【转】Word2Vec原理之层次Softmax算法
本文转载自:http://qiancy.com/2016/08/17/word2vec-hierarchical-softmax/
在这个人工智能半边天,主流话题一天一变的现代世界里,不乏进步,也不乏泡沫,但Word2Vec依然是很富极客精神的典型代表,作者思路很巧妙,工程层面又很实用主义。
词嵌入的假设,是通过一个词所在的上下文可以获得词的语义甚至语法结构,有相似上下文的词在向量空间中是邻近的点。
1 背景概念
Word2Vec要解决的根本问题,说到底是自然语言处理的问题。一般认为自然语言处理模型氛围两大派系,分别是形式文法和统计语言模型。
1.1 统计语言模型
统计语言模型在分词、词性标注、语义理解等NLP基本任务,以及语音识别、机器翻译等领域有广泛应用。关于统计语言模型,文献资料非常多,这篇博客也讲的很详细。简单地说,可以用统一地形式化表示:
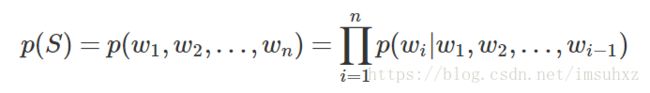
上述表示可以看做是用来计算词构成一个句子的概率模型,这就是统计语言模型的本质。但是概率的计算是个大问题,数据稀疏、参数过多,很难实际运用。前辈们研究了各种模型。例如n-gram、n-pos、决策树模型、最大熵模型等。
1.1.1 n-gram
基于马尔科夫假设,即认为每个词只与前面n−1个词(上下文)有关。例如3-gram:

至于n的选择,在NLP任务中,普遍认为只需使用2或3,而概率的计算实质为:
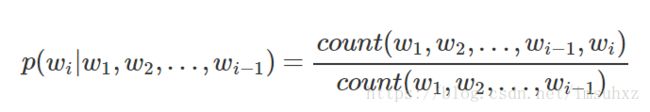
1.1.2 神经网络语言模型(NNLM)
Distributed Representation的代表,每个输入词都是一个实数向量,而模型包含输入层、投影层、隐藏层和输出层。这个直接读Bengio2003的论文《A Neural Probabilistic Language Model》。
1.1.3 Log-Bilinear模型
虽然与Word2Vec关系紧密,但与本文话题暂时不相干,所以暂不展开。可参考Hinton2007年的论文[5]
1.2 词向量
一般认为词向量作为概率语言模型的重要组成部分,其普及也主要是《A neural probabilistic language model》中用到的一种工具,简单说来任意词w,可以用一个固定长度的实值向量v来表示,这个v就是w的词向量。
具体地,词如何用向量来表示?通常认为有两种基本思路,一种称为One-hot Representation,而另一种叫做Distributed Representation。
One-hot的表示方法,非常稀疏, 每个词就是一个很长的向量,向量的维度就是词表的大小,而只有该词对应位置的数字是1,其他都是0。这种表示方法无法捕捉词与词之间的相似关系,且容易发生维数灾难。
Distributed的表示方法,Hinton在1986年提出,大致思想是用较低维度的实数向量来表示词,而用词之间的距离(例如余弦距离)来表示相似度。普遍认为这种方法能够较好地捕捉词与词之间的语义相似度。
许多模型或方法可以用来获取词向量,除了word2vec使用的模型外,LSA矩阵分解模型、pLSA潜在语义分析模型、LDA文档生成模型,也均可用来估计词向量。
例如一个一个size为30的词向量,可能是类似如下的样子:
2 数据结构
2.1 Huffman编码
Huffman编码是一种用于无损数据压缩的熵编码(权编码)算法。由大卫·霍夫曼在1952年发明。该方法通过一种变长编码表来对符号进行编码,而变长编码表是通过评估符号出现概率的方法得到,目标是出现概率高的符号使用较短的编码,出现概率低的符号则使用较长的编码。这种方式能有效降低编码之后的字符串的平均长度。
在谈论数据结构的时候,Huffman编码又称为最优二叉树,表示一种带权路径长度最短的二叉树。带权路径长度,指的就是叶子结点的权值乘以该结点到根结点的路径长度。
因此最短长度问题被转化为构建一个由字符(每个字符都是叶子结点)的出现频率作为权值所产生的Huffman树的问题。
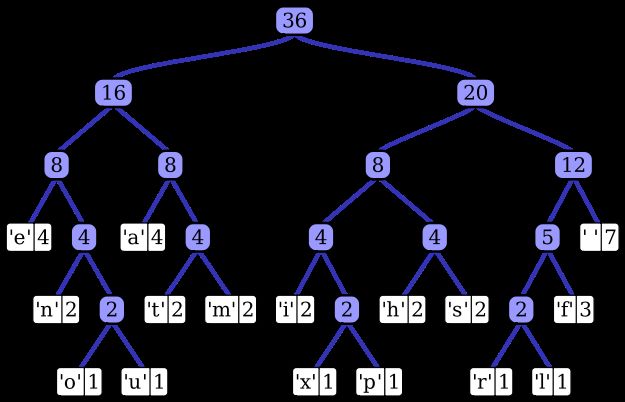
详细解释参见维基百科。Huffman树的结构类似下图:

2.2 构造Huffman树
算法描述:假设有n个权值,则构造出来的Huffman树有n个叶子结点。若n个权值分别为{w1,w2,…,wn}。
- 将{w1,w2,…,wn}当做n棵树(每棵树1个结点)组成的森林。
- 选择根结点权值最小的两棵树,合并,获得一棵新树,且新树的根结点权值为其左、右子树根结点权值之和。词频大的结点作为左孩子结点,词频小的作为右孩子结点。
- 从森林中删除被选中的树,保留新树。
- 重复2、3步,直至森林中只剩下一棵树为止。
3 模型概要
3.1 CBOW
CBOW(Continuous Bag-of-Words Model):在已知上下文,例如wt−2,wt−1,wt+1,wt+2的前提下,如何预测当前词wt。学习的目标函数是最大化对数似然函数:
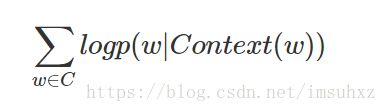
3.2 Skip-gram
Skip-gram(Continuous Skip-gram Model):在已知当前词wt的前提下,预测其上下文,例如wt−2,wt−1,wt+1,wt+2。目标函数形如:

3.3 模型比较
CBOW和Skip-gram均为三层神经网络(输入层、投影层和输出层),而上下文的词的具体个数是可定义的。窗口大小为5时,两个模型的网络结构如下:
 

同样用于计算概率值,从模型的计算方式看,skip-gram想要预测更多(上下文),一次会更比CBOW慢一些,但有观点认为对低频词效果更好一些。
4 算法策略
然而,上面的公式计算很不切实际,因为计算logp(wt+j|wt)的梯度与W的大小直接相关。为了降低复杂度,Word2Vec使用了Hierarchical Softmax和Negative Sampling两种求解策略。普遍认为Hierarchical Softmax对低频词效果较好;Negative Sampling对高频词效果较好,向量维度较低时效果更好。
4.1 Hierarchical Softmax
作为一种计算高效的近似方法,Hierarchical Softmax被广泛使用。Morin和Bengio[1]首先将这种方法引入神经网络语言模型。该方法不用为了获得概率分布而评估神经网络中的W个输出结点,而只需要评估大约log2(W)个结点。层次Softmax使用一种二叉树结构来表示词典里的所有词,V个词都是二叉树的叶子结点,而这棵树一共有V−1个非叶子结点。
对于每个叶子结点(词),总有一条从根结点出发到该结点的唯一路径。这个路径很重要,因为要靠它来估算这个词出现的概率。以下图为例(图来自Xin Rong,2014[6]),白色结点为词典中的词,深色是非叶子结点。图中画出了从根结点到词w2的唯一路径,路径长度L(w2)=4,而n(w,j)表示从根结点到词w2的路径上的的第j个结点。
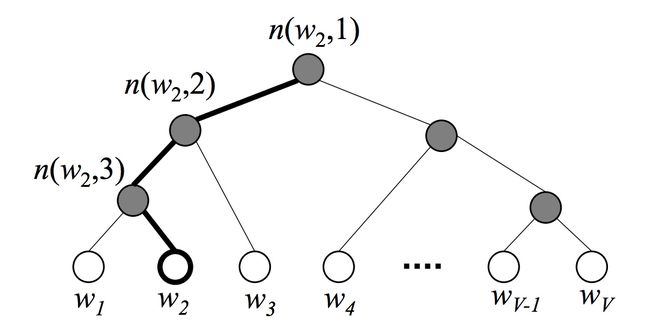 

在层次Softmax模型中,叶子节点的词没有直接输出的向量,而非叶子节点其实都有响应的输出向量。
4.1.1 求目标词的概率
在模型的训练过程中,通过Huffman编码,构造了一颗庞大的Huffman树,同时会给非叶子结点赋予向量。我们要计算的是目标词w的概率,这个概率的具体含义,是指从root结点开始随机走,走到目标词w的概率。因此在途中路过非叶子结点(包括root)时,需要分别知道往左走和往右走的概率。例如到达非叶子节点n的时候往左边走和往右边走的概率分别是:

以上图中目标词为w2为例,
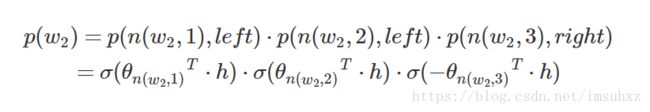
到这里可以看出目标词为w的概率可以表示为:
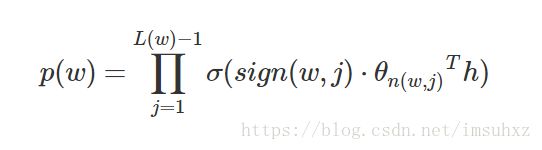
其中θn(w,j)是非叶子结点n(w,j)的向量表示(即输出向量);h是隐藏层的输出值,从输入词的向量中计算得来;sign(x,j)是一个特殊函数定义:
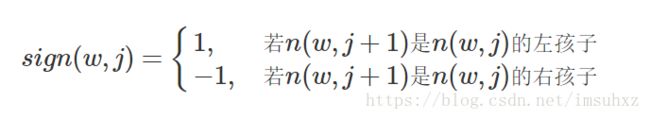
此外,所有词的概率和为1,即:

4.1.2 参数更新公式
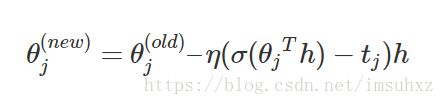
θ(new)j=θ(old)j–η(σ(θjTh)−tj)h
其中,j=1,2,…,L(w)−1
4.2 Negative Sampling
Hierarchical Softmax的另一个替代方法叫做Noise Contrastive Estimation(NCE),Gutmann和Hyvarinen[2]介绍了这种方法,而Mnih和Teh[3]将该方法应用到了语言模型中。然而,Skip-gram模型主要关注如何学习出更高质量的矢量表示。因此可以在确保矢量质量的情况下,尽量地简化NCE。
这部分内容这里暂时不展开。
5 预处理技巧
以下根据源代码来看下两个初始化环节。
5.1 词典构建
拿到sentences以后首先是创建词典,即从文本序列中创建一个词典。词典数据是一个词对应一个出现次数,词典的规模是可以定义的,有一个参数叫做max_vocab_size即是用来限定最大词典量的。因为这是创建词典的过程,一般希望出现频率较高的词被保留,而频率较低的词被略去。所以统计的过程中,如果当前词汇数超过max_vocab_size,则需要按略去词频低于min_reduce的词,初始化的时候,min_reduce为1。随着实际词典的增大,min_reduce有可能会递增。
5.2 SubSampling
全部扫过一遍词典后,需要再次考虑删去总体频率较低的词(出现次数少于min_count的长尾词)。不过,最重要的还是Subsampling。
SubSampling有时候被称作DownSampling,也曾有人译作亚采样,实际是对高频词进行随机采样,关于随机采样的选择问题,考虑高频词往往提供相对较少的信息,因此可以将高于特定词频的词语丢弃掉,以提高训练速度。Mikolov在论文指出这种亚采样能够带来2到10倍的性能提升,并能够提升低频词的表示精度。
采样参数sample表示采样百分比,默认是1e-3,Google推荐的是1e-3至1e-5。

其中f(wi)是词wi的词频,t是阈值。而这个是Mikolov论文里的说法,实际Word2Vec的代码,以及后续gensim的实现,都采用了如下公式来表示词wi被丢弃的概率:
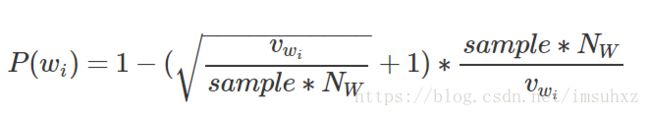
或者这样写看起来简洁一些:
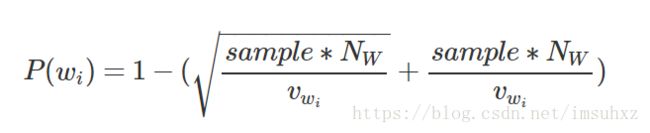
其中:NW是参与训练的单词总数,包含重复单词,实质即词频累加;vwi是词wi的词频。在gensim的实现中,对sample<1和sample≥1的情况区分对待,具体可去看gensim版源码。
参考
[1] Frederic Morin and Yoshua Bengio. Hierarchical probabilistic neural network language model. In Proceedings of the international workshop on artificial intelligence and statistics, pages 246–252, 2005.
[2] Michael U Gutmann and Aapo Hyv¨arinen. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics. The Journal of Machine Learning Research, 13:307–361, 2012.
[3] Andriy Mnih and Yee Whye Teh. A fast and simple algorithm for training neural probabilistic language models. arXiv preprint arXiv:1206.6426, 2012.
[4] Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013a. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations (ICLR).
[5] A. Mnih and G. Hinton. Three new graphical models for statistical language modelling. Proceedings of the 24th international conference on Machine learning, pages 641–648, 2007
[6] Rong X. word2vec parameter learning explained[J]. arXiv preprint arXiv:1411.2738, 2014.
Posted on 2016年8月17日 by cyqian in 研究 | Tagged CBOW, distributed, Hierarchical Softmax, hs, n-gram, NLP, NNLP, one-hot, Skip-gram, Subsampling, word embedding, word2vec, 亚采样, 原理, 层次Softmax, 统计自然语言处理, 自然, 自然语言处理, 词向量, 词嵌入 | 2 Comments