更多可以去看文档
但是只是静默模式设置麻烦一点,可视模式两三行代码就设置完了
设置完以后
就可以用selenium来发送请求啦
#对首页进行请求
driver.get('https://image.baidu.com/search/index?ct=&z=&tn=baiduimage&ipn=r&word=%E5%A3%81%E7%BA%B8%20%E5%8D%A1%E9%80%9A%E5%8A%A8%E6%BC%AB%20%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0&istype=2&ie=utf-8&oe=utf-8&cl=&lm=-1&st=-1&fr=&fmq=1587020770329_R&ic=&se=&sme=&width=1920&height=1080&face=0&hd=&latest=©right=')
# 返回页面源码
response = driver.page_source
大家注意,要获得页面的源码要用driver.page_source
而且是直接给我们返回了字符串格式的数据
我们来打印返回的数据康康
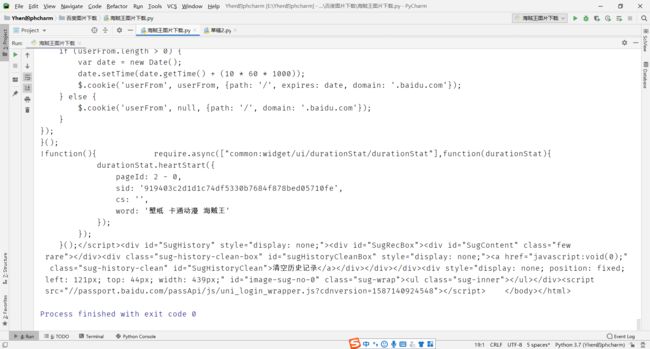
是成功的获取到了数据
那我们现在再在得到的数据中搜索 main_img img-hover
看看这次是不是真的得到了我们想要的数据

登登登登
这回总没问题了吧,我们要的图片网址也在这了
接下来就可以一路狂飙
用pyquery来提取出图片网址
首先 数据初始化,然后 通过类选择器提取数据,遍历以后 通过属性“data-imgurl”取出图片链接
代码如下
from pyquery import PyQuery as pq
# 数据初始化
doc = pq(response)
# 通过类选择器提取数据
x = doc(".main_img.img-hover").items()
count = 0
# 遍历数据
for main_img in x :
# 通过属性“data-imgurl”取出图片链接
image_url = main_img.attr("data-imgurl")
print(image_url)
历经千辛万苦
终于就要成功得到图片网址了
害 不容易啊
于是我怀着激动的心情去打印了图片网址

结果发现…
WHAT???
我们刚刚的页面四百多张图片,
你就给我返回20条URL???剩下的你吃了????
有意思有意思。跟我作对是吧,但是魔高一尺道高一丈
我回到网页中去
在刚刚的源码中ctrl + F 打开搜索功能
搜索main_img img-hover
发现这里也只有一共只有20条搜索结果
然后我马上想到,刚刚的四百多张图片是我们通过不断下拉,不断加载得来的
所以很有可能是因为初始也页面的没有加载完成,想要获取到剩下的url就必须让selenium操控浏览器不断下拉
怎么实现呢?
我也不知道哈哈哈哈
但是我会百度,不会我就问度娘
找到一篇csdn文章有介绍到怎么用selenium模拟下滑到底部操作
原文链接
https://blog.csdn.net/weixin_43632109/article/details/86797701

但是,要知道,要得到四百多张图片的数据,不是仅仅靠一次下滑底部的操作就能实现的,必须要让selenium在获取源码数据前执行多次下滑底部操作,才能得到全部的数据
那么怎么实现多次操作呢
我设置了一个for循环
先看看代码
import time
# 执行24次下滑到底部操作
for a in range(25):
# 将滚动条移动到页面的底部
js = "var q=document.documentElement.scrollTop=1000000"
driver.execute_script(js)
# 设置一秒的延时 防止页面数据没加载出来
time.sleep(1)
我设置了循环次数为25
为什么是25呢?
因为是我之前自己测试过,25次刚好能取到最后一张图片哈哈哈
你们爬别的页面的时候就要自己测试循环次数啦
现在我们再来看看现在获取的图片链接

很明显我们这次获取的数据多了很多
我点击最后一条链接

可以看到,最后一个链接其实就是最后一张图片的链接
所以我们是成功的得到了所有的图片链接了
接下来就是对这些图片发送请求,获取数据并保存到本地就ok啦
import request
#定义count初始值为0
count = 0
# 遍历数据
for main_img in x :
# 通过属性提取出图片网址
# 通过属性“data-imgurl”取出图片链接
image_url = main_img.attr("data-imgurl")
#对图片链接发送请求,获取图片数据
image =requests.get(image_url)
# 在海贼王图片下载文件夹下保存为jpg文件,以“wb”的方式写入 w是写入 b是进制转换
f = open("海贼王图片下载/" + "{}.jpg".format(count), "wb")
# 将获取到的数据写入 content是进制转换
f.write(image.content)
# 关闭文件写入
f.close()
#意思是 count = count+1
count+=1
发送请求还是用我们的经典爬虫库requests
首先发送请求获取数据
然后 在海贼王图片下载文件夹下保存为.jpg文件,以“wb”的方式写入 w是写入 b是进制转换
将获取的数据写入进去,注意图片要用content进制转换
最后关闭文件写入
执行程序后
看看能否把全部的图片都下载下来
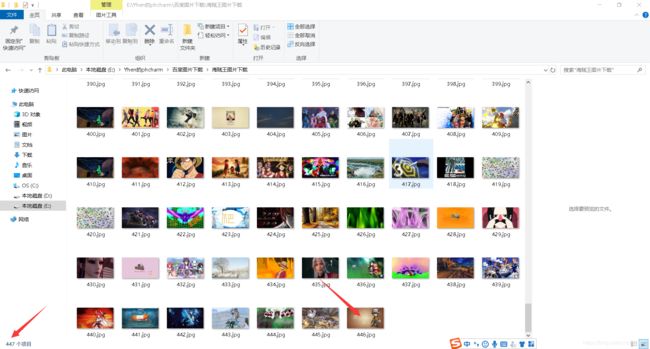
完美!成功把网页上的一共447张的图片下载了下来
撒花完结!
最后把源码大家
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from pyquery import PyQuery as pq
import requests
# 实例化一个options对象
chrome_options =Options()
# 把浏览器设置为静默模式
chrome_options.add_argument("headless")
driver = webdriver.Chrome(options=chrome_options)
# 对首页进行请求
driver.get('https://image.baidu.com/search/index?ct=&z=&tn=baiduimage&ipn=r&word=%E5%A3%81%E7%BA%B8%20%E5%8D%A1%E9%80%9A%E5%8A%A8%E6%BC%AB%20%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0&istype=2&ie=utf-8&oe=utf-8&cl=&lm=-1&st=-1&fr=&fmq=1587020770329_R&ic=&se=&sme=&width=1920&height=1080&face=0&hd=&latest=©right=')
# 执行24次下滑到底部操作
for a in range(25):
# 将滚动条移动到页面的底部
js = "var q=document.documentElement.scrollTop=1000000"
driver.execute_script(js)
# 设置一秒的延时 防止页面数据没加载出来
time.sleep(1)
# 返回页面源码
response = driver.page_source
# print(response)
# 数据初始化
doc = pq(response)
# 通过类选择器提取数据
x = doc(".main_img.img-hover").items()
#定义count初始值为0
count = 0
# 遍历数据
for main_img in x :
# 通过属性提取出图片网址
# 通过属性“data-imgurl”取出图片链接
image_url = main_img.attr("data-imgurl")
#对图片链接发送请求,获取图片数据
image =requests.get(image_url)
# 在海贼王图片下载文件夹下保存为jpg文件,以“wb”的方式写入 w是写入 b是进制转换
f = open("海贼王图片下载/" + "{}.jpg".format(count), "wb")
# 将获取到的数据写入 content是进制转换
f.write(image.content)
# 关闭文件写入
f.close()
# 意思是 count = count + 1
count+=1
接下来到我的吹水环节
【Yhen说】
大家好久不见啊,由于许多的缘故有一段时间没有发爬虫文章了。前天中午爬酷我的文章没有审核过后,下午我就在寻思下一篇文章写什么了。突然想到也许试试爬百度的图片,于是我就先自己尝试了。本来以为会是很顺利的,就像我文章写到那样,直接用普通的爬虫方法就能搞定,试过了才发现没有这么简单。因为这次的内容完全是自己的方法思路,不像以前都是跟着老师走。六星的老师也有出过爬百度图片的教程,但我在写这篇文章前没有去看,就是想试试自己是不是也能独立做出一个项目来。写完之后我找出老师的视频看,发现老师是用找接口的方法的。我这种方法也算是一种创新吧。用selenium后还是出现数据不全的问题,又困扰了我一会。不过我找了资料后,就被我解决了。学习,不就是不断的发现问题,然后解决问题的过程嘛。当我最后成功的把这447张图片爬下来的时候,我是非常有成就感的哈哈哈。所以,希望大家有空也试试,在遵守网络协议的前提下,用爬虫去做自己感兴趣的事,可能做的过程会遇到很多的挫折,但是当你成功后,你内心有多激动只有你自己才知道。也证明你学了python能真正为你所用,也没白浪费时间对吧!加油!
昨天居然在一个不知名的网站上找到我写的那篇爬小说的文章…也没有添加出处来源。准备联系csdn以及相关人员交涉了,所以还是那句话,欢迎大家看我文章来学习,但是转载请说明出处,并且禁止用于商业用途!谢谢大家的配合。
很开心能在这里把我的经验分享给大家,希望对大家有所帮助。如果有什么不懂的或者想对我提什么建议的欢迎在评论区留言!
如果觉得我写的对你有帮助的同学可以点个小赞嘛,加个关注就更好了。你们的支持是我创作的动力。以后有机会也会分享更多的经验给大家。
我是Yhen,我们下期见
【往期文章回顾】
【爬虫】Yhen手把手带你用python爬小说网站,全网打尽,想看就看!
(这可能会是你看过最详细的教程)
【爬虫】Yhen手把手带你用python爬取知乎大佬热门文章
【爬虫】Yhen手把手教你爬取表情包,让你成为斗图界最靓的仔
【爬虫】Yhen手把手带你爬取去哪儿网热门旅游信息(并打包成旅游信息查询小工具