千亿级HttpDNS服务是怎样炼成的
"鹅厂网事"由深圳市腾讯计算机系统有限公司技术工程事业群网络平台部运营,我们希望与业界各位志同道合的伙伴交流切磋最新的网络、服务器行业动态信息,同时分享腾讯在网络与服务器领域,规划、运营、研发、服务等层面的实战干货,期待与您的共同成长。
网络平台部以构建敏捷、弹性、低成本的业界领先海量互联网云计算服务平台,为支撑腾讯公司业务持续发展,为业务建立竞争优势、构建行业健康生态而持续贡献价值!
【前言】
话说距离鹅厂的HttpDNS服务(【鹅厂网事】全局精确流量调度新思路-HttpDNS服务详解)推出已经快4年时间了。在这一千多天里面,HttpDNS服务不仅成了cloudflare、google等各大云厂商的标配服务,而且还在IETF成立了相应的工作组,RFC草案(DNS over Https)已经出到第14版了,离正式成为互联网标准越来越近。而腾讯作为首家提供HttpDNS服务的云服务商,日解析量在数月前就超过了一千亿次,每秒峰值并发请求达到了百万级别,为上千家企业的域名解析保驾护航。到底是什么支撑着这海量的HttpDNS服务?本文将为你一一道来。
一、 快、准、稳,无缝扩容的高可用架构
腾讯HttpDNS服务作为亿级用户访问互联网的第一跳,优质的网络质量至关重要,故在HttpDNS服务的接入层,采取了对外BGP Anycast+对内OSPF的架构。当前在国内华南、华东、华北,以及东南亚、北美部署了多个节点,不仅与国内及海外数十余家运营商建立了互联来缩短用户访问的网络路径,而且还对路由进行精细化调优,保证用户访问延迟降到最低。

BGP Anycast的网络架构不仅实现了用户访问的低延迟,同时还保证了HttpDNS服务的高可用。该架构不仅实现了在单一地区节点全部发生故障的时候将用户的访问流量迁移到其余服务正常的节点,而且能精细化到的单一出口网络发生故障时的流量迁移。比如华南节点的A运营商出口发生了故障,而其余的B、C、D运营商并没有发生故障,那么通过腾讯的公网流量调度平台即可单独将华南节点的A运营商出口流量迁移到其余节点,而其B、C、D运营商的流量继续使用华南节点覆盖,尽力保证在单运营商出口发生故障时对用户访问的影响降到最低,整个切换过程在分钟级别的耗时内即可完成。而对于OSPF集群内的单机故障,则实现了秒级切换。至于平行扩容,更是撒撒水啦,OSPF域里面加机器不就完了么?
二、 容量不够,机器来凑?
要支持海量HttpDNS访问自然很简单的啦,一台机器5w并发,20台机器就100w并发,40台机器就200w并发,哪里容量不够扩哪里,so easy!全文完,谢谢大家观看!
===========================

不好意思走错片场了,开个玩笑~问题真那么简单就好了,走OSPF集群扩容的话,且不说IDC机房里机位资源的问题。像HttpDNS服务这种每两三个月请求量就翻一倍的服务,有能跑5w qps的机器来扩容自然美滋滋,但流量上来了能跑3w qps的机器也得顶上啊。5w qps的服务器和3w qps的服务器在同一个OSPF域里面权重怎么搞,难道还要去算ECMP路径下的交换机端口不成?

为了解决最大化利用不同配置的服务器资源和同IP不同业务分离部署的问题,我们需要一个高性能的4层负载均衡器。但LVS的那点性能根本就不够用,而在2014年这个时间点,业界基于DPDK的4层负载均衡器又还没诞生。万(tan)般(xiao)无(feng)奈(sheng)之下,只能自己动手,撸了个转发性能千把万pps、支持按后端实例处理能力来设置权重分发流量的DPDK LD,解决了HttpDNS和public DNS服务分离部署以及最大化利用不同处理能力等实例来满足突发流量等快速扩容问题。这下子问题总解决了吧?
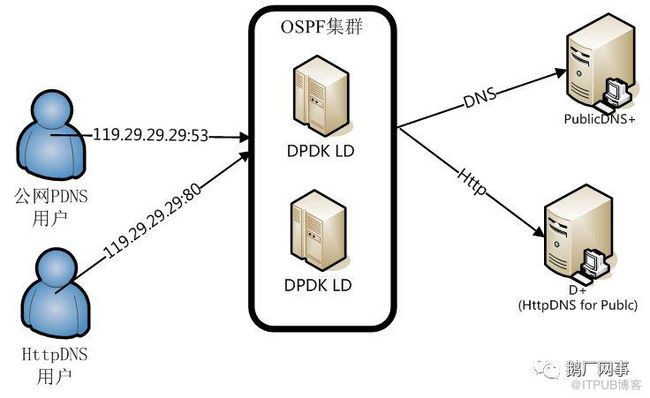
少年你太年轻了!上了DPDK LD只是解决了可以在资源池里面捡非标设备来扩容而已,但是后端的服务器处理能力并没有提升啊!你这100w的短链接并发请求用单机5w并发的机器去抗还是要20台服务器的算力啊!200w并发就是40台服务器啊!你搞了个4层的负载均衡在前面还多占了俩机器+俩机架啊! 问题哪里解决了啊摔!

在一个寒风凛冽的早上,我拿着一份5块钱的沙县小吃在三和人才市场的大门下停住了脚步,陷入了深深的沉思:到底要怎么样才能提升HttpDNS服务的单机处理能力呢?

三、 提升性能,如何是好?
(1)缓存,又见缓存
从本质上来将,HttpDNS服务就是一个通过http实现的递归域名解析服务,只要缓存里面没有对应的解析记录,那么就必须根据DNS协议进行递归查询。而一旦涉及到域名递归解析到话,这个耗时就没谱了,什么SRTT选路啦、公网递归质量啦,要是让HttpDNS直接去递归的话,一条短链接的停等时间分分钟教你做人。
所以要提升HttpDNS的处理能力,第一步就是要提升缓存命中率,让绝大部分的用户请求都直接命中缓存,减少httpdns递归处理耗时。所以HttpDNS的架构就成了这样:

● 当用户的请求通过BGP Anycast网络来到了DPDK LD上之后,DPDK LD通过tunnel将请求转发至一级缓存;
● 一级缓存收到请求后先查找是否有本地缓存,没有的话就将请求按照RR级别的哈希,转发到二级缓存;
● 二级缓存收到请求后也是先找本地是否有缓存,没有的话就直接将请求转发到后端递归节点。
● 通过一级缓存by RR级别的递归哈希+二级全局缓存的架构设计,HttpDNS服务达到了将近90%的缓存命中率。
● 而在没有命中缓存的10%请求中,除去首次触发递归的部分以外,其余请求均通过75% TTL异步触发递归机制在用户无感知下完成更新。
● 最终实现了在遵循权威DNS TTL设置的情况下,将绝大部分HttpDNS的请求直接通过一次查找就获取到最终结果。
(2)百万级的http短链接之Linux协议栈篇
然而缓存命中率的提高只是减少了域名递归解析对处理性能的影响,一次查找就命中缓存是不用卡递归了,但这百万级别http短链接并发请求怎么搞?堆机器是不可能的,这辈子都不可能堆机器。所以提升HttpDNS处理性能的第二步,就是要提升一级缓存每个实例的http短链接处理能力。
不就是C10k嘛,有啥难的,先来个多进程并发链接模型:

不同进程之间互不影响,不存在锁的开销,每个子进程从接收请求、处理、最后发送请求实现一条龙服务。再把什么亲和性啊、连接重用啊、队列啥的优化全部满上,8w+ qps达成!

美你个大头鬼啊!几百万并发短链接你单机跑个8w+ qps,你自己算算要多少台服务器?

(3)DPDK over TCP
既然传统的Linux协议栈要再进一步提升http短链接的性能空间不大,要不就换个基于DPDK实现的TCP协议栈试试?理想是美好的,现实是骨感的。GSLB团队关注过多个开源的DPDK项目(seastar、mTCP等),并基于Seastar框架开发了新架构的HttpDNS。但从实验室环境验证完毕灰度到现网后,问题不断,技术研究一度停滞,直到腾讯云DNSPod团队开发的F-Stack项目进入了我们的视野。
F-Stack(https://github.com/F-Stack/f-stack)是基于DPDK+FreeBSD协议栈的全用户态的高性能run-to-completion模型网络接入开发包,提供了友好的网络API接口,上层应用只需要进行简单的调整改造,即可利用DPDK大幅提升网络性能。
GSLB团队基于F-Stack对HttpDNS服务进行了迁移改造,通过DPDK按每进程绑定一个网卡队列,DPDK从网卡收包后input给freebsd的网络协议栈;应用程序通过创建socket,绑定所配置的IP及端口并监听之,基于epoll从FreeBSD的协议栈收取对应的数据包,处理完成后再write到FreeBSD的协议栈,由其output给DPDK进行回包。最终实现了在24核心48线程的CPU+128G内存+10G 网卡的情况下,将HttpDNS的单机性能提升到了40w qps,比起传统的linux协议栈版本性能提升了500%!

然而即使单机性能有了大幅的提升,但这个框架还远没达到极限。通过观察发现,在极限负载下,HttpDNS的服务器上有部分CPU没有被充分利用起来。经过排查分析发现是由于x540网卡只有16个网卡队列,所以按上述框架就只能起16个处理进程,导致了CPU的出现了空闲。 针对这种情况,GSLB团队进行了架构的优化,采用pipeline与run-to-completion结合的模式:一个进程收包,通过ring进行分发,多个处理进程从对应ring取包并处理、最后通过对应的网卡队列将应答包发送出去,架构如下:

通过调整,在同等硬件配置下,HttpDNS的单机服务能力提升到了89w qps!从此公主和王子就过上了幸福美满的生活,全文完。
===========================

然后现实又一次给我们打脸了,面对现网疯涨的流量,F-stack HttpDNS在没有达到极限性能的情况下就出现了丢包。问题到底出在哪里?通过分析,我们发现了生产环境和测试环境流量的差别:
1) 生产环境峰值瞬时并发连接数是在测试环境的1000倍;
2) 生产环境中有大量因各种原因的不能完成三次握手的无效请求,大量消耗了CPU的处理资源;
3) 在面对真实的用户请求时,F-stack HttpDNS的分包算法存在不均匀的情况,导致会出现部分CPU跑满,而其他CPU又比较空闲的情况。
为了解决这些问题,GSLB团队采取了一系列的改进措施:
1) 因为F-Stack的epoll是kqueue模拟的,而kqueue通知accept事件时,有可能为多个FD的连接事件,因此需修改为循环accept,获取产生此次通知事件的所有FD。
2) 增大配置参数kern.ncallout的值,减少callout_proccess函数的回调次数。
3) 优化dispatch分包算法,更均匀各个处理进程的业务处理。
而正当我们为解决了生产环境下在高负载时丢包的问题松了一口气时,一场突如其来的瞬时流量暴涨又把我们推到了风口浪尖上。由于客户的业务突发,HttpDNS服务器单机在5秒之内收到了将近600w的syn包,进而触发了服务瞬间不可用,导致该服务器从集群中被剔除。而由于该服务器被剔除之后的流量又被分摊到了集群内的其他HttpDNS服务器,导致了其他服务器也轮番被剔除,造成整个集群在访问量突发期间不停地被剔除、增加。最终只能依靠人为干预流量分配,才解决了问题。
从此次事件中可以看出,HttpDNS暴露了两个设计上的问题:
1) 心跳包(监控包)与业务包采用相同的通道:
当业务包处理能力不足而阻塞时会导致心跳包处理超时,而引起DPDK LD的误判。此时虽然部分请求可能会出现短暂超时,但服务器本身并没有出现故障,总体服务还是可用的。此时将服务器剔除出集群并不是一个正确的做法。
2) 系统过载保护设置不合理:
系统的过载保护是在应用层通过控制用户并发连接数(FD)来实现,但此次事件中TCP三次握手的成功率低于正常情况,并发连接数未到达阀值,过载保护未能生效。
针对这两个问题,我们做出了如下优化:
1) 心跳包与业务包通道的隔离。
在dispatch进程与业务处理进程间设计只存储心跳包的ring, 用于进行心跳包的传输。
2) 实现更精确的过载保护。
从HttpDNS的架构中可以看出,当业务进程处理性能不足,引起业务包阻塞,那么dispatch进程向业务包ring push数据时会失败,据此我们做了以下优化:
i. 发生此种情况时进行高负载告警。
ii. 高负载情况下,优先完成已请求包的业务处理,控制新进包的处理:
a) 若dispatch向某处理进程对应的ring push一个数据包失败,进行计数为5,此后dispatch将后续接收到的需分发至此进程的sync包drop掉,计数值减一,直至计数值<=0,才重新分发此进程的sync包。
b) 若某进程的计数值大于某个阀值时,dispatch进行异常告警,并发送信令包给业务处理进程,令其重启。
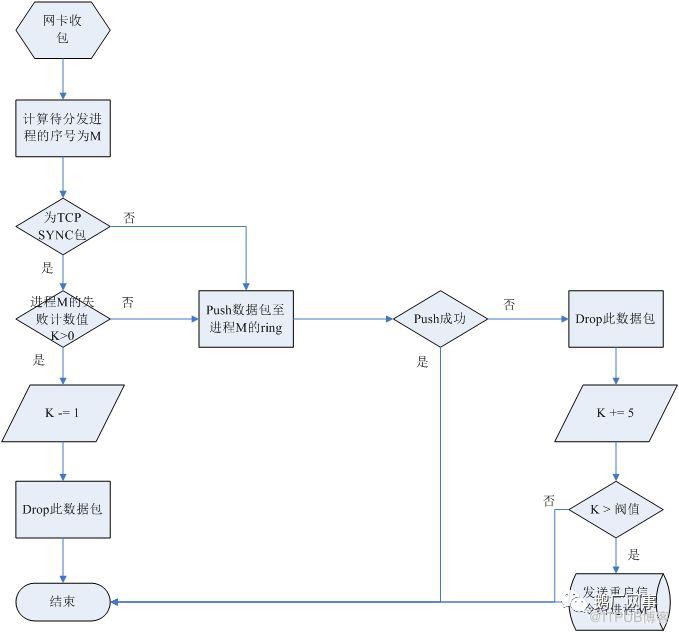
经此优化后,HttpDNS在过载情况下,各业务进程CPU使用率都接近100%,用户请求包的丢包率及丢包持续时间下降了30%以上。而且最重要的是,过载情况下的业务恢复已全程实现了自动化,再也不需要人为进行干预!至此,从架构设计到实现优化,从概念验证到现网运营,腾讯HttpDNS服务顶住了压力,实现了以极低的成本,支撑了千亿级的海量业务稳定运营。
四、 明日之后
HttpDNS服务的本意是为了解决特定场景下的域名解析服务的问题,但在不经意间却打开了一道通往通用软件定义流量调度解决方案的大门,赋予了内容服务提供商、移动互联网开发者对于用户访问的更便捷、更精细化的调度能力。名字服务是流量调度最优雅的解决方案,更为精细、智能、简单、通用HttpDNS 2.0全局流量调度解决方案已然在路上,一切只是刚刚开始,敬请期待!
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31558022/viewspace-2219748/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31558022/viewspace-2219748/