再记一次ceph object unfound的艰辛历程
文章目录
- 先说问题:
- 再说解决
- 尝试1:
- 尝试2(该尝试建议先在自己环境搭配对应业务测试通过后再现场尝试):
感谢 学无止境996同学的陪伴和vigourtyy美丽女友的支持,直到这个解决问题的深夜
先说问题:
ceph 12.2.1生产环境:3副本 tier + 3副本data
机房在拥有业务的情况下重启集群交换机,产生如下场景:
- time 1: osd.1 down, osd.2 osd.3 up
此时数据先落到2,3上(2为primary) - time 2: osd.1 osd.2 osd.3 up
此时状态机触发peering,根据pg_info和pg_log,构建missing列表,依据此列表进行后续的recovery(默认此时仅pg部分数据有变化,可通过权威日志恢复),但此时recovery并未完全恢复 - time 3: osd.1 osd.2 up, osd.3 down
根据此时osd的状态,因为上一个时间点osd.3上部分数据并未完全recover到osd.1上,此时osd.3就down了,但是对于osd.1来说已经获取到了missing列表并且将该列表中的对象操作数据追加到了pg_log_entry中,依此来pull或者push数据。但是此时osd.3已经down,这一些数据无法成功获取到osd.1上。此时集群的状态就会出现object unfound的情况,如下图:

我们的生产环境更是异常问题的叠加,因为出现unfound的对象,同时又出现osd无法成功Recover而报出的段错误无法启动,此时丢掉的对象如果想要恢复,貌似只有revert或者delete了
关于PGlog的相关描述以及pg_log和pg_info如何参与到状态机中进行peer,recover和backfill的相关过程可以参考PGlog写流程梳理
知道了问题,并且能够复现问题,接下来就是如何解决的过程了。
再说解决
首先我们知道部分数据并未完全丢失,它可能是存在于down掉的osd中,为了后续的恢复,我们先将down掉的osd进行数据备份。
使用dd将down掉的osd所在的磁盘数据备份到一块空的磁盘上即可。
操作前先分析当前异常环境的处境以及我们想要达到的最终目标:
我们拥有的资源:备份完好的osd磁盘(数据未丢失)
我们的处境:对象丢失,深层含义就是当前环境没有任何一个up的osd承载该对象,但是该对象的操作版本被pg_log记录,环境曾经有过该对象。
分析:加入我们没有备份好的数据资源,遇到这样的情况貌似只能对unfound对象所在pg进行revert和delete了,但是我们备份了数据
最终要做的就是尽可能完整得将我们备份的数据迁移至现有集群,让改集群unfound的对象一一恢复
尝试1:
对象级别的操作工具我们能够想到的ceph-object-tool,rados这两个利器
对象的构成我们宏观来看:即数据+元数据
刚好,ceph-object-tool工具拥有参数get-bytes,set-bytes,get-attr,set-attr这样的子命令。
于是我们尝试将备份的磁盘数据中将对应的丢失对象使用get-bytes获取出来,然后再使用set-bytes将该对象的数据写回集群,同时将对应对象的属性也设置回集群,这样我们猜想,osd起来之后有了对象以及对象的元数据,即可成功恢复。操作如下:
-
挂载备份数据的磁盘分区
a.mkdir /ceph-0
b.mount /dev/sdb1 /ceph-0 -
查看丢失的对象
a.ceph health detail获取丢失对象的pg id
b.ceph pg 14.20 list_missing列出丢失对象的pg 14.20的丢失对象信息 -
从备份的磁盘分区中获取丢失的对象数据和元数据
a.ceph-objectstore-tool --data-path /ceph-0/ --type bluestore obj470 get-bytes obj470.txt获取对象obj470的数据,并放入到obj470.txt文件
关于ceph-object-tool工具的使用可以参考ceph-object-tool使用详解
b.ceph-objectstore-tool --data-path /ceph-0/ --type bluestore obj470 get-attrs _ > obj470.attr获取对象obj470的属性数据,即元数据信息到obj470.attr中
src/common/ceph_objectstore_tool.cc中可以看到该属性信息为object_info_t数据

则我们可以通过命令ceph-dencoder来解码查看,关于ceph-dencoder命令的使用可以参考文档ceph-dencoder使用详解
ceph-dencoder type object_info_t import obj470.attr decode dump_json
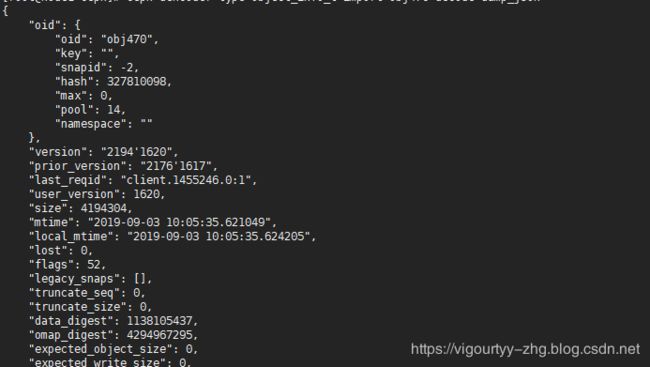
-
将获取到的数据设置到集群osd中,此时需要osd的状态为down,能够操作
/var/lib/ceph/osd/ceph-id目录
a.ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0/ --type bluestore obj470 set-attrs _ obj470.attr设置对象属性
b.ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0/ --type bluestore obj470 set-bytes obj470.txt设置对象数据信息
此时有两种情况:
如果对象的have版本为0'0,即对象当前并不存在于集群中,集群只有一个初始的空版本对象,执行以上命令会有如下输出
No object id 'get-bytes' found or invalid JSON specified
显然该方案走到这里即出现阻塞性的情况,对应对象版本为0'0的对象该如何修复?
尝试2(该尝试建议先在自己环境搭配对应业务测试通过后再现场尝试):
至此我们已经能够获取到对象的数据,但是因为集群中对象版本为0'0的对象是不存在的,所以无法设置这样的对象
那么我们可以尝试如下操作,首先对象在其未加入集群时会通过crush算法计算好自己即将映射到的osd以及对应的pg
ceph osd map pool_name obj_name命令可以看到该映射关系,那么我们可以认为只要知道对象的名字,那么它的映射关系实不会变化的。
依据以上过程,我们即可尝试这样的方案:
- 先从备份的磁盘上获取对应丢失对象的数据,通过
ceph-objectstore-tool的get-bytes参数来获取 - 从备份的磁盘双获取对应丢失对象的元数据,通过
ceph-objectstore-tool的get-attr _获取object_info_t属性,通过get-attr snapset获取快照属性 - 每获取完一个pg上所有的unfound对象之后,即将该pg上的unfound对象都delete掉
ceph pg 8.32 mark_unfound_lost delete - 使用
rados命令,重新put同一个对象名,并指定我们第一步获取到的对象文件 - 将备份好的对象的oi属性和ss属性在osd down掉的情况设置进去
以上步骤可以简化为如下脚本:
#!/bin/bash
tier_pool=$1
pg_list=`ceph health detail |grep unfound|grep has|awk '{print $2}'`
for i in ${pg_list}
do
# 按照PG编号,获取丢失对象列表
ceph pg $i list_missing|grep "rbd_dat"|sed 's/"/ /g'|awk -F: '{print $2}'|awk '{print $1}' > "$i".txt
#以PG为编号,从备份的磁盘挂载点获取丢失对象的数据
for j in `cat "$i".txt`
do
ceph-objectstore-tool --data-path /test_ceph0/ --type bluestore --pgid $i $j get-bytes "$i"/"$j".txt
ceph-objectstore-tool --data-path /test_ceph0/ --type bluestore --pgid $i $j get-attr _ > "$i"/"$j".oi
ceph-objectstore-tool --data-path /test_ceph0/ --type bluestore --pgid $i $j get-attr snapset > "$i"/"$j".ss
echo $i $j
done
if [ -e "$i".txt ];then #检测到按PG编号 存储对象列表的文件存在,则进行pg的delete操作
ceph pg $i mark_unfound_lost delete
else
echo "$i.txt is not exists,please check"
exit 1
fi
echo $i
for k in `cat "$i".txt` #将拷贝出来的对象文件,按照对象名重新put到资源池
do
rados -p $tier_pool put $k "$i"/"$k".txt;
echo $k
done
sleep 100 #处理完一个pg,睡眠100秒,让上一个PG数据重构一会
done
该尝试能够将对象最原本的数据恢复到集群异常前的最新状态,目前在使用rbd-nbd命令挂载的rbd块设备复现对象丢失的情况能够正常恢复。