A Review on Deep Learning Techniques Applied to Semantic Segmentation
- Introduction
- Terminology and Background Concepts
- 1 Common Deep Network Architectures
- AlexNet
- VGG-16
- GoogLeNet
- ResNet
- ReNet
- 2 Transfer Learning
- 3 Data Preprocessing and Augmentation
- 1 Common Deep Network Architectures
- Datasets and Challenges
- Methods
- 2 Integrating Context Knowledge
- 21 CRFConditional Random Fields
- 22 Dilated Convolutions
- 23 Multi-scale Prediction
- 24 Feature Fusion
- 25 RNN
- 3 Instance Segmentation暂时用不到
- 4 RGB-D Data暂时用不到
- 5 3D Data
- 2 Integrating Context Knowledge
1. Introduction

classification -> localization -> semantic segmentation -> instance segmentation
2. Terminology and Background Concepts
2.1 Common Deep Network Architectures
AlexNet
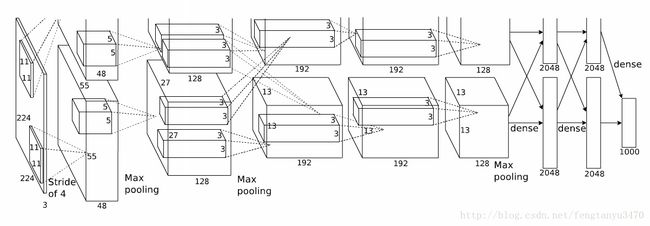
(上面这幅图是Alex原文的图,用的是两台GPU)
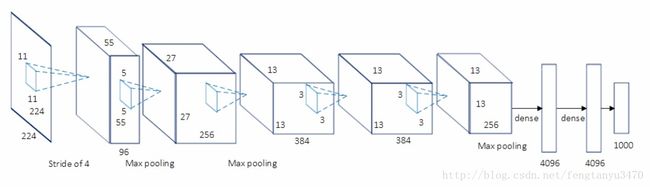
- five convolutional layers
- max-pooling ones
- ReLUs
- three fully-connected layers
- dropout
具体分析:
1. conv1:
224*224*3(RGB)
–> 预处理(?)
–> 227*227*3
–> 96个filter1, size=11*11*3(也是RGB三通道), stride=4
–> (227-11)/4+1=55,输出=55*55*96
–> ReLU1
–> max pooling1, size=3, stride=2
–> (55-3)/2+1=27,输出:27*27*96
–> norm1,local size=5(跨通道归一化)
–> 输出:27*27*96
2. conv2:
–> 256个filter2(计算不同?),size=5*5,stride=1, zero padding=2, (27+2*2-5)/1+1=27, 输出=27*27*256
–> ReLU2
–> max pooling2, size=3, stride=2,(27-3)/2+1=13,输出=13*13*256
–> norm2,local size=5
–> 输出=13*13*256
3. conv3:
–> 384个filter3,size=3*3,stride=1, zero padding=1, (13+2*1-3)/1+1=13,输出=13*13*384
–> ReLU3
–> 输出=13*13*384
4. conv4:
–> 384个filter4, size=3*3, stride=1, zero padding=1, (13+2*1-3)/1+1=13,输出=13*13*384
–> ReLU4
–> 输出=13*13*384
5. conv5:
–> 256个filter5, size=3*3, stride=1, zero padding=1, (13+2*1-3)/1+1=13,输出=13*13*256
–> ReLU5
–> max pooling3, size=3, stride=2, (13-3)/2+1=6
–> 输出=6*6*256
6. fc6:
–> fc6, node=4096
–> 输出=4096
–> ReLU6
–> dropout6
–> 输出=4096
7. fc7:
–> fc7, node=4096
–> ReLU7
–> dropout7
–> 输出=4096
8. fc8:
–> fc8, node=1000
–> 输出=1000
VGG-16
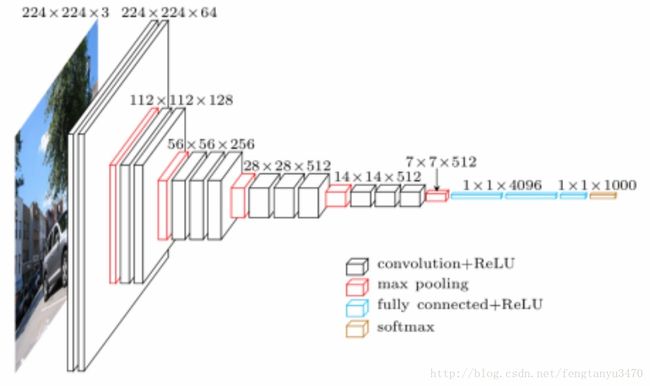
highlight: they use a stack of convolution layers with small receptive fileds in the first layers instead of few layers with big receptive fields(predecessors).
- less parameters –> make model easier to train
- more non-linearties –> make decision function more discriminative
GoogLeNet
参考
motivation
一般来说,提升神经网络性能的最直接办法就是增加网络的深度和宽度,但这样会导致非常多的参数,参数多不仅会使计算量大而且容易产生过拟合。GoogLeNet文章认为解决这些问题的根本方法是将全连接或卷积转换成稀疏的连接。一方面因为生物神经系统的连接也是稀疏的,另一方面有NIN(Network in network)证明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络,这点表明臃肿的稀疏网络可以被不失性能的简化。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。

inception module就是想通过密集成分来近似最优的局部稀疏结构。
- 采用大小不用的卷积核进行拼接是为了有大小不同的感受野,选size为1,3,5,对应的padding就是0,1,2,这样就得到相同大小的feature map,然后进行拼接
- 文章说加入pooling层是因为听说很多地方都表明pooling层挺有效的:P
- 1*1卷积层是为了降维,借鉴文献
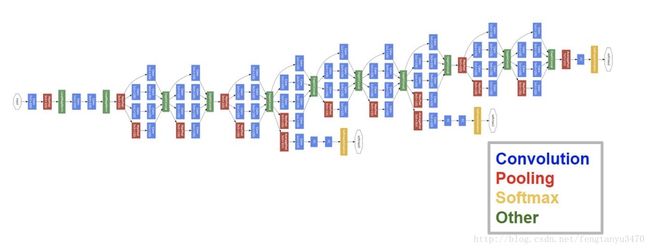
- GoogLeNet采用模块化结构,方便修改
- 再次借鉴NIN(Network in network),网络最后采用average pooling来代替全连接层,能将TOP1-accuracy提高0.6%,但是,实际在最后还是加了一个全连接层,主要是为了方便以后finetune。

后来Google团队又提出了GoogLeNet的升级版
Rethinking the Inception Architecture for Computer Vision
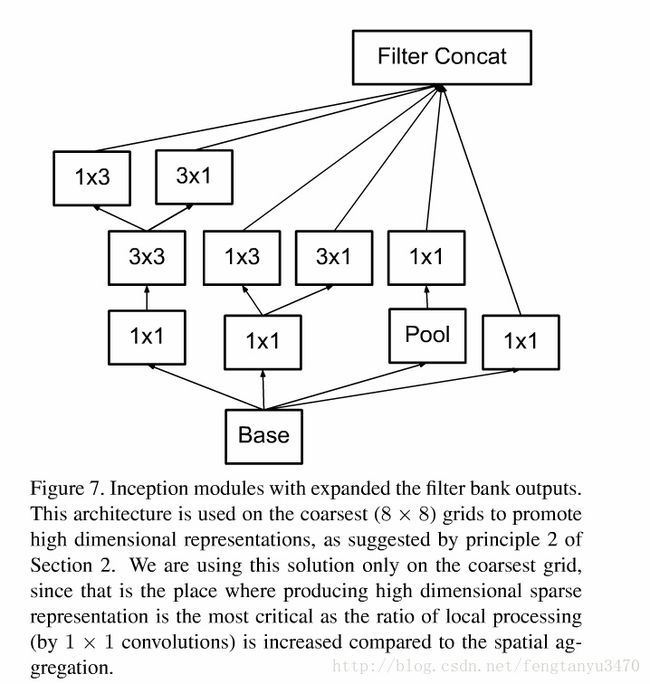
其主要思想是在扩大网络的同时又尽可能的发挥计算性能。

大尺寸的卷积核意味着有较大的感受野,但参数更多,文章提出用两个连续的3*3卷积层(stride=1)
文章说大量实验证明:
- 这种代替其表达能力不会下降
- 第一个3*3卷积后也加入activator会提高性能
文章继续思考能不能分解的更小呢?比如n*1
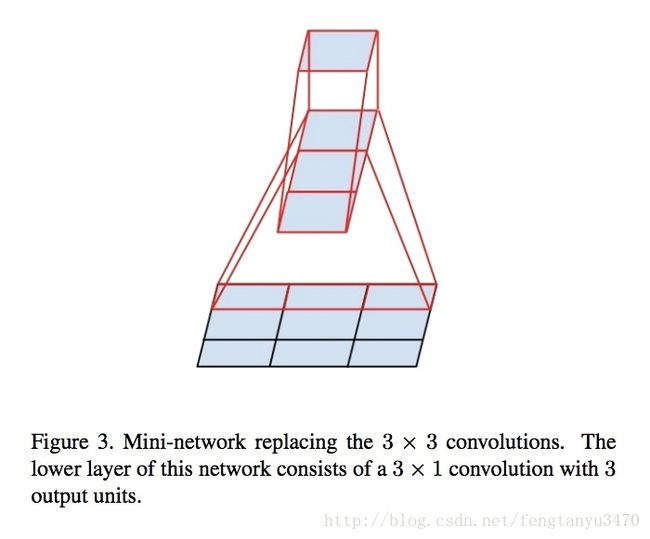
任意的n*n卷积都可以用1*n卷积后接n*1卷积来代替。
但是实际上,文章发现在网络的前期使用这种分解效果并不好,其次在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
ResNet
Deep Residual Learning for Image Recognition
花絮:MSRA的何凯明团队提出的ResNet在2015年的ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,而且影响了2016年DL在学术界和工业界的发展方向。
motivation
随着网络深度增加,会产生梯度弥散/爆炸,导致功能”退化“,错误率增高,但原因并不是过拟合,如下图

但照理说深度越深,学习能力应该越强,不应该产生更大错误率,究其原因是由于深度变深后,SGD(随机梯度下降)更难优化,所以错误率增高。
solution
针对这个问题,文章提出了一个residual结构

即增加了一个indentity mapping(恒等映射),将原来要学的H(x)变成F(x)+x。文章假设这种替换不会影响效果,而且F(x)的优化要比H(x)简单的多。
实验证明,这个残差块往往需要两层以上,单单一层的残差块(y=W1x+x)并不能起到提升作用。

该模型最大优势是计算量比之前的VGG-19小很多
results
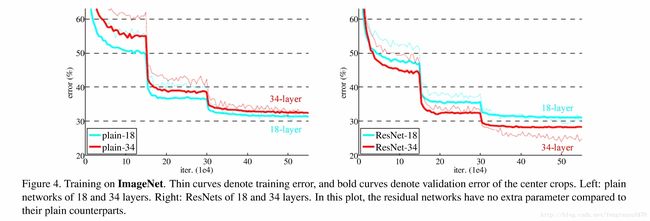
同时通过实验发现,网络深度增加到50,101,152层,ResNet效果依然很好,作者一直试到1202层(��),SGD优化依然没有问题,但是出现了过拟合。
ReNet
Renet: A recurrent neural network based alternative to convolutional networks
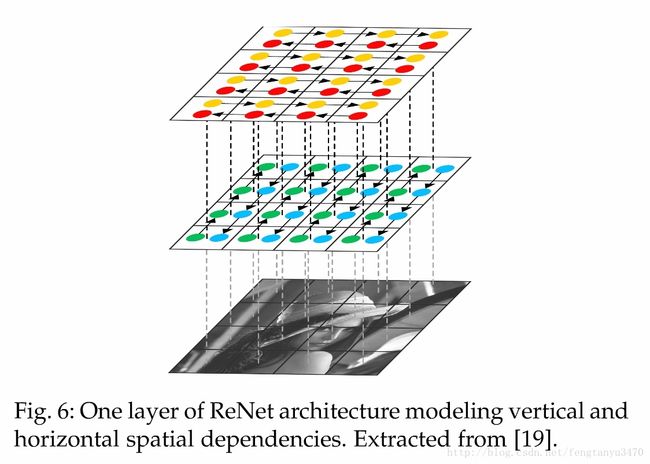
2.2 Transfer Learning
- 在设初值时,用迁移学习的结果比简单的随机赋值要好得多
- fine-tuning一般作用于网络的较高层
- 对于pre-trained classification networks来说,进行transfer learning 和 fine-tuning处理是common trend
2.3 Data Preprocessing and Augmentation
translation, rotation, warping, scaling, color space shifts, crops, etc.
3. Datasets and Challenges
整理了常用的数据库

此外还有2.5D和3D的数据库,详见论文
4. Methods
目前semantic segmentation的state-of-the-art还是FCN
但是仍然有它的局限性:
- 全连接层无法有效利用全局的位置信息
- 无法做到instance segmentation
- 性能上还无法满足高分辨率实时处理
- 无法处理不规则模型,如3D点云图

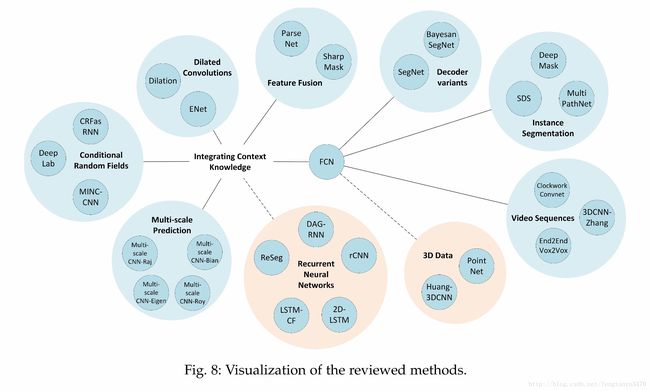
4.2 Integrating Context Knowledge
4.2.1 CRF(Conditional Random Fields)
CRF能较好解决CNN在segmentation上的spatial accuracy问题
目前比较有影响力的有两个
- The DeepLab models make use of the fully connected pairwise CRF by Kr¨ ahenb ¨ uhl and Koltun as a separated post-processing step in their pipeline
to refne the segmentation result

- CRFasRNN by Zheng
4.2.2 Dilated Convolutions
是一种在保证分辨率前提下扩大感受野的卷积

can fill the empty elements with zero
文章也列出了目前这方面做的比较好的papers
4.2.3 Multi-scale Prediction

4.2.4 Feature Fusion
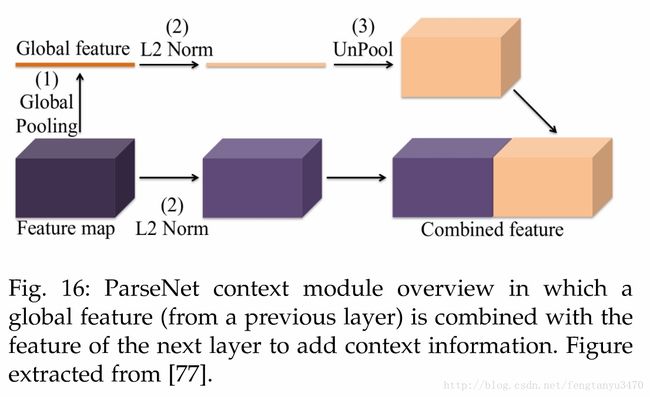
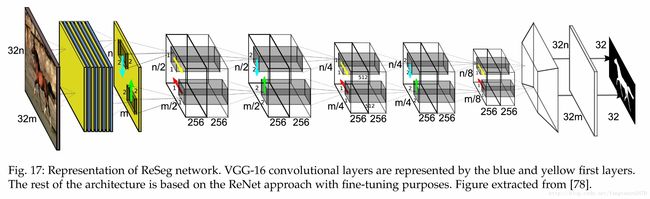
4.2.5 RNN
4.3 Instance Segmentation(暂时用不到)
4.4 RGB-D Data(暂时用不到)
4.5 3D Data
未完待续
P.S. 3D的segmentation目前进展不多
文章参考了很多网上资料,有的忘记citation了,如有侵权,麻烦告知