文章目录
- 什么是MongoDb?
- 基本概念
- 与关系型数据库的比较
- Mongo的高效性
- 文件存储
- 基本使用
- 启动/连接服务
- 基础操作命令
- 高可用集群搭建
- 概念
- 环境准备
- 实践
- 应用场景
- 总结
什么是MongoDb?
基本概念
MongoDB是一种支持多语言面向文档的NOSql数据库,它不支持事务操作(4.2版本开始支持跨文档分布式事务)。什么是面向文档?简单说就是使用类JSON的数据结构——BSON(Binary JSON)来存储数据。使用这种数据结构的好处显而易见,关联信息可以直接内嵌在同一个文档中,不必像关系型数据库那样还需要建立多张表,并建立外键关联,因此大大提升了我们写入数据的效率(前端传回的JSON数据可以直接存入,不必转换为对象),也能灵活的增减字段。如论坛文章,如果用关系型数据库存储,我们需要建立文章表和评论表等,而MongoDB直接存到一个文档里去就可以了,查询也非常方便。
与关系型数据库的比较
| 关系型数据库 | MongoDB | 说明 |
|---|---|---|
| Database | Database | 数据库 |
| Table | Collection | Mongo中用集合可以类比表 |
| Row | Document | Mongo中的一个文档(JSON)即相当于关系型数据库中的一行数据 |
| Column | Field | 列/字段 |
| Index | Index | Mongo同样也支持索引 |
| Table join | Mongo不支持关联查询(所有的关联都可以内嵌在一个文档,还要关联干啥呢) | |
| Primary key | Object ID | Mongo在插入数据时会自动生成一个Object ID作为主键 |
通过上面的对比我们不难发现MongoDB中很多概念在关系型数据库中都能找到类比,因此可以说MongoDB是最像关系型数据库的非关系型数据库。同时MongoDB中还支持非常多的数据类型:
| 数据类型 | 描述 | 举例 |
|---|---|---|
| Null | 用于表示空值 | {name: null} |
| String | 字符串。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 | {name: “dark”} |
| Integer | 整型数值。根据你所采用的服务器,可分为 32 位或 64 位。 | {age: 22} |
| Boolean | 布尔值 | {x: true} |
| Double | 双精度浮点值 | {x: 1.11} |
| Arr | 数组 | {x: [1, 2, 3]} |
| Object | 内嵌文档 | {a: {name: “dark”}} |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 | |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 | {date: new Date()} |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 | |
| Object ID | 对象 ID。用于创建文档的 ID。 | {id:ObjectId()} |
| Binary Data | 二进制数据。用于存储二进制数据。 | |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 | {x: function(){}} |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
Mongo的高效性
Mongo和Redis一样是内存数据库,都是先写入内存,然后再写入磁盘持久化保存,因此Mongo读写效率都是非常高的,但也因为此,数据存在丢失的风险,所以Mongo不适合存储核心的业务数据。
文件存储
MongoDB支持以二进制流的方式存储文件,但该方式无法存储超过16M的文件,所以MongoDB提供了GridFS功能。那什么是GridFS?又有什么好处呢?GridFS就是大文件存储解决方案,它自动将大文件分为一个个chunk(一般为256k/个),这些chunk存储在chunk集合中,当在集群环境下且开启了分片功能,这些chunk会自动分散存储在不同的服务器,降低了服务器的存储压力,同时没有增加额外的操作复杂性。
基本使用
启动/连接服务
在了解了MongoDB的基本概念后,再来了解其基本的使用,这里将使用4.0.13-Linux 64 bit legacy版本作为演示版本。在下载解压好之后,我们首先需要在Mongo主目录下创建data和logs两个文件夹,分别存放数据文件和日志文件。然后通过以下命令启动即可(dbpath指定数据存放的目录,logpath指定日志存放的文件,fork表示后台启动,bind_ip则是配置允许访问的ip,若不配置则只能本机客户端连接):
bin/mongod --dbpath=/usr/utils/mongo/data --logpath=/usr/utils/mongo/logs/mongo.log --fork --bind_ip=0.0.0.0
注意在bin目录下会看到mongo、mongos、mongod三个启动文件,其中mongod就是用于启动服务的,mongo是客户端连接用的,mongos则是启动路由服务用的(具体使用会在集群搭建章节讲到)。
启动完成后我们就可以通过以下命令来启动客户端连接:
bin/mongo 127.0.0.1:27017
基础操作命令
- show dbs:查看已有的数据库
- use test:切换到test数据库(没有就新建一个)
- show collections:显示当前数据库的所有集合
- db.testColl.insert({name:“dark”}):往当前数据库的testColl集合插入数据
- db.testColl.find():查询testColl中的所有数据
- db.testColl.findOne():查询testColl中的第一条数据
- db.testColl.update({name:“dark”}, {$set:{age:22}}, true):将name为dark的数据的age修改为22;第三个参数为非必须参数,为true表示未查询到就新增一条,默认是false
- db.testColl.remove({age:22}):删除age为22的所有数据
- db.testColl.drop():删除集合
- db.dropDatabase():删库跑路
这里仅列出一些基本的操作命令,详细的请查看官网,需要注意版本不同命令也会有改变。
高可用集群搭建
概念
MongoDB天然支持集群搭建,有Master-Slave、Replica Set(Master-Arbiter-Slave)、Sharding三种模式。第一种就是一主多从,官方已经不推荐使用;第二种就是在第一种的基础上加入了仲裁者的角色,当主节点挂掉后,会由仲裁者选取出新的主节点,该方式主从节点存储的数据都是相同的,当数据量较大时,性能会有所下降;第三种则是混合部署,可靠性最高,同时复杂程度也最高,这里主要讲解该方式。首先来看下官网混合部署的架构图:
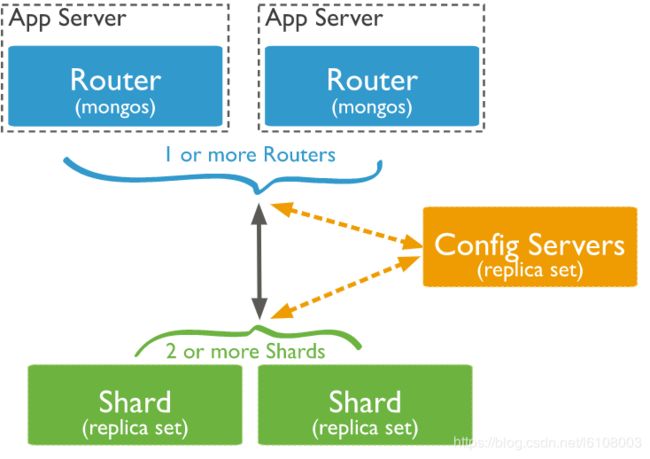
从图中我们可以看到包含三个角色:
- Router:路由服务器,所有请求首先会先经过Router,再由Router进行转发。mongos命令启动的就是路由服务器。
- Config Server:配置服务器,存储了集群的配置以及数据存储位置信息。
- Shard:分片服务器,mongodb天然支持数据分片,并且可以针对每个分片搭建副本集。
当有写入请求来时,首先经过Router服务器,然后Router会去配置服务器查询相关的配置信息,包括数据应该写入的分片区域信息,拿到这些信息后,再将数据写入到对应的分片区域。同样的当有查询请求来时,首先也是由Router服务器到配置服务器查询到对应的配置分片信息,再到具体的服务器去查询结果并返回。
环境准备
理解了整个流程后,下面就来实际搭建这样一个集群,我这里准备了两台虚拟机作为演示用,服务分配如下:
| 192.168.0.106 | 192.168.0.109 | |
|---|---|---|
| 路由服务端口 | 30000 | 无 |
| 配置服务端口 | 28001/28002/28003 | 无 |
| 分片副本集端口 | 27001/27002/27003 | 27001/27002/27003 |
方便起见,我这里将路由、配置和其中一个分片都部署到了一台机器上,用端口作为区分,在另一台虚拟机部署了另外一个分片集是为了便于演示分片和副本集的不同。
实践
- 准备好服务器后,我们首先来配置两台机器的分片。
- 第一步,在mongodb主目录下编写mongo.cfg文件
# 这里我将主目录名改为了replica1/replica2/replica3,对应3个副本集
vim /opt/replset/replica1/mongo.cfg
# 配置内容如下
dbpath=/opt/replset/replica1/data # 数据存放目录,没有需要先创建
logpath=/opt/replset/replica1/logs/mongo.log # 日志存放目录,没有需要先创建logs文件夹
logappend=true # 日志以追加方式写入
fork=true # 后台启动
bind_ip=0.0.0.0 # 开放访问权限
port=27001 # 启动端口
replSet=shard01 # 副本集名称,注意同一个分片下所有副本的这个名字相同
shardsvr=true # 表示这是分片中的一台服务器
- 第二步,复制两个replica,分别重命名为replica2、replica3,并修改配置文件(数据、日志存放目录,启动端口)
- 第三步,启动三个副本集服务,并使副本集生效
# 启动
/opt/replset/replica1/bin/mongod -f /opt/replset/replica1/mongo.cfg
/opt/replset/replica2/bin/mongod -f /opt/replset/replica2/mongo.cfg
/opt/replset/replica3/bin/mongod -f /opt/replset/replica3/mongo.cfg
# 使用任一副本的客户端连接服务,并配置集群生效
/opt/replset/replica1/bin/mongo 192.168.0.106:27001
cfg={_id:"shard001",members:[{_id:0,host:'192.168.0.106:27001'},{_i
d:1,host:'192.168.0.106:27002'},{_id:2,host:'192.168.0.106:27003'
}]};
rs.initiate(cfg) # 初始化配置
rs.status() # 查看副本集状态,包括主从角色
- 配置完成一个分片副本集后,另一台的配置就是一样的了,需要注意将配置中的replSet重命名shard02,同时客户端配置cfg时的ip需要变更为当前服务器的ip。
- 接着配置config服务器,复制一个replica1,重命名为config1
- 同样的,第一步先编写配置文件mongo.cfg
dbpath=/opt/replset/config1/data
logpath=/opt/replset/config1/logs/mongo.log
logappend=true
fork=true
bind_ip=0.0.0.0
port=28001
replSet=configs # 副本集名字
configsvr=true # 表示这是配置服务器
- 第二步也是一样,复制两个config,重命名为config2、config3,并修改配置文件(数据、日志存放目录,启动端口)
- 启动配置服务并使配置服务集生效
/opt/replset/config1/bin/mongod -f /opt/replset/config1/mongo.cfg
/opt/replset/config2/bin/mongod -f /opt/replset/config2/mongo.cfg
/opt/replset/config3/bin/mongod -f /opt/replset/config3/mongo.cfg
/opt/replset/config1/bin/mongo 192.168.0.106:28001
cfg={_id:"configs",members:[{_id:0,host:'192.168.0.106:28001'},{_i
d:1,host:'192.168.0.106:28002'},{_id:2,host:'192.168.0.106:28003'
}]};
rs.initiate(cfg)
- 最后来配置路由节点,步骤和上面也是一样的,主要是配置内容的不同
configdb=configs/192.168.0.106:28001 # 指定配置服务器的地址,填写主节点的就行
logpath=/opt/replset/router1/logs/mongo.log
logappend=true
fork=true
bind_ip=0.0.0.0
port=30000
配置好后,需要启动路由服务,这里就不再是用mongod启动了,而是mongos
/opt/replset/router1/bin/mongod -f /opt/router1/config1/mongo.cfg
至此,我们就将所有服务配置好了,但是还有个问题,上面的配置只能让路由找到配置服务器,还不能请求分片副本集群,所以我们还需要将分片配置添加到配置服务器中保存起来。
/opt/replset/router1/bin/mongo 192.168.0.109:30000 # 连接路由服务器
sh.addShard("shard01/192.168.0.106:27001"); # 添加分片1,只需要添加主节点即可,注意分片名称和ipd地址要对应
sh.addShard("shard02/192.168.0.109:27002"); # 添加分片2
这样我们就将分片配置信息保存到了配置服务器,路由就能通过配置服务器找到对应的节点,下面我们就来测试一下:
use testdb # 进入testdb数据库
sh.enableSharding("testdb")
sh.shardCollection("testdb.testColl",{"name":”hashed”}) # 插入数据之前需要先指定对哪个集合哪个键按照何种方式分片
for(var i=0; i < 100; i++)db.testColl.insert({"name":i}) # 插入100条数据,mongodb支持js脚本
插入完成之后,我们可以通过db.testColl.find()查询数据,不过为了看到分片的效果,我们分别连接两个分片中的任意一台服务器查询:
replica2/bin/mongo 192.168.0.106:27002
replica2/bin/mongo 192.168.0.109:27002
需要注意的是,mongodb默认只允许在主节点上读写信息,如果连接的是从节点需要执行如下命令:
rs.slaveOk()
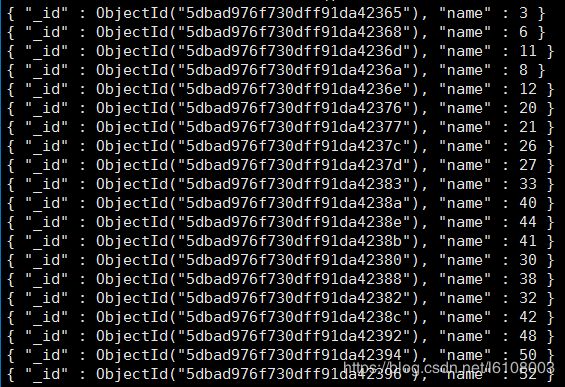
然后切换到对应数据库查询可以看到如下结果:
- 106服务器:
- 109服务器:
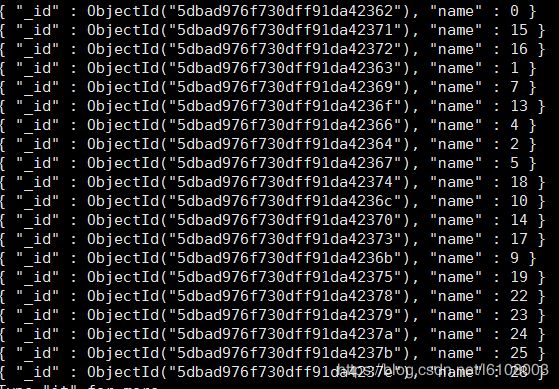
可以发现mongodb自动按照name值将数据分片了,而如果是同一个分片下的服务器存储的则是相同的数据。
应用场景
MongoDB可以应用在哪些场景呢?我们可以从以下几点进行考虑:
- 是否需要事务,MongoDB是不支持事务的,如果需要事务保证,则不适合使用MongoDB,如金融核心业务系统。
- MongoDB是内存型数据库,数据都是先写入内存,在写入磁盘,所以读写效率比较高,但同时也存在数据丢失的可能,因此,对数据可靠性要求较高的业务场景不使用。
- MongoDB天然支持数据分片,在存储价值较低的大数据时可以考虑使用。
- MongoDB不支持连表查询,但是关联数据都可以作为内嵌文档存在。
- MongoDB是以类JSON格式存储数据的,读写不必做对象映射转换。
- 内置GridFS分布式文件存储系统,在做大文件存储时可以考虑。
总结
通过以上学习,我们可以了解到MongoDB的优劣势,在实际的业务场景中可以合理的选择应用,另本篇只是作为基础入门,深入学习还需要查阅官方文档。