金融时间序列分析入门
定义
对某一个或者一组变量X(t)进行观察测量,将在一系列时刻t1, t2, …, tn所得的离散序列集合,称之为时间序列。(注意, X ( t i ) X(t_i) X(ti)是一个随机变量)
特征
- 趋势:是时间序列在长时期内呈现出来的持续向上或持续向下的变动。
- 季节变动:是时间序列在一年内重复出现的周期性波动(周期固定)。它是诸如气候条件、生产条件、节假日或人们的风俗习惯等各种因素影响的结果。
- 循环波动:是时间序列呈现出得非固定长度的周期性变动。循环波动的周期可能会持续一段时间,但与趋势不同,它不是朝着单一方向的持续变动,而是涨落相同的交替波动。
- 不规则波动:是时间序列中除去趋势、季节变动和周期波动之后的随机波动。不规则波动通常总是夹杂在时间序列中,致使时间序列产生一种波浪形或震荡式的变动。只含有随机波动的序列也称为平稳序列。
分析时间序列的本质
前提:我们相信数据的历史信息对未来的信息是有一定预测性的,且形式为多项式+高斯噪声
思路:我们分解t时间的值 x t x_t xt由两部分构成,一部分为由历史数据( x t − 1 , x t − 2 , . . . x_{t-1}, x_{t-2}, ... xt−1,xt−2,...)构造的多项式(ma, ar, arma就是多项式可能的形式);另一部分为高斯噪声;

一些概念
平稳性
时间序列的行为并不随时间改变
严平稳
多元分布保持不变。(X1,X2,X3)是个三维随机变量,(X3,X4,X5)也是个三维随机变量,严格平稳表示任何形如(Xn-1,Xn,Xn+1)的三维随机变量分布都是一样的。当然不仅仅是三维,而是任何维的随机变量分布不变。
严平稳表示的分布不随时间的改变而改变。我研究第1到第n个随机变量跟第2到第n+1个随机变量性质是一样的。
例子 * 白噪声
弱平稳
- 均值函数是常数函数
由各平稳的改变,没有趋势,所以任何一点t, X t X_t Xt的期望是常数 - 协方差函数仅与时间差相关
弱平稳没有分布与时间无关的特性,但弱平稳抓住了另一个不变性——相关系数。这说明 X 1 X_1 X1与 X 3 X_3 X3的相关系数, X 2 X_2 X2与 X 4 X_4 X4的相关系数都是一样的,即相关系数取决于时间间隔而非时间起点。
严平稳和弱平稳的区别
- 严平稳指概率分布和联合分布与起点时间选择无关
- 弱平稳指一阶矩和二阶矩与起点时间选择无关
为什么需要平稳性?
我们假设由历史数据 { x 0 , x 1 , x 2 , x 3 } \{x_0, x_1, x_2, x_3\} {x0,x1,x2,x3},一顿操作猛如虎,得到了模型 x i ^ = f ( x i − 1 , x i − 2 ) \hat{x_i}=f(x_{i-1}, x_{i-2}) xi^=f(xi−1,xi−2),即我发现 x 2 ≈ f ( x 1 , x 0 ) x_2 \approx f(x_1, x_0) x2≈f(x1,x0); x 3 ≈ f ( x 2 , x 1 ) x_3 \approx f(x_2, x_1) x3≈f(x2,x1)。所以,我们下面用 f ( x 2 , x 3 ) f(x_2, x_3) f(x2,x3)去预测 x 4 x_4 x4。
当我们要清醒,这样做work的前提是 ( x 0 , x 1 , x 2 ) (x_0, x_1, x_2) (x0,x1,x2)的分布, ( x 1 , x 2 , x 3 ) (x_1, x_2, x_3) (x1,x2,x3)的分布与 ( x 2 , x 3 , x 4 ) (x_2, x_3, x_4) (x2,x3,x4)的分布要一样,如果获取 x 4 x_4 x4后要预测 x 5 x_5 x5,那还需要 ( x 3 , x 4 , x 5 ) (x_3, x_4, x_5) (x3,x4,x5)的分布要一样。如此类推,所以 ( x t − 2 , x t − 1 , x t ) (x_{t-2}, x_{t-1}, x_t) (xt−2,xt−1,xt)要不与t相关。这就是我们所说需要的严平稳
当时严平稳要求太高了,它要求概率分布和联合分布的各阶矩(如果存在)都要与时间无关。而弱平稳,只考察一阶矩(均值期望)以及二阶矩(协方差矩阵)与时间无关。
看看何为平稳图像以及非平稳图像
判断数据是稳定的常基于对于时间是常量的几个统计量:
- 常量的均值
- 常量的方差
- 与时间独立的自协方差
a) 均值

- 左图的数据的均值对于时间轴来说是常量,即数据的均值不是时间的函数,所以它是稳定的;
- 右图随着时间的推移,数据的值整体趋势是增加的,所以均值是时间的函数,数据具有趋势,所以是非稳定的。
b) 方差

- 左图的数据的方差对于时间是常量,即数据的值域围绕着均值上下波动的振幅是固定的,所以左图数据是稳定的。
- 右图的数据的振幅在不同时间点不同,所以方差对于时间不是独立的,数据是非稳定的。
- 但是,左、右图的均值是一致的。
c) 自协方差

一个时序数据的自协方差,就是它在不同两个时刻i,j的值的协方差。
- 左图的自协方差于时间无关
- 右图,随着时间的不同,数据的波动频率明显不同,导致它i,j取值不同,就会得到不同的协方差,因此是非稳定的。
- 虽然右图在均值和方差上都是与时间无关的,但仍是非稳定数据。
平稳性检验
如果序列有明显的趋势或者周期性,那么就不是平稳序列,因为平稳条件是有常数均值和常数方差.检验方法有:
- 绘制滚动统计 :我们可以绘制移动平均数和移动方差,观察它是否随着时间变化。但是,这更多的是一种视觉技术。
- 平稳序列具有短期相关性,这个性质表明对平稳序列而言通常只有近期的序列值对现时值得影响比较明显,间隔越远的过去值对现时值得影响越小。随着延迟期数k的增加,平稳序列的自相关系数会比较快的衰减趋向于零,并在零附近随机波动,而非平稳序列的自相关系数衰减的速度比较慢。
- 单位根检验: 检验序列中是否存在单位根,如果存在则非平稳时间序列。
- DF校验(Dickey-Fuller)
在一定置信水平下,对于时序数据假设 Null hypothesis: 非稳定。if 通过检验值(statistic)< 临界值(critical value),则拒绝null hypothesis,即数据是稳定的;反之则是非稳定的。
下面的例子是不平稳的(统计量均大于(5%, 1%, 10%)的临界值)。

from statsmodels.tsa.stattools import adfuller
- DF校验(Dickey-Fuller)
实现例子(窗口12的滚动统计和DF校验):
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):
#Determing rolling statistics
rolmean = pd.rolling_mean(timeseries, window=12)
rolstd = pd.rolling_std(timeseries, window=12)
#Plot rolling statistics:
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
#Perform Dickey-Fuller test:
print 'Results of Dickey-Fuller Test:'
dftest = adfuller(timeseries, autolag='AIC')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
print dfoutput
单位根检验的理论依据
假设我们是AR(1)模型,即 x t = ϕ x t − 1 + u t x_t=\phi x_{t-1}+u_t xt=ϕxt−1+ut,则可以写出通项公式 x t = ∑ i = 0 ∞ ϕ i u t − i x_t=\sum_{i=0}^{\infty}{{\phi}^iu_{t-i}} xt=∑i=0∞ϕiut−i,所以若 { x t } \{x_t\} {xt}是平稳的,需要 ∣ ϕ ∣ < 1 |\phi|<1 ∣ϕ∣<1。
我们观察一下 ϕ \phi ϕ是怎么来的, ϕ \phi ϕ是 x t = ϕ x t − 1 + u t x_t=\phi x_{t-1}+u_t xt=ϕxt−1+ut对应的特征方程 λ = ϕ \lambda=\phi λ=ϕ的解;也是 1 = ϕ B 1=\phi B 1=ϕB的解的导数(B是滞后算子)。
所以,我们希望我们序列中的根都在单位圆里面。
自相关系数与偏相关系数
- https://www.cnblogs.com/noah0532/p/8449638.html
- https://www.cnblogs.com/noah0532/p/8451375.html
- https://blog.csdn.net/weixin_42382211/article/details/81136787
- https://wenku.baidu.com/view/ec41459759f5f61fb7360b4c2e3f5727a5e924ad.html
模型
模型选择指标
常用有三个信息准则(L是最大似然,k是自由参数个数,n是样本数量),基本都是拟合效果+自由参数个数的惩罚项,这几个信息准则都是越小越好:
- AIC = -2 ln(L) + 2 k
赤池信息量 akaike information criterion - BIC = -2 ln(L) + ln(n)*k
贝叶斯信息量 bayesian information criterion - HQ = -2 ln(L) + ln(ln(n))*k
hannan-quinn criterion
我们通常采用AIC法则。
下面我们介绍的AR模型/MA模型/ARMA模型都是线性模型,他们能用有限的参数刻画时间序列的动态性。注意:线性关系的假定在解决实际问题时时一个比较苛刻的条件。
模型拟合效果
指标
注因为时线性模型,所以用 R 2 R^2 R2和 A R 2 AR^2 AR2都有意义。具体见
作图
我们可能会常常看到下图的情况,预测值只是真实值的平移,说明最好的预测值就是前一个时刻的真实值,这样的模型是失败的,没有挖掘更深层次的联系

AR模型(Auto Regressive model)/自回归模型
AR模型是这样刻画时间序列的:时间序列过去的点( x t − 1 x_{t-1} xt−1, …, x t − p x_{t-p} xt−p)的线性组合+当前的白噪声 u t u_t ut。
注:AR模型特征方程的根需要都在单位圆内,不然得到的AR模型是不平稳的。
AR模型在金融模型中主要是对金融序列过去的表现进行建模,如交易中的动量与均值回归。
下图为AR(q)模型

MA模型(Moving Average model)/移动平均模型
MA模型是这样刻画时间序列的:时间序列过去的白噪声( u t − 1 u_{t-1} ut−1, …, u t − q u_{t-q} ut−q)的线性组合+当前的白噪声 u t u_t ut。
注:MA模型一定是平稳的。
在金融模型中,MA常用来刻画冲击效应,例如预期之外的事件。
下图为MA(q)模型

AR模型与MA模型的联系与区别
联系
由前面的AR(1)模型,即 x t = ϕ x t − 1 + u t x_t=\phi x_{t-1}+u_t xt=ϕxt−1+ut,得到 x t = ∑ i = 0 ∞ ϕ i u t − i x_t=\sum_{i=0}^{\infty}{{\phi}^iu_{t-i}} xt=∑i=0∞ϕiut−i。
我们可以得知,AR(1)本质就是MA( ∞ \infty ∞)。我们进行推广得知:
- 有限阶AR模型等价于无限阶MA模型
- 无限阶AR模型等价于有限阶MA模型
区别
本质的区别
x t = ∑ i = 0 ∞ ϕ i u t − i x_t=\sum_{i=0}^{\infty}{{\phi}^iu_{t-i}} xt=∑i=0∞ϕiut−i
- In the MA model a shock affects X values only for the current period and q periods into the future; in contrast, in the AR model a shock affects X values infinitely far into the future, because u t u_t ut affects X t X_{t} Xt, which affects X t + 1 X_{{t+1}} Xt+1, which affects X t + 2 X_{{t+2}} Xt+2, and so on forever. (MA模型中过去扰动对当前值的影响截断的)
- In the MA model shocks are propagated to future values of the time series directly: for example, u t − 1 {u_{t-1}} ut−1 appears directly on the right side of the equation for X t X_{t} Xt. In contrast, in an AR model u t − 1 u _{{t-1}} ut−1 does not appear on the right side of the X t X_{t} Xt equation, but it does appear on the right side of the X t − 1 X_{{t-1}} Xt−1 equation, and X t − 1 X_{{t-1}} Xt−1 appears on the right side of the X t X_{t} Xt equation, giving only an indirect effect of u t − 1 u _{t-1} ut−1 on X t X_{t} Xt.(MA模型中过去扰动与当前值的影响是直接的)
统计现象的区别
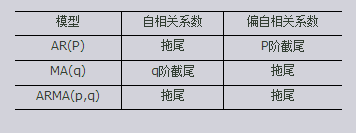
典型的AR(1)
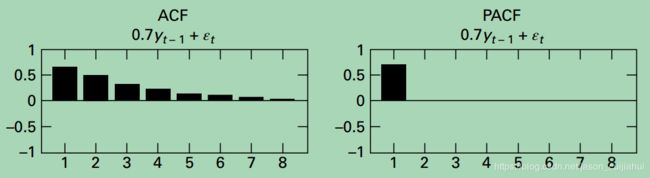
典型的MA(1)

典型的ARMA(1, 1)模型
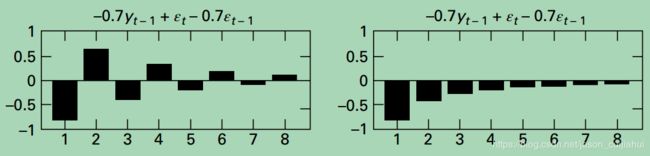
ARMA模型(Auto Regressive and Moving Average model)/自回归移动平均模型
Given a time series of data Xt , the ARMA model is a tool for understanding and, perhaps, predicting future values in this series. The AR part involves regressing the variable on its own lagged (i.e., past) values. The MA part involves modeling the error term as a linear combination of error terms occurring contemporaneously and at various times in the past.
注:因为MA模型一定是平稳的,所以ARMA模型的平稳性取决于AR模型
下图为ARMA(p, q)模型

为什么要ARMA模型?
因为,我们由上面可以知道,AR模型和MA模型是等价的,但是如果用MA模型去刻画AR模型,需要无限阶(即无限的参数);用AR模型去刻画MA模型,需要无限阶(即无限的参数)。而AR模型和MA模型结合的ARMA模型去刻画时间序列,需要远小于用AR/MA模型的参数。
细想一下,如果单用AR,时间序列有一点点MA特性,就要用无穷的参数才能准确地描述;而单用MA也是这样。
ARMA(p, q)中的p, q怎么选定
最常用的技术是采用循环在p和q各自0到5(或者更大)的范围内搜索最小AIC或BIC的(p,q)组合。
ARIMA模型/差分自回归移动平均模型
ARIMA模型是在ARMA模型的基础上解决非平稳序列的模型,因此在模型中会对原序列进行差分,直至差分后的序列为平稳序列。
为什么要差分?
由 Cramer 分解定理知 : 时间序列 = 确定性影响 + 随机性影响。
确定性影响又可以由多项式决定 , 而对n阶多项式求 n 次差分 , 即能变成常数。(思考:如果确定性影响不能通过多项式表示则如何?答:对原数据进行处理后差分)
然而差分的过程中会丢失信息,如 a x 2 + b x + c ax^2+bx+c ax2+bx+c经过2次差分只剩下信息 2 a 2a 2a。
因此,我们是要经过最少次的差分得到平稳序列。
SARIMA模型
通常时间序列包括3个因素:
- 趋势因素T
- 季节性因素S
- 不规则因素I(用ARIMA去分析建模)
而这3个因素由3种组合成时间序列:
- 加法模型 x t = T t + S t + I t x_t = T_t+S_t+I_t xt=Tt+St+It
- 乘法模型 x t = T t + S t + I t x_t = T_t+S_t+I_t xt=Tt+St+It
- 混合模型 x t = S t ∗ T t + I t x_t=S_t*T_t+I_t xt=St∗Tt+It或 x t = S t ∗ ( T t + I t ) x_t=S_t*(T_t+I_t) xt=St∗(Tt+It)
混合类型该怎么处理:https://wenku.baidu.com/view/641e9517ce84b9d528ea81c758f5f61fb7362833.html
因素分解的方法
方法1:移动平均
若是加法模型 x t = T t + S t + I t x_t = T_t+S_t+I_t xt=Tt+St+It
- 移动平均(观察周期设置window,window通过傅里叶分析获得)获得 T t + I t T_t+I_t Tt+It部分
- x t − ( T t + I t ) x_t-(T_t+I_t) xt−(Tt+It)部分得到周期部分 S t S_t St
- 拟合T_t+I_t部分的趋势得到 I t I_t It部分(拟合残差)和 T t T_t Tt趋势部分
- 对 I t I_t It部分用ARIMA
#Determing rolling statistics
rolmean = pd.rolling_mean(timeseries, window=12)
rolstd = pd.rolling_std(timeseries, window=12)
#Plot rolling statistics:
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
方法2:利用sm.tsa.seasonal_decompose进行分解
sm.tsa.seasonal_decompose可以直接将时间序列分解为趋势,季节和残差,并有加法模型和乘法模型两种模式可选。
分解算法的本质:
- https://wenku.baidu.com/view/53f995d7770bf78a6429540f.html
- https://wenku.baidu.com/view/89faee1980eb6294dc886cb6.html?rec_flag=default&sxts=1550502299475
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(ts_log)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
plt.subplot(411)
plt.plot(ts_log, label='Original')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(trend, label='Trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(seasonal,label='Seasonality')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(residual, label='Residuals')
plt.legend(loc='best')
plt.tight_layout()
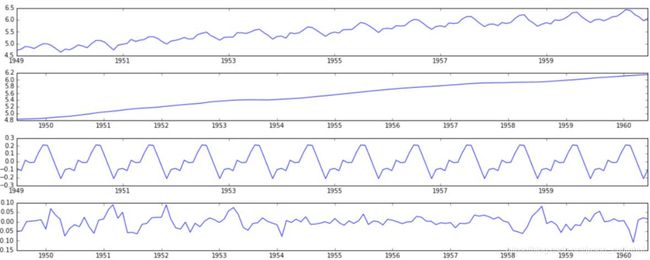
https://blog.csdn.net/mengjizhiyou/article/details/82683448
http://shenhaolaoshi.blog.sohu.com/137715309.html
https://www.jianshu.com/p/221c86e1a56b
https://www.cnblogs.com/xuanlvshu/p/5447695.html
https://wenku.baidu.com/view/97301f2aaeaad1f347933fa2.html
https://www.jianshu.com/p/cced6617b423
https://blog.csdn.net/u014096903/article/details/79980036
https://blog.csdn.net/recoba2k1/article/details/73656074
对于金融时间序列,由于其具有volatility clustering的特性,时间序列的波动率(二阶矩)并不是一个不变的常数,AR、MA和ARMA模型是无法刻画这种条件异方差的特性,ARCH和GARCH模型可以解决这一问题
ARCH
GARACH
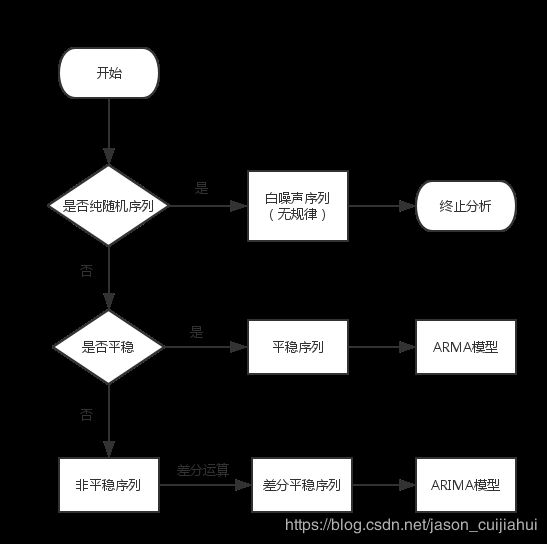
建模整体流程
注:白噪声序列是没有信息可提取的平稳序列,没有进行序列分析的必要。
工具
- Python包
实战样例
- https://blog.csdn.net/yeshang_lady/article/details/80888963
- https://www.jianshu.com/p/5c5a6293640a
- https://www.jianshu.com/p/4130bac8ebec
- http://www.cnblogs.com/bradleon/p/6832867.html
- https://blog.csdn.net/luyao_cxy/article/details/82250857
- https://www.zhihu.com/question/45118664/answer/200476042
- https://www.cnblogs.com/foley/p/5582358.html
教程
- http://www.statsmodels.org/stable/examples/index.html#regression
- http://faculty.chicagobooth.edu/ruey.tsay/teaching/mts/sp2015/
- Facebook Prophet
参考
- https://zhuanlan.zhihu.com/QuantAlchemist