Attention Model 在自然语言处理里的应用
本文的目标是介绍Attention Model在自然语言处理里的应用,本文的结构是:先介绍两篇经典之作,一篇NMT,一篇是Image Caption;之后介绍Attention在不同NLP Task上的应用,在介绍时有详有略。
经典之作
有两篇文章被Attention的工作广泛引用,这里单拎出来介绍:
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
NMT通常用encoder-decoder family的方法,把句子编码成一个定长向量,再解码成译文。作者推测定长向量是encoder-decoder架构性能提升的瓶颈,因此让模型自动寻找(与预测下一个词相关的)部分原文。

Encoder部分,作者使用了Bidirectional RNN for annotating sequences
这是PPT介绍
http://www.iclr.cc/lib/exe/fetch.php?media=iclr2015:bahdanau-iclr2015.pdf
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
这篇文章的任务是给图片起个标题,我自己做了一页PPT总结了文章思路

接下来介绍自然语言处理各种Task中的Attention应用。
Attention in Word Embedding
Not All Contexts Are Created Equal: Better Word Representations with Variable Attention
The general intuition of the model is that some words are only relevant for predicting local context (e.g. function words), while other words are more suited for determining global context, such as the topic of the document.
In CBOW:
In this paper:
each word wi at relative position i is attributed an attention level representing how much the attention model believes this it is important to look at in order to predict the center word
Gradients of the loss function with respect to the parameters (W,O,K,s) are computed with backpropagation, and parameters are updated after each training instance using a fixed learning rate.

Attention in Machine Translation
Effective Approaches to Attention-based Neural Machine Translation
Global Attention
这里的 at 是Global Align Weights,它的size是由the number of time steps on the source side决定的,之后的 ct 是由source hidden states h¯s 和 at 的weighted average计算出的。

这里的score function可以有多种:
除这些之外,作者还实验了 at=softmax(Waht)
Local Attention
The context vector ct is then derived as a weighted average over the set of source hidden states within the window [pt−D,pt+D] ; D is empirically selected.
Unlike the global approach, the local alignment vector at is now fixed-dimensional, i.e., ∈R2D+1 .(这是定义级的区别)
接下来作者把模型做了两种变种:
Monotonic alignment (local-m)
simply set pt=t assuming that source and target sequences are roughly monotonically aligned. at 的公式同global
Predictive alignment (local-p)
修改定义
其中
As a result, attention model will favor alignment points near pt .
In our proposed global and local approaches, the attentional decisions are made independently, which is suboptimal.
在标准的MT中,有一个coverage set记录哪些词被翻译过了,在这个模型中attentional vectors h~t are concatenated with inputs at the next time steps. 作者把它称作input-feeding approach.
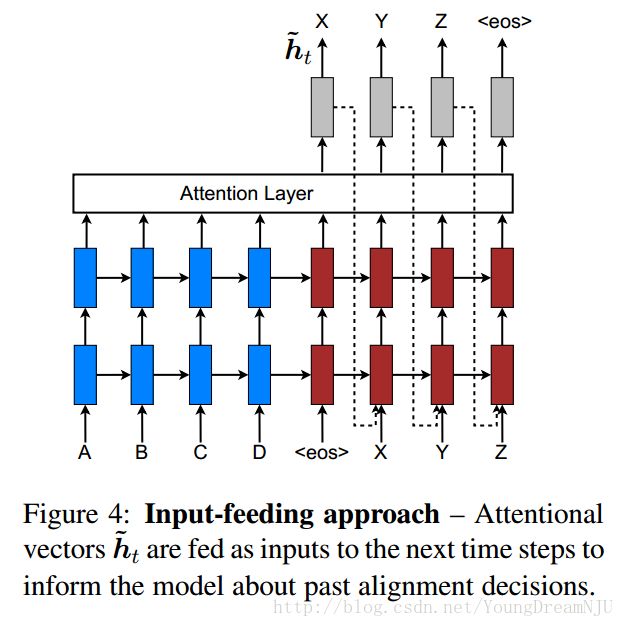
The effects of having such connections are two-fold: (a) we hope to make the model fully aware of previous alignment choices and (b) we create a very deep network spanning both horizontally and vertically.
Attention in QA
Character-Level Question Answering with Attention
- Encode the Entities and Predicates in the KB
- Encode the Query
- Decoding the KB Query
3.1. An LSTM-based decoder with attention
3.2. A pairwise semantic relevance function that measures the similarity between the hidden units of the LSTM and the embedding of an entity or predicate candidate
小结
通过以上具体的解释,我们可以看出:
The basic idea of attention mechanism is that it assigns a weight/importance to each lower position when computing an upper level representation.
下面再看一些其他任务上Attention Model的应用。
Attention in Document Classification
Hierarchical Attention Networks for Document Classification
先用词表示、双向GRU、Attention生成句子表示,再用一样的方法生成文档表示v,最后softmax(Wv+b)用于文档分类。
Attention in Language to Logical Form
Language to Logical Form with Neural Attention
本文要把自然语言转化成逻辑表达式,创造了2个模型:1)Sequence-to-Sequence Model把语义解析当做普通的序列转换任务;2)Sequence-to-Tree Model用层次树解码器获得逻辑形式的结构,先翻译第一层,再翻译下一层。最后在翻译的时候加入了Attention机制。
Attention in Summarization
A Neural Attention Model for Abstractive Sentence Summarization
与以上类似
就写这么多了,请各位批评指正,谢谢!
Reference
- Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.
- Xu K, Ba J, Kiros R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention[J]. Computer Science, 2016:2048-2057.
- Ling W, Tsvetkov Y, Amir S, et al. Not All Contexts Are Created Equal: Better Word Representations with Variable Attention[C]// Conference on Empirical Methods in Natural Language Processing. 2015:1367-1372.
- Luong M T, Pham H, Manning C D. Effective Approaches to Attention-based Neural Machine Translation[J]. Computer Science, 2015.
- Golub D, He X. Character-Level Question Answering with Attention[J]. 2016.
- Yang Z, Yang D, Dyer C, et al. Hierarchical Attention Networks for Document Classification[C]// Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016:1480-1489.
- Dong L, Lapata M. Language to Logical Form with Neural Attention[C]// Meeting of the Association for Computational Linguistics. 2016:33-43.
- Rush A M, Chopra S, Weston J. A Neural Attention Model for Abstractive Sentence Summarization[J]. Computer Science, 2015.