【CenterMask】《CenterMask:Single Shot Instance segmentation with Point Representation》

CVPR-2020
和 《CenterMask:Real-Time Anchor-Free Instance Segmentation》重名了,两者同为 CVPR-2020,巧了还同时做的 Instance Segmentation
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 4.1 Local Shape Prediction
- 4.2 Global Saliency Generation
- 4.3 Mask Assembly
- 4.4 Overall pipeline of CenterMask
- 5 Experiments
- 5.1 Datasets
- 5.2 Ablation Study
- 5.3 Comparison with state-of-the-art
- 5.4 CenterMask on FCOS Detector
- 6 Conclusion(own)
1 Background and Motivation
实例分割(instance segmentation)是一个基础且具有挑战性的计算机视觉任务,它需要定位、分类、分割出每个实例!兼具目标检测(object detection)和语义分割(semantic segmentation)视觉任务的特点!
目前 SOTA 的实例分割方法大多是基于 two-stage 的目标检测器,虽然 one-stage 目标检测器正在引领潮流(特别是 anchor-free 的方法),但只有少数文献聚焦于 one-stage 的实例分割。
本文,作者旨在设计一个简单的、 one-stage 的、anchor-free 的实例分割算法!
实例分割比目标检测难得多(边界的定义,一个是奇形怪状,一个是矩形框),对于 one-stage 的实例分割来说,主要存在如下两个挑战:
- Object instances differentiation:如何有效的区分实例,特别是当他们属于同一类别时(抱团取暖的时候,类似于细胞的粘黏情况)
- Pixel-wise feature alignment:如何 preserve 像素级的定位信息,从而进行精确度的边界定位—— pixel misalignment problem,eg,mask rcnn 是采用 RoIAlign 来解决这个问题的
为了解决上述两个问题,作者设计两条并行的分支来预测 mask
- Local Shape prediction(coarse、instance-aware):在 local 区域预测一个大致的 mask,即使重叠,也可以区分不同的分割
- Global Saliency generation(precise、instance-unaware):segments the whole image in a pixel-to-pixel manner,实现 pixel-wise alignment.
2 Related Work
- Two-stage Instance Segmentation:detect-then-segment,先检测,再分割!eg:Mask RCNN、PANet
- One-stage Instance Segmentation:
- global-area-based,eg:InstanceFCN、YOLACT,优点,maintain the pixel-to-pixel alignment which makes masks precise, 缺点 but performs worse when objects overlap
- local-area-based,例如 PolarMask、TensorMask,能较好的处理 overlap 情况,但 mask 的定位比较粗糙
作者采用结合 one-stage 实例分割方法中 global-area-based 和 local-area-based 方法的优点,设计提出了 CenterMask,既保证了 pixel-to-pixel alignment,又保证了能有效的分割实例(特别是重叠的情况)
3 Advantages / Contributions
- 提出了 one-stage、anchor-free 的 CenterMask 实例分割方法,在 COCO 数据集上达到了 34.5 mask AP,12.3 fps,有一定的通用性,很容易嵌入到 one-stage 的目标检测方法中去(实现实例分割),eg:FCOS
- 提出的 Local Shape representation 模块,能在重叠情况下有效的分割实例
- 提出的 Global Saliency Map 模块,能 realize pixel-wise feature alignment naturally
4 Method
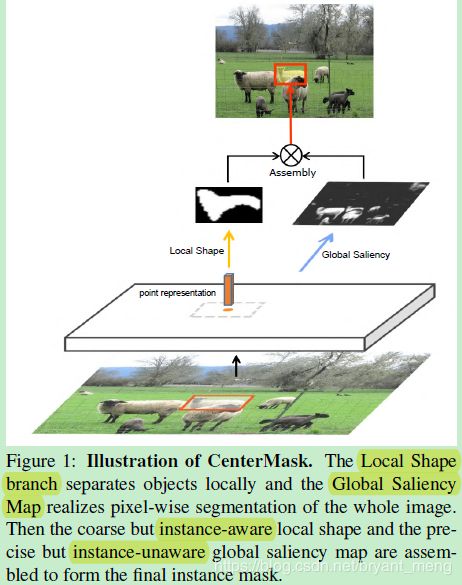
在 Center 点被预测出来的基础上,
Local Shape representation + Global Saliency Map = Mask
4.1 Local Shape Prediction
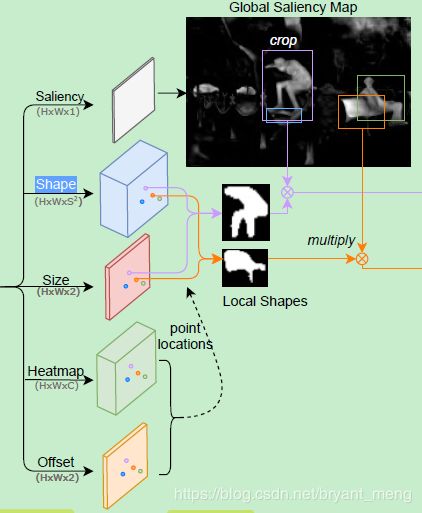
作者想用中心点对应的 representation 来表示 instance,但是 representation 是固定的(如下图的 1 × 1 × S 2 1×1×S^2 1×1×S2),不好表示各种大小的 instance,因此作者采用了如下方法,新增了一条预测形状的分支,来 resize 固定的representation
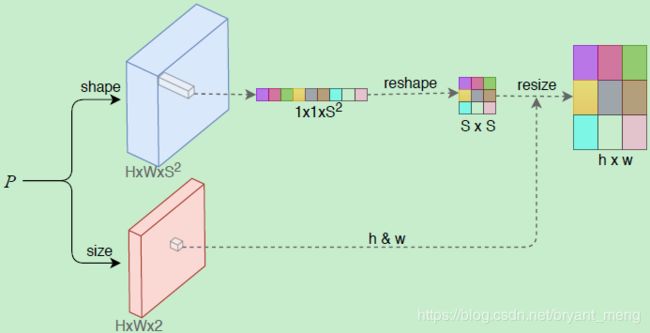

- P P P 是来由 backbone 提取出来的 feature map
- F s h a p e ∈ R H × W × S 2 F_{shape} \in \mathbb{R}^{H × W ×S^2} Fshape∈RH×W×S2,Shape head:对于每个像素点 F s h a p e ( x , y ) F_{shape}(x,y) Fshape(x,y)——中心点,其负责预测的实例形状用 1 × 1 × S 2 1×1×S^2 1×1×S2 的向量来表示,然后 reshape 成 S × S S×S S×S 大小,最后根据 F s i z e F_{size} Fsize 预测出的 h h h 和 w w w resize 成 h × w h×w h×w 的形状
- F s i z e ∈ R H × W × 2 F_{size} \in \mathbb{R}^{H × W ×2} Fsize∈RH×W×2,Size head:对于每个像素点 F s i z e ( x , y ) F_{size}(x,y) Fsize(x,y),其负责预测的实例大小为 h h h 和 w w w
对应到全局图的话如下所示
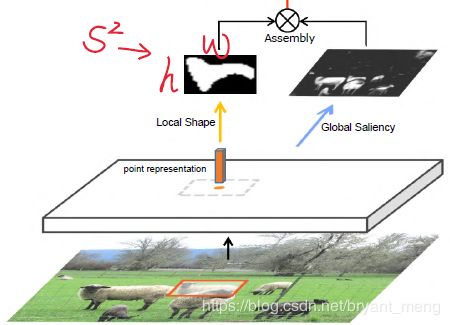
S S S 在实验中被设定为了 32
4.2 Global Saliency Generation
Local Shape Prediction 虽然为每个 instance 预测出了一个局部区域,有利于区分不同的 instance,但由于有 reshape 操作(losses spatial details),定位的不是很精确,只能实现 coarse 分割!
为了实现 pixel level feature alignment,作者模仿 FCN 中的方法(pixel-wise predictions on the whole image),设计了 Global Saliency Generation 模块,相比于 Mask RCNN 的 RoIAlign 更加的简洁
具体如下图红色框框所示,用 sigmoid 预测出 saliency map,可以是 class-agnostic(前景背景二分类,用 sigmoid 激活的话,通道数就是1,如果 softmax 激活的话通道数就是2),也可以是 class-specific 的(对每一类进行 binary mask 预测)
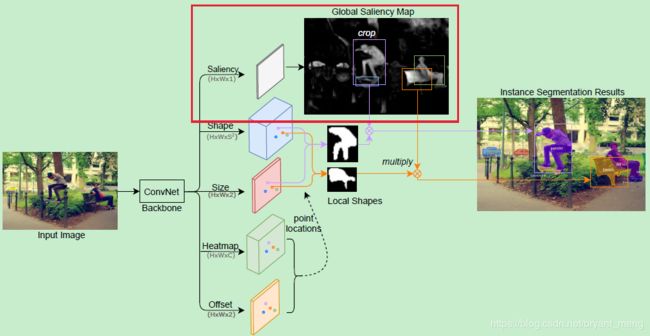

achieves pixelwise alignment with the input image.
4.3 Mask Assembly
Local Shape Prediction 模块的输出为 L k ∈ R h × w L_k \in \mathbb{R}^{h×w} Lk∈Rh×w,Global Saliency Generation 模块把目标 crop 出来后的输出为 G k ∈ R h × w G_k \in \mathbb{R}^{h×w} Gk∈Rh×w,两者经过 sigmoid 激活后,按照如下的方式组合在一起,形成最终的 mask
M k = σ ( L k ) ⊙ σ ( G k ) M_k = \sigma(L_k) \odot \sigma(G_k) Mk=σ(Lk)⊙σ(Gk)
其中 ⊙ \odot ⊙ 表示 Hadamard product(哈达玛积),就是 element-wise multiply(对应位置相乘),这给它包装的,山鸡变凤凰了,都不认识了,哈哈哈
Local Shape Prediction 模块和 Global Saliency Generation 模块合体后预测出的 mask 的 Loss 如下
L m a s k = 1 N ∑ k = 1 N B c e ( M k , T k ) L_{mask} = \frac{1}{N}\sum_{k=1}^NBce(M_k,T_k) Lmask=N1k=1∑NBce(Mk,Tk)
其中 T k T_k Tk 是对应的 GT,Bce 是 Binary Cross Entropy 的缩写(参 Binary_Cross_Entropy,logistic regression 的标配)
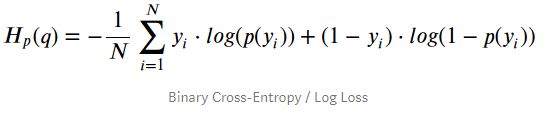

4.4 Overall pipeline of CenterMask

一共五个 head(天上九头鸟,地上湖北佬,奇怪了,这个九头鸟——怎么才 5 个头,没长大吗)

backbone 出来后,第一个 head 就是 Global Saliency Generation 模块,二三 head 就是 Local Shape Prediction 模块
第四个 head 是热力图分支,通道 C C C 表示类别数,用来预测每个实例的中心点和类别!中心点是通过搜索 heatmap 中的每个 window 中的 local maximum 来确定的(8领域中如果响应最高,就为 center point,实现的时候用 3 x 3 max pooling operation 就可以了)。
第五个 head 就是来精修中心点坐标的(recover the discretization error caused by the output stride)
损失函数由如下四个部分组成
1) center point loss
第四个头,预测中心点的损失(同 CenterNet),公式如下,是基于 focal loss 的修改版(a pixel-wise logistic regression modified by the focal loss)
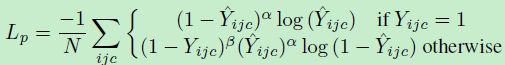
其中
- Y ^ i j c \hat{Y}_{ijc} Y^ijc 表示是第 c c c 类 heatmap 中,位置 ( i , j ) (i,j) (i,j) 处预测出来的 score
- Y i j c Y_{ijc} Yijc 是对应的 GT
- N N N 是图片中的中心点个数
- α \alpha α、 β \beta β 是超参数
仔细推导,就是把 logistic regression Loss 中的 cross entopy 换成了 focal loss!仅仅多了一个超参数 β \beta β 而已!(y = 1 的时候,在 focal 代入 y 和 y’,y 不等于1的时候,在 focal loss 中代入 1-y 和 1-y’)
公式中 Y i j c Y_{ijc} Yijc 的定义同 Hourglass Network (参考 【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》,也即标签采用的是中心点的高斯分布,而不是仅有一个像素 ,Hourglass 网络中采用的是 MSE Loss,这里是作者用的是改进的 Focal Loss)
GT 的高斯分布表达如下
![]()
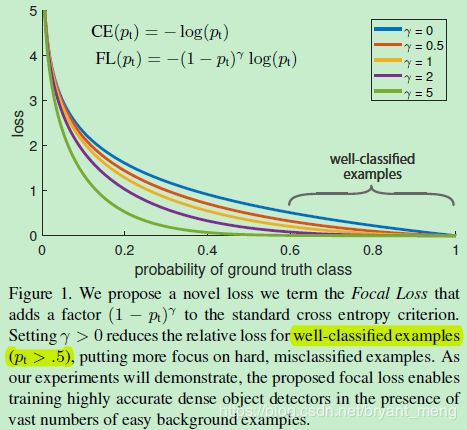
Focal Loss 如下所示
关于 Focal Loss 的解析可以参考 【Focal Loss】《Focal Loss for Dense Object Detection》
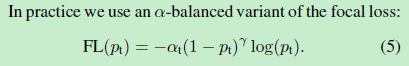
2)offset loss
第五个头的损失,同 CenterNet,为 L1 Loss,来 recover the discretization error caused by the output stride
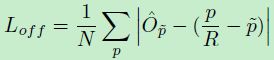
其中
- O ^ \hat{O} O^ 为预测的 offset
- p p p 是 GT
- R R R 是 output stride,也就是 heatmap 大小与原图大小的比例关系
- 特征图的像素点和原图的像素点映射关系为
p ~ = ⌊ p R ⌋ \widetilde{p} = \left \lfloor \frac{p}{R} \right \rfloor p =⌊Rp⌋
从下面这个图可以看出, H × W H × W H×W(白色部分)和原图大小(Global Saliency Map 应该是放大到了原图大小)还是有差距的(CenterNet 和 Hourglass Network 中比例差距为 4 倍,这里如果同 Hourglass Network 的话,应该也是 4倍的差距)
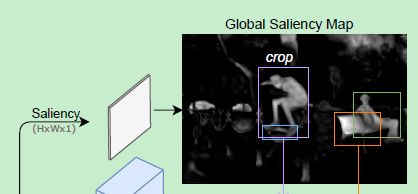
比如中心点在原图(15,15)处,R=4,那么精确地映射到特征图上对应着应该是 (3.75,3.75)处,但特征图最小的分辨率是 1 像素嘛,所以预测的中心点最准的地方只能为(3,3)!(3,3)还原到原始图处为(12,12),与(15,15)有了 3 个像素的偏差嘛,为了弥补这个偏差,我们需要在特征图(3,3)的基础上,学出一个(0.75,0.75)的偏置,这样的话恢复到原始图片大小,就能逼近(15,15)了
3)size loss
第三个头的损失,同 CenterNet,
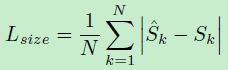
其中
- S ^ k = ( h ^ , w ^ ) \hat{S}_k = (\hat{h},\hat{w}) S^k=(h^,w^) 表示预测出来的 instance 边界框大小
- S k = ( h , w ) {S}_k = (h,w) Sk=(h,w) 是 GT object size
4)mask loss
前面已经介绍过,一二三头的合体 loss
L m a s k = 1 N ∑ k = 1 N B c e ( M k , T k ) L_{mask} = \frac{1}{N}\sum_{k=1}^NBce(M_k,T_k) Lmask=N1k=1∑NBce(Mk,Tk)
其中
- M k M_k Mk 是预测出的 mask
- T k T_k Tk 是对应的 GT,
- Bce 是 Binary Cross Entropy
整体 Loss 表示如下
![]()
其中 λ p , λ o f f , λ s i z e , λ m a s k \lambda_p,\lambda_{off},\lambda_{size},\lambda_{mask} λp,λoff,λsize,λmask 是对应的系数,实验中分别被设置为了 1,1,0.1,1
5 Experiments
输入大小固定为 512 × 512 512×512 512×512,所有模型 trained from scratch
测试的时候,把热力图中 8 邻域响应最高的点定为中心点,输出 top-100 的 center point,binary 阈值设定为了 0.4
5.1 Datasets
- MS COCO instance segmentation
- trained on the 115k trainval35k
- tested on the 5k minival(消融实验)
- Final results are evaluated on 20k test-dev(与 SOTA 比较)
- LVIS
5.2 Ablation Study
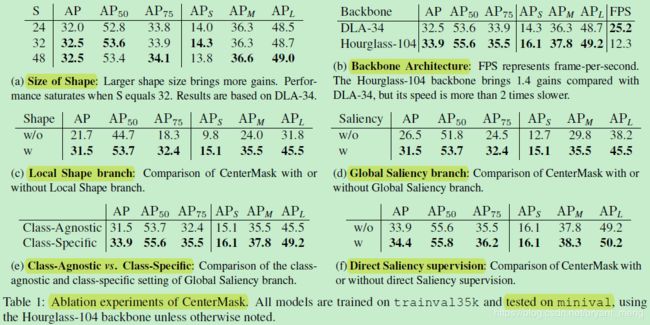
1)Shape size Selection
第二个头
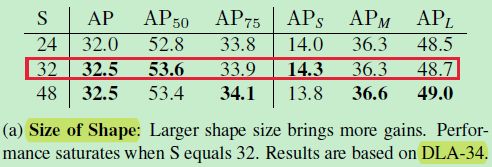
S S S 增加到 32 后,没有明显的增长了,采用的是 DLA-34 主干网络(CenterNet 中有用到)!
2)Backbone Architecture
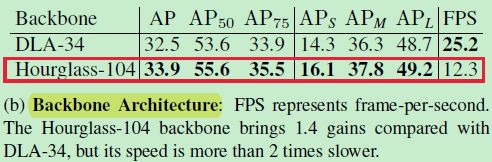
Hourglass 大网络精度会更高,但是相应的也更慢
3)Local Shape branch

仅有 Local Shape branch 的时候,结果为 26.5,配合 Global Saliency branch 结果为 31.5
应该是去掉了第一个头
仅有 Local Shape branch 时,结果展示如下


结果还是比较粗糙的(边界),但能很清晰的分割出不同的 instance
4)Global Saliency branch

仅有 Global Saliency branch 的时候,结果为 21.7,配合 Local Shape branch 结果为 31.5
说明这个 Local Shape branch 模块设计的很到位
仅有 Global Saliency branch 的时候,应该只是去掉了第二个头,而不是二三两个头
仅有 Global Saliency branch 的时候,结果如下

可以看出,在没有 overlap 的情况下,效果还是挺好的
下表是比较 Global Saliency branch 中 class-agnostic 和 class-specific 的
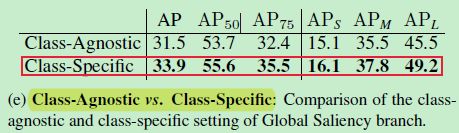
可以看出 class-specific 更有利于 instance segmentation
Global Saliency 分支采用 class-specific 方式以后, a binary cross-entropy loss is added to supervise the branch
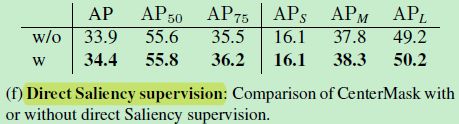
论文中设计的 Local 模块中与 size 的损失,设计的 Global 模块中没有监督损失,Local 和 Global 的合体有 mask Loss,这里的意思应该是对 class-specific 的 Global 模块,每个 channel(也即每一类)进行空间维度的 binary cross-entropy,相当于在 Global 模块也引入了监督信号!
发现加入这个监督信号后效果更好!
5)Combination of Local Shape and Global Saliency

第一列仅有 Local Shape branch,可以看出 separates different instances well,但是 mask 比较粗糙,
第二列仅有 Global Saliency branch,precise segmentation but fails in the overlapping
第三列, 双剑合璧,傲世群雄
5.3 Comparison with state-of-the-art
在 test-dev set 上比较
without pre-trained weights
inference without any NMS
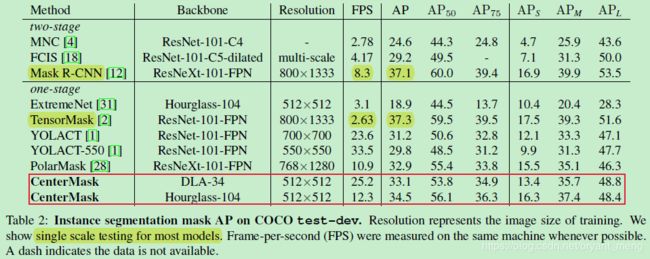
作者分析 TensorMask 比较慢的原因是 complicated and time-consuming feature align operations

注意 a 列中,Mask R-CNN 的头,作者分析,可能 caused by feature pooling
d 列的 PolarMask 骑的怕是个熊吧,哈哈哈
5.4 CenterMask on FCOS Detector
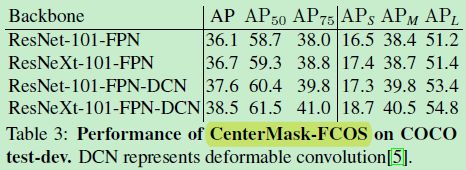
比表 2 中同一backbone 的 PolarMask 猛,说明作者设计的两个模块还是有一定的泛化性能的

比 Mask R-CNN 猛
6 Conclusion(own)
- 补下 CenterNet 论文
- 补下 FCOS 论文
- Focal Loss 的改进版本要留意一下
- 学习下基于一个点表示 shape 1 × 1 × S 2 1×1×S^2 1×1×S2