机器学习数学基础——线性代数
线性代数
这一部分主要是对机器学习和深度学习用到的线性代数知识的总结,包括线性变换的物理意义与几何意义,直观的理解线性变换,以及特征值分解与奇异值分解的物理意义、几何意义,从信息的角度理解他们,最后,用线性代数实现PCA(从方差最大化角度)
线性变换
线性变换
变换是向量的的运动,变换让向量从一个地方(对应输入向量),运动到了另一个地方(对应输出向量)。
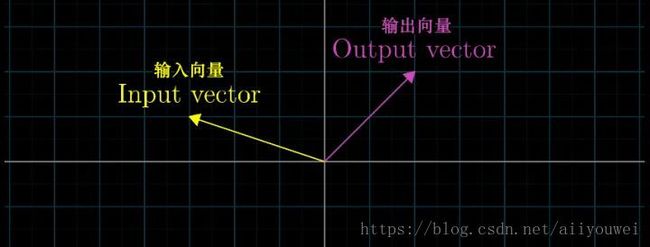
我们说将变换作用于某个空间,意思是将该变换应用于空间中的每一个向量。
空间中的向量可以用一些规则分布的点来表示。
下面是变换前的样子,

下面是变换后的样子。

变换后,空间中的点(即向量)运动到了其他的位置上。
二维空间变换中,等间距的平行网格可以更好地展示变换的性质。(下图是变换前后的等距线在同一坐标平面上的表示)

即线性变换是:
- 变换前后,所有的直线仍然是直线
- 变换前后,原点保持不变

换句话说,线性变换是原点不变,并使网络线保持平行且等距分布的变换。

线性变换的描述
以平面直接坐标系为例,假定我们有一个向量 v=[−1 2]。我们可以将它看成是 2 个基向量 i, j 的线性组合。线性组合的系数分别对应向量的 2 个分量。

在某个线性变换的作用下,i, j 以及 v 都运动到了新的位置。

线性变换前后网络线保持平行且等距分布,这一性质有一个重要的推论:线性变换后的 v 是变换后的 i 和 j 的线性组合,并且线性组合的系数和变换前一样(仍然是 -1 和 2)

即,线性变换前
i=[1 0],j =[0 1],则v =−1 [1 0]+2 [0 1]=[−1 2]
假定,经过某个线性变换后之后
i=[−1 2],j =[3 0],则v =−1 [1 −2]+2 [3 0]=[5 2]

所以,我们只要知道线性变换之后,i, j 的位置(坐标),就可以计算出任意一个向量经过同样的线性变换之后的位置(坐标)。

这意味着,对于一个线性变换,我们只需要跟踪基向量在变换前后的变化,就可以掌握整个空间(即全部向量)的变化。我们将线性变换后的基向量坐标按列组合起来,可以拼接成一个矩阵。线性变换的全部信息便都包含在这个矩阵当中了。

给定一个 2×2 的矩阵 [a c b d] 以及某个向量 [x y]。
矩阵对应着某个线性变换,它的 2 列 [a c] 和 [b d] 分别表示 2 个基向量 [1 0] 和 [0 1] 经过线性变换之后的坐标。

那么,向量 [x y] 经过该线性变换之后,其新坐标的计算方法如下:
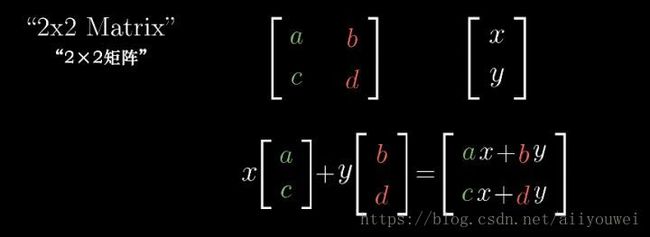
将向量 [x y] 与矩阵 A相乘得到向量 b,即 Ax⃗ =b⃗ 。所以,矩阵相乘的意义是对向量做变换,即向量的运动。

常见的线性变换
对于线性变换,我们只需要跟踪原来的基向量在线性变换后的位置(坐标),然后把它们按列拼成一个矩阵,这个矩阵就是相应的线性变换矩阵。
旋转变换:
原来的 2 个基向量 [1 0] 和 [0 1] ,逆时针旋转90 度之后,变成了 [0 1] 和 [−1 0] ,把它们拼成 一个矩阵.这便是逆时针旋转 90 度对应的线性变换矩阵。

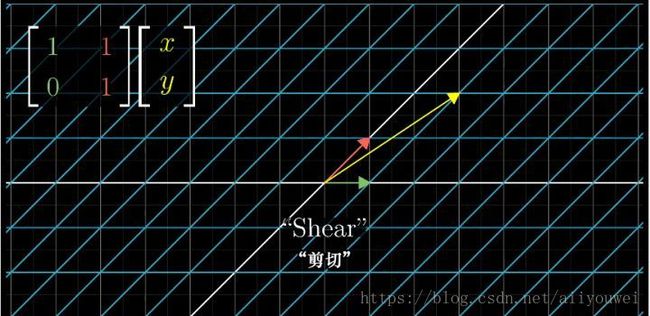
剪切变换:
投影变换:

常见的矩阵与变换
- 正交矩阵:将一组正交基旋转到另一组正交基,所以,对向量做旋转变换
- 实对称矩阵:对特征向量做且只做拉伸剪切变换
总之,线性变换是操纵空间的一种手段。线性变换保持原点不动,网格线平行且等距分布。只需要几个数字(变换后基向量的坐标)就可以清晰地描述一个线性变换。将变换后基向量的坐标按列拼接成一个矩阵。这个矩阵为我们提供了一种描述线性变换的语言。线性变换作用于一个向量,对应于用线性变换矩阵左乘该向量。
特征值分解
信息角度—-主成分分析
- 数据离散性越大,代表数据在所投影的维度上具有越高的区分度,这个区分度就是信息量
- 所以选取正确的坐标轴,然后根据各个维度上的数据方差大小,决定保留哪些维度的数据,这样的做法就是主成分分析的核心思想。
- 特征值对应的特征向量就是理想中想取得正确的坐标轴,而特征值就等于数据在旋转之后的坐标上对应维度上的方差。
- 在数据挖掘中,就会直接用特征值来描述对应特征向量方向上包含的信息量,而某一特征值除以所有特征值的和的值就为:该特征向量的方差贡献率(方差贡献率代表了该维度下蕴含的信息量的比例)。
奇异值分解SVD
- 正交矩阵 正交矩阵的行(列)向量都是两两正交的单位向量,正交矩阵对应的变换为正交变换,它有两种表现:旋转和反射。正交矩阵将标准正交基映射为标准正交基。
EVD
- 比如将x用A的所有特征向量表示为
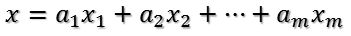
- 通过第一个变换就可以把x表示为[a1 a2 … am]’:
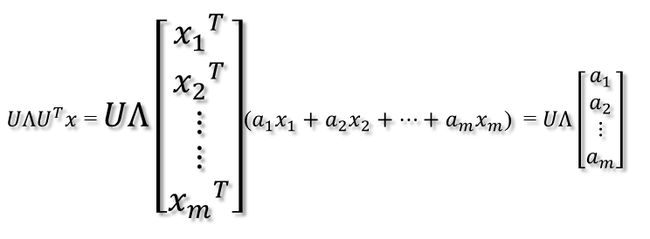
- 在新的坐标系表示下,由中间那个对角矩阵对新的向量坐标换,其结果就是将向量往各个轴方向拉伸或压缩
- 最后一个变换就是U对拉伸或压缩后的向量做变换,由于U和U’是互为逆矩阵,所以U变换是U’变换的逆变换。
- 比如将x用A的所有特征向量表示为
3.SVD
- A=UDV’,U和V是两组正交单位向量,D是对角阵,表示奇异值,它表示我们找到了U 和V这样两组基,A矩阵的作用是将一个向量从V这组正交基向量的空间旋转到U这组正交基向量空间,并对每个方向进行了一定的缩放,缩放因子就是各个奇异值。如果V维度比U大,则表示还进行了投影。
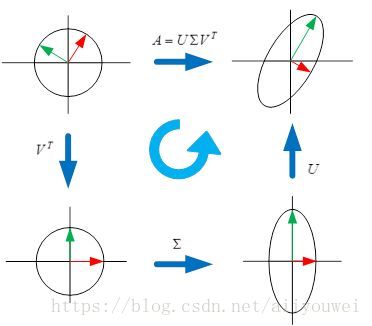
- 特征值分解和奇异值分解都是给一个矩阵(线性变换)找一组特殊的基,特征值分解找到了特征向量这组基,在这组基下该线性变换只有缩放效果。而奇异值分解则是找到另一组基,这组基下线性变换的旋转、缩放、投影三种功能独立地展示出来了。
- 信息角度:奇异值往往对应着矩阵中隐含的重要信息,且重要性和奇异值大小相关。每个矩阵都可以表示为一系列秩为1的”小矩阵”之和,奇异值衡量这些小矩阵的对于矩阵的权重。
物理意义
- SVD提供了一种非常便捷的矩阵分解方式,能够发现数据中十分有意思的潜在模式。
- 主成分分析就是对数据的协方差矩阵进行了类似的分解(特征值分解),但这种分解只适用于对称的矩阵,而 SVD 则是对任意大小和形状的矩阵都成立。

- 我们可以看出矩阵的秩是3,也就是主要信息都包含在三个列向量里面
- 我们对矩阵进行奇异值分解以后,得到奇异值分别是σ1 = 14.72 σ2 = 5.22 σ3 = 3.31,矩阵A就可以表示成 A=u1σ1v1T+u2σ2v2T+u3σ3v3Tvi A = u 1 σ 1 v 1 T + u 2 σ 2 v 2 T + u 3 σ 3 v 3 T v i 具有15个元素,ui具有25个元素,σi对应不同的奇异值。如上图所示,我们就可以用123个元素来表示具有375个元素的图像数据了。
4.实例:
如下所示,将图像转换为矩阵输入,分别对rgb三个通道求SVD再合并,效果如下1/369

2/369

3/369

5/369

7/369

369/369

范数
范数包括向量范数和矩阵范数,向量范数表征向量空间中向量的大小,矩阵范数表征矩阵引起变化的大小。
对应向量范数,向量空间中的向量都是有大小的,这个大小如何度量,就是用范数来度量的,不同的范数都可以来度量这个大小,就好比米和尺都可以来度量远近一样;
对于矩阵范数,学过线性代数,我们知道,通过运算AX=B,可以将向量X变化为B,矩阵范数就是来度量这个变化大小的。
常见的范数:
向量范数
1-范数:
,即向量元素绝对值之和
2-范数:
,Euclid范数(欧几里得范数,常用计算向量长度),即向量元素绝对值的平方和再开方
-范数:,即所有向量元素绝对值中的最大值
-范数:
,即所有向量元素绝对值中的最小值
p-范数:
,即向量元素绝对值的p次方和的1/p次幂矩阵范数
1-范数:
, 列和范数,即所有矩阵列向量绝对值之和的最大值2-范数:,为的最大特征值。
-范数:
,行和范数,即所有矩阵行向量绝对值之和的最大值
F-范数:
,Frobenius范数,即矩阵元素绝对值的平方和再开平方
从方差最大化角度理解PCA
PCA常见的解释包括:方差最大化以及平方误差最小化,而方差最大化就用到了线性代数的相关知识。
在信号分析理论中,我们知道,方差较大的信息是我们需要的信息,而方差较小的信息则是由噪声引起的,我们希望使信噪比越大越好,所以,我们可以舍去噪声引起的信息。
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。PCA即寻找一个n维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0(因为我们已经预先对数据进行标准化,即减去均值以及方差归一化),而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
协方差矩阵:设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设C=XX’/m, 则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
优化目标变成了寻找一个矩阵P,满足PCP’是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
易知,P是C的前k个特征向量组成的矩阵,Y=PX则为降维后矩阵。
实例
实例
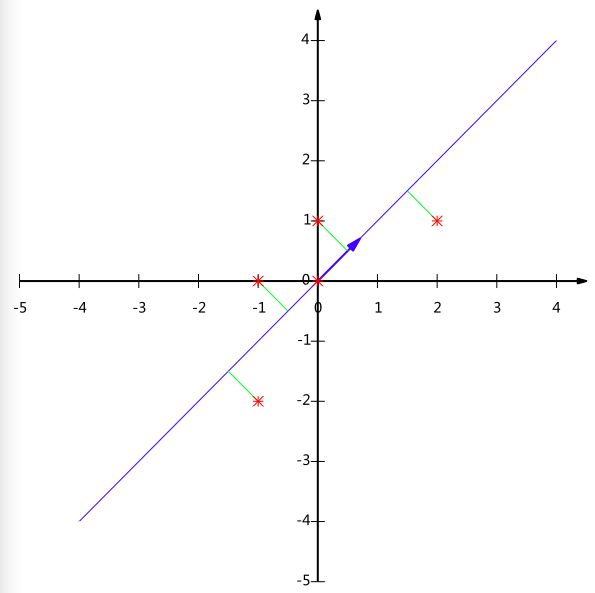
- 假设我们的数据有两个随机变量,分别各取五个值,我们用PCA方法将这组二维数据其降到一维。
(−1−2−10002101) ( − 1 − 1 0 2 0 − 2 0 0 1 1 )
因为这个矩阵的每行已经是零均值,这里我们直接求协方差矩阵:
C=15(−1−2−10002101)⎛⎝⎜⎜⎜⎜⎜−1−1020−20011⎞⎠⎟⎟⎟⎟⎟=(65454565) C = 1 5 ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) ( − 1 − 2 − 1 0 0 0 2 1 0 1 ) = ( 6 5 4 5 4 5 6 5 )
然后求其特征值和特征向量,求解后特征值为:λ1=2,λ2=2/5
其对应的特征向量分别是:
因此我们的矩阵P是:
最后我们用P的第一行乘以数据矩阵,就得到了降维后的表示:
Y=(1/2‾√1/2‾√)(−1−2−10002101)=(−3/2‾√−1/2‾√03/2‾√−1/2‾√) Y = ( 1 / 2 1 / 2 ) ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) = ( − 3 / 2 − 1 / 2 0 3 / 2 − 1 / 2 )
降维投影结果如下图:
参考资料
- http://m.blog.csdn.net/fuming2021118535/article/details/51339881
- https://zhuanlan.zhihu.com/p/31724181
- http://m.blog.csdn.net/zhongkejingwang/article/details/43053513
- https://www.zhihu.com/question/19666954/answer/54788626
- https://www.zhihu.com/question/22237507
- http://blog.csdn.net/shijing_0214/article/details/51757564
- http://blog.codinglabs.org/articles/pca-tutorial.html