中文版链接:https://dataminingguide.books.yourtion.com/
源码链接: https://github.com/yourtion/DataminingGuideBook-Codes
像读一本小说一样。
一本很好的数据挖掘入门书和python入门书,如果代码写得差数学也不好也看得下去。
整本书都是小案例,边看边demo比较好。
Part I 协同过滤
协同过滤是什么?
比如我想推荐一本书给你,我会在网站上搜索与你兴趣类似的其他用户,看看这个用户喜欢什么书然后把它们推荐给你。
如何寻找相似用户?
根据用户A和B有共同评价的书的评分计算距离:

如何解决用户的评级差异问题?
皮尔森相关系数

但A和B有共同评价的书可能很少(数据稀疏),余弦相似度可以忽略这样的0-0匹配:
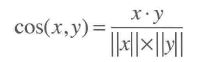
仅依赖于最相近的用户推荐有时候是片面的,基于多个相似用户的推荐可能更好。比如K近邻算法。
隐式评级
除了用户给出评级(显式评级)之外,观察用户行为也是获得结果的方法:比如跟踪用户在纽约时报在线的点击轨迹。
到目前为止都是基于用户的过滤,但有两个问题:1 、扩展性(用户数量会变多);2、稀疏性。
因此最好采用基于物品的过滤,计算出最相近的两件物品。
同样用余弦相似度计算两个物品的相似度(为抵消分数夸大的情况,我们从每个评级结果中减掉平均评分):

Slope one 算法
(1)计算所有物品对的偏差

(2)利用加权偏差进行预测

Part II 内容过滤和分类
内容过滤不同于协同过滤,它是基于物品属性的过滤。
选定某些特征,给出物品各项特征得分,其他和第一部分计算相似。
Part III 算法评估和KNN
(1)算法评估
n折交叉验证(留一法):测试集和训练集的划分可能会导致准确率无法反应实际分类器的精确程度。若把数据集分为N份,使用其中n-1份进行训练,剩下一份测试,重复10次做平均。(计算机开销比较大,适合小数据集)
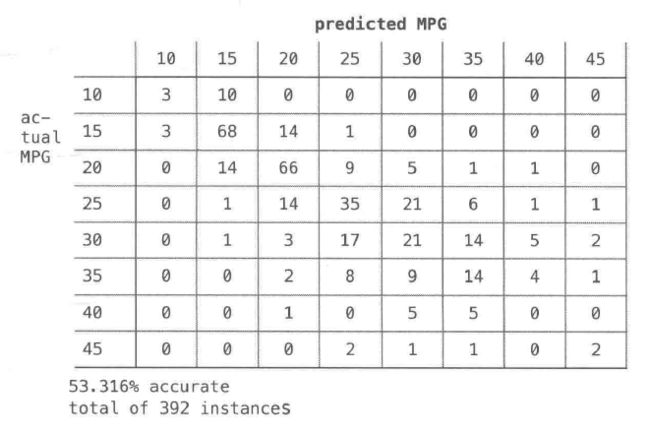
混淆矩阵:可视化输出结果
Kappa统计量


(2)kNN(选取最近的k个点投票)
Brill:更多训练数据比算法改进带来的准确率提高更多。
Part IV 概率和朴素贝叶斯
(1)朴素贝叶斯简介
近邻方法:lazy learner (每次都要遍历整个训练数据)
贝叶斯方法:eager learner(给定数据集立刻进行数据分析和模型构建)
P(h)即某个假设h为真的概率称为h的先验概率。
P(h|d)即观察到数据d之后h的概率称为后验概率。

朴素贝叶斯(假设相互独立)
P(A|B,C,D)=P(A)P(B|A)P(C|A)P(D|A)
概率估计(防止nc为0)

数据类型
贝叶斯方法用categorical data,区间内的值计数问题可以用如下解决:
方法一:构建类别

方法二:高斯分布

(2)朴素贝叶斯及文本-非结构化文本分类
Part V 聚类--群组发现
kmeans聚类
层次聚类

其他:
- heapq模块 http://blog.csdn.net/marksinoberg/article/details/52734332
*assert
assert语句:用以检查某一条件是否为True,若该条件为False则会给出一个AssertionError。
用法:assert type(x)=int and x>=0
如果不满足后面的expression,则会弹出
Traceback (most recent call last):
File "
assert type(n)==int and n>0
AssertionError