Flink DataStream API编程指南
Flink DataStream API主要分为三个部分,分别为Source、Transformation以及Sink,其中Source是数据源,Flink内置了很多数据源,比如最常用的Kafka。Transformation是具体的转换操作,主要是用户定义的处理数据的逻辑,比如Map,FlatMap等。Sink(数据汇)是数据的输出,可以把处理之后的数据输出到存储设备上,Flink内置了许多的Sink,比如Kafka,HDFS等。另外除了Flink内置的Source和Sink外,用户可以实现自定义的Source与Sink。考虑到内置的Source与Sink使用起来比较简单且方便,所以,关于内置的Source与Sink的使用方式不在本文的讨论范围之内,本文会先从自定义Source开始说起,然后详细描述一些常见算子的使用方式,最后会实现一个自定义的Sink。
数据源
Flink内部实现了比较常用的数据源,比如基于文件的,基于Socket的,基于集合的等等,如果这些都不能满足需求,用户可以自定义数据源,下面将会以MySQL为例,实现一个自定义的数据源。本文的所有操作将使用该数据源,具体代码如下:
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/4/14
* @Time: 17:34
* note: RichParallelSourceFunction与SourceContext必须加泛型
*/
public class MysqlSource extends RichParallelSourceFunction {
public Connection conn;
public PreparedStatement pps;
private String driver;
private String url;
private String user;
private String pass;
/**
* 该方法只会在最开始的时候被调用一次
* 此方法用于实现获取连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
//初始化数据库连接参数
Properties properties = new Properties();
URL fileUrl = TestProperties.class.getClassLoader().getResource("mysql.ini");
FileInputStream inputStream = new FileInputStream(new File(fileUrl.toURI()));
properties.load(inputStream);
inputStream.close();
driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
pass = properties.getProperty("pass");
//获取数据连接
conn = getConection();
String scanSQL = "SELECT * FROM user_behavior_log";
pps = conn.prepareStatement(scanSQL);
}
@Override
public void run(SourceContext ctx) throws Exception {
ResultSet resultSet = pps.executeQuery();
while (resultSet.next()) {
ctx.collect(UserBehavior.of(
resultSet.getLong("user_id"),
resultSet.getLong("item_id"),
resultSet.getInt("cat_id"),
resultSet.getInt("merchant_id"),
resultSet.getInt("brand_id"),
resultSet.getString("action"),
resultSet.getString("gender"),
resultSet.getLong("timestamp")));
}
}
@Override
public void cancel() {
}
/**
* 实现关闭连接
*/
@Override
public void close() {
if (pps != null) {
try {
pps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取数据库连接
*
* @return
* @throws SQLException
*/
public Connection getConection() throws IOException {
Connection connnection = null;
try {
//加载驱动
Class.forName(driver);
//获取连接
connnection = DriverManager.getConnection(
url,
user,
pass);
} catch (Exception e) {
e.printStackTrace();
}
return connnection;
}
}
首先继承RichParallelSourceFunction,实现继承的方法,主要包括open()方法、run()方法及close方法。上述的
RichParallelSourceFunction是支持设置多并行度的,关于RichParallelSourceFunction与RichSourceFunction的区别,前者支持用户设置多并行度,后者不支持通过setParallelism()方法设置并行度,默认的并行度为1,否则会报如下错误:bashException in thread "main" java.lang.IllegalArgumentException: The maximum parallelism of non parallel operator must be 1.
另外,RichParallelSourceFunction提供了额外的open()方法与close()方法,如果定义Source时需要获取链接,那么可以在open()方法中进行初始化,然后在close()方法中关闭资源链接,关于Rich***Function与普通Function的区别,下文会详细解释,在这里先有个印象。上述的代码中的配置信息是通过配置文件传递的,由于篇幅限制,我会把本文的代码放置在github,见文末github地址。
基本转换
Flink提供了大量的算子操作供用户使用,常见的算子主要包括以下几种,注意:本文不讨论关于基于时间与窗口的算子,这些内容会在《Flink基于时间与窗口的算子》中进行详细介绍。
说明:本文的操作是基于上文自定义的MySQL Source,对应的数据解释如下:
userId; // 用户ID
itemId; // 商品ID
catId; // 商品类目ID
merchantId; // 卖家ID
brandId; // 品牌ID
action; // 用户行为, 包括("pv", "buy", "cart", "fav")
gender; // 性别
timestamp; // 行为发生的时间戳,单位秒
Map
解释
DataStream → DataStream 的转换,输入一个元素,返回一个元素,如下操作:
SingleOutputStreamOperator userBehaviorMap = userBehavior.map(new RichMapFunction() {
@Override
public String map(UserBehavior value) throws Exception {
String action = "";
switch (value.action) {
case "pv":
action = "浏览";
case "cart":
action = "加购";
case "fav":
action = "收藏";
case "buy":
action = "购买";
}
return action;
}
});
示意图
将雨滴形状转换成相对应的圆形形状的map操作

flatMap
解释
DataStream → DataStream,输入一个元素,返回零个、一个或多个元素。事实上,flatMap算子可以看做是filter与map的泛化,即它能够实现这两种操作。flatMap算子对应的FlatMapFunction定义了flatMap方法,可以通过向collector对象传递数据的方式返回0个,1个或者多个事件作为结果。如下操作:
SingleOutputStreamOperator userBehaviorflatMap = userBehavior.flatMap(new RichFlatMapFunction() {
@Override
public void flatMap(UserBehavior value, Collector out) throws Exception {
if (value.gender.equals("女")) {
out.collect(value);
}
}
});
示意图
将黄色的雨滴过滤掉,将蓝色雨滴转为圆形,保留绿色雨滴

Filter
解释
DataStream → DataStream,过滤算子,对数据进行判断,符合条件即返回true的数据会被保留,否则被过滤。如下:
SingleOutputStreamOperator userBehaviorFilter = userBehavior.filter(new RichFilterFunction() {
@Override
public boolean filter(UserBehavior value) throws Exception {
return value.action.equals("buy");//保留购买行为的数据
}
});
示意图
将红色与绿色雨滴过滤掉,保留蓝色雨滴。

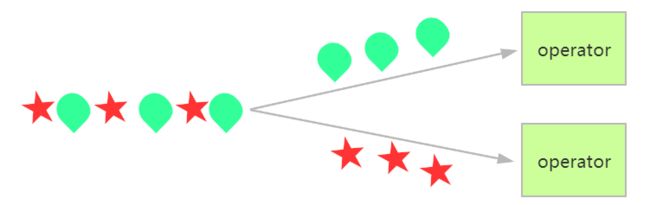
keyBy
解释
DataStream→KeyedStream,从逻辑上将流划分为不相交的分区。具有相同键的所有记录都分配给同一分区。在内部,keyBy()是通过哈希分区实现的。
定义键值有3中方式:
(1)使用字段位置,如keyBy(1),此方式是针对元组数据类型,比如tuple,使用元组相应元素的位置来定义键值;
(2)字段表达式,用于元组、POJO以及样例类;
(3)键值选择器,即keySelector,可以从输入事件中提取键值
SingleOutputStreamOperator> userBehaviorkeyBy = userBehavior.map(new RichMapFunction>() {
@Override
public Tuple2 map(UserBehavior value) throws Exception {
return Tuple2.of(value.action.toString(), 1);
}
}).keyBy(0) // scala元组编号从1开始,java元组编号是从0开始
.sum(1); //滚动聚合
示意图
基于形状对事件进行分区的keyBy操作
Reduce
解释
KeyedStream → DataStream,对数据进行滚动聚合操作,结合当前元素和上一次Reduce返回的值进行聚合,然后返回一个新的值.将一个ReduceFunction应用在一个keyedStream上,每到来一个事件都会与当前reduce的结果进行聚合,
产生一个新的DataStream,该算子不会改变数据类型,因此输入流与输出流的类型永远保持一致。
SingleOutputStreamOperator> userBehaviorReduce = userBehavior.map(new RichMapFunction>() {
@Override
public Tuple2 map(UserBehavior value) throws Exception {
return Tuple2.of(value.action.toString(), 1);
}
}).keyBy(0) // scala元组编号从1开始,java元组编号是从0开始
.reduce(new RichReduceFunction>() {
@Override
public Tuple2 reduce(Tuple2 value1, Tuple2 value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1 + value2.f1);//滚动聚合,功能与sum类似
}
});
示意图
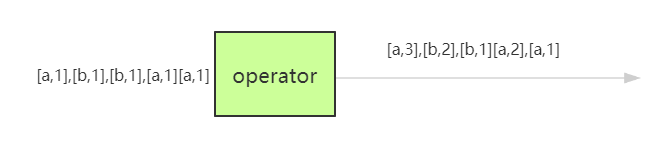
Aggregations(滚动聚合)
KeyedStream → DataStream,Aggregations(滚动聚合),滚动聚合转换作用于KeyedStream流上,生成一个包含聚合结果(比如sum求和,min最小值)的DataStream,滚动聚合的转换会为每个流过该算子的key值保存一个聚合结果,
当有新的元素流过该算子时,会根据之前的结果值和当前的元素值,更新相应的结果值
-
sum():滚动聚合流过该算子的指定字段的和;
-
min():滚动计算流过该算子的指定字段的最小值
-
max():滚动计算流过该算子的指定字段的最大值
-
minBy():滚动计算当目前为止流过该算子的最小值,返回该值对应的事件;
-
maxBy():滚动计算当目前为止流过该算子的最大值,返回该值对应的事件;
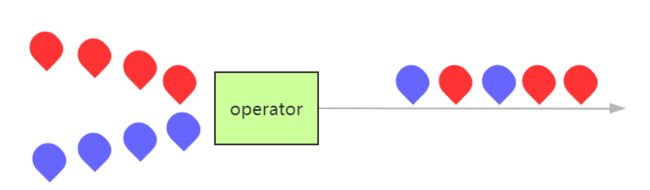
union
解释
DataStream* → DataStream,将多条流合并,新的的流会包括所有流的数据,值得注意的是,两个流的数据类型必须一致,另外,来自两条流的事件会以FIFO(先进先出)的方式合并,所以并不能保证两条流的顺序,此外,union算子不会对数据去重,每个输入事件都会被发送到下游算子。
userBehaviorkeyBy.union(userBehaviorReduce).print();//将两条流union在一起,可以支持多条流(大于2)的union
示意图
connect
解释
DataStream,DataStream → ConnectedStreams,将两个流的事件进行组合,返回一个ConnectedStreams对象,两个流的数据类型可以不一致,ConnectedStreams对象提供了类似于map(),flatMap()功能的算子,如CoMapFunction与CoFlatMapFunction分别表示map()与flatMap算子,这两个算子会分别作用于两条流,注意:CoMapFunction 或CoFlatMapFunction被调用的时候并不能控制事件的顺序只要有事件流过该算子,该算子就会被调用。
ConnectedStreams> behaviorConnectedStreams = userBehaviorFilter.connect(userBehaviorkeyBy);
SingleOutputStreamOperator> behaviorConnectedStreamsmap = behaviorConnectedStreams.map(new RichCoMapFunction, Tuple3>() {
@Override
public Tuple3 map1(UserBehavior value1) throws Exception {
return Tuple3.of("first", value1.action, 1);
}
@Override
public Tuple3 map2(Tuple2 value2) throws Exception {
return Tuple3.of("second", value2.f0, value2.f1);
}
});
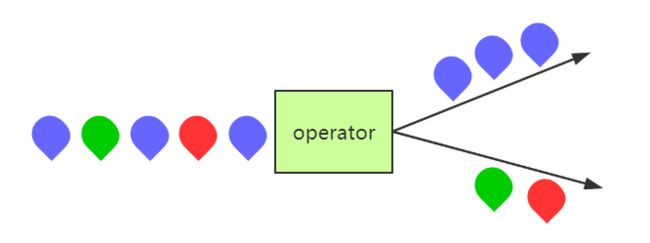
split
解释
DataStream → SplitStream,将流分割成两条或多条流,与union相反。分割之后的流与输入流的数据类型一致,
对于每个到来的事件可以被路由到0个、1个或多个输出流中。可以实现过滤与复制事件的功能,DataStream.split()接收一个OutputSelector函数,用来定义分流的规则,即将满足不同条件的流分配到用户命名的一个输出。
SplitStream userBehaviorSplitStream = userBehavior.split(new OutputSelector() {
@Override
public Iterable select(UserBehavior value) {
ArrayList userBehaviors = new ArrayList();
if (value.action.equals("buy")) {
userBehaviors.add("buy");
} else {
userBehaviors.add("other");
}
return userBehaviors;
}
});
userBehaviorSplitStream.select("buy").print();
示意图
Sink
Flink提供了许多内置的Sink,比如writeASText,print,HDFS,Kaka等等,下面将基于MySQL实现一个自定义的Sink,可以与自定义的MysqlSource进行对比,具体如下:
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/4/16
* @Time: 22:53
*
*/
public class MysqlSink extends RichSinkFunction {
PreparedStatement pps;
public Connection conn;
private String driver;
private String url;
private String user;
private String pass;
/**
* 在open() 方法初始化连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
//初始化数据库连接参数
Properties properties = new Properties();
URL fileUrl = TestProperties.class.getClassLoader().getResource("mysql.ini");
FileInputStream inputStream = new FileInputStream(new File(fileUrl.toURI()));
properties.load(inputStream);
inputStream.close();
driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
pass = properties.getProperty("pass");
//获取数据连接
conn = getConnection();
String insertSql = "insert into user_behavior values(?, ?, ?, ?,?, ?, ?, ?);";
pps = conn.prepareStatement(insertSql);
}
/**
* 实现关闭连接
*/
@Override
public void close() {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (pps != null) {
try {
pps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 调用invoke() 方法,进行数据插入
*
* @param value
* @param context
* @throws Exception
*/
@Override
public void invoke(UserBehavior value, Context context) throws Exception {
pps.setLong(1, value.userId);
pps.setLong(2, value.itemId);
pps.setInt(3, value.catId);
pps.setInt(4, value.merchantId);
pps.setInt(5, value.brandId);
pps.setString(6, value.action);
pps.setString(7, value.gender);
pps.setLong(8, value.timestamp);
pps.executeUpdate();
}
/**
* 获取数据库连接
*
* @return
* @throws SQLException
*/
public Connection getConnection() throws IOException {
Connection connnection = null;
try {
//加载驱动
Class.forName(driver);
//获取连接
connnection = DriverManager.getConnection(
url,
user,
pass);
} catch (Exception e) {
e.printStackTrace();
}
return connnection;
}
}
关于RichFunction
细心的读者可以发现,在前文的算子操作案例中,使用的都是RichFunction,因为在很多时候需要在函数处理数据之前先进行一些初始化操作,或者获取函数的上下文信息,DataStream API提供了一类RichFunction,与普通的函数相比,该函数提供了许多额外的功能。
使用RichFunction的时候,可以实现两个额外的方法:
-
open(),是初始化方法,会在每个人物首次调用转换方法(比如map)前调用一次。通常用于进行一次的设置工作,注意Configuration参数只在DataSet API中使用,而并没有在DataStream API中使用,因此在使用DataStream API时,可以将其忽略。
-
close(),函数的终止方法 ,会在每个任务最后一次调用转换方法后调用一次,通常用于资源释放等操作。
此外用户还可以通过getRuntimeContext()方法访问函数的上下文信息(RuntimeContext),例如函数的并行度,函数所在subtask的编号以及执行函数的任务名称,同时也可以访问分区状态。
总结
本文首先实现了自定义MySQL Source,然后基于MySql 的Source进行了一系列的算子操作,并对常见的算子操作进行详细剖析,最后实现了一个自定义MySQL Sink,并对RichFunction进行了解释。
代码地址:https://github.com/jiamx/study-flink