爬虫实战之《流浪地球》豆瓣影评分析(三)
4. 分析评论数量及评分与时间的关系
首先导入数据,进行一个初步的统计:
import pandas as pd
data = pd.read_csv('doubanliulangdiqiu.csv',encoding ='GB18030')
data['评分'].value_counts()
可以看到这样的情况:

如果没有数据,可以去看爬虫实战之《流浪地球》豆瓣影评分析(一)的爬取过程。
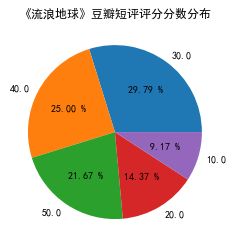
先做一个饼图来分析分布情况,先把评分的值计算命名为num,然后设置字体,绘制饼图,设置小数点的位数,还有给一个标题:
import matplotlib.pyplot as plt
num = data['评分'].value_counts()
plt.rcParams['font.sans-serif'] = "Simhei"
plt.pie(num, autopct="%.2f %%",labels=num.index)
plt.title('《流浪地球》豆瓣短评评分分数分布')
最后是结果:
短评数量与日期的关系
因为之前爬取数据的时候,把时分秒也爬了下来,而这次只需要日期,所以要选择一下。然后用日期排序:
num = data['发表时间'].apply(lambda x: x.split(" ")[0]).value_counts()
num = num.sort_index() # 日期排序
plt.plot(range(len(num)),num) # 刻度与num的长度一致
plt.xticks(range(len(num)),num.index,rotation=90)
plt.grid() # 添加网格背景
最后效果:
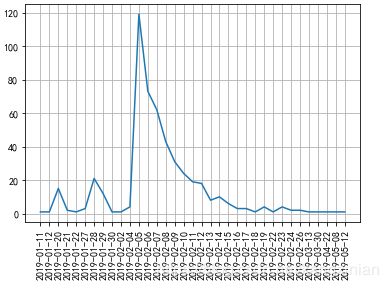
因为只有500条数据,可以看懂,2月五号上映的时候到了一个峰值。
短评数量与时刻的关系
前面是日期,这次就是时刻了:
num = pd.to_datetime(data['发表时间']).apply(lambda x: x.hour).value_counts() # 首先转换成时间格式,然后转换成小
num = num.sort_index()
plt.plot(range(len(num)),num) # 刻度与num的长度一致
plt.xticks(range(len(num)),num.index)
plt.title("评论数量随时刻的变化情况")
plt.grid() # 添加网格背景
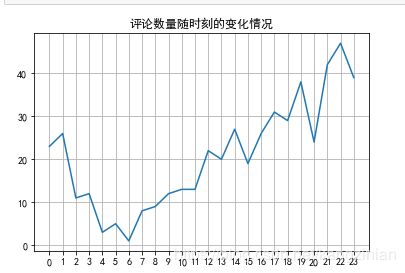
可以看出来,凌晨基本没人,晚上是高峰期,可以看出来大部分人是夜猫子
不同评分数量与时间的关系
首先需要进行去重操作,以发表时间为例:data['发表时间'].drop_duplicates().sort_values()。时间也处理一下data["发表时间"] = data["发表时间"].apply(lambda x: x.split(' ')[0])
然后建立一个空表格,然后进行数据填充,最后指标:
在这里插入代码片data["发表时间"] = data["发表时间"].apply(lambda x: x.split(' ')[0])
tmp = pd.DataFrame(0,
index=data['发表时间'].drop_duplicates().sort_values(),# 去重
columns=data['评分'].drop_duplicates().sort_values())
for i,j in zip(data['发表时间'],data["评分"]):
tmp.loc[i, j] +=1
tmp = tmp.iloc[:,:-1]
n,m= tmp.shape
plt.figure(figsize=(10,5))
plt.rcParams['axes.unicode_minus']=False
for i in range(m):
plt.plot(range(n),(-1 if i<2 else 1)*tmp.iloc[:,i])#绘制图
plt.fill_between(range(n),(-1 if i<2 else 1)*tmp.iloc[:,i],alpha=0.5)
plt.grid()
plt.legend(tmp.columns) # 图例
plt.xticks(range(n),tmp.index,rotation=45) # 横轴左闭
plt.show()
最后的效果图:

分析一下趋势:
- 在点映期间,对电影的大部分评价都是正面的,但是上映之后两级分化。
- 一星评价中,在2019-02-10有一个小高峰,当天是星期一,好评低,可能是刷负分的评价
但是这是500条数据,不能代表所有!!!
5. 分析评论者的城市分布情况
还是一样,先导入数据,然后数据处理,最后绘制条形图:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("doubanliulangdiqiu.csv",encoding='GB18030')
num = data['居住城市'].value_counts()[:10]
plt.rcParams['font.sans-serif'] = "Simhei"
plt.bar(range(10),num)
plt.xticks(range(10),num.index,rotation=45)
plt.title('平均价数量最多的前十个城市')
for i,j in enumerate(num):
plt.text(i,j,j, ha = 'center',va='bottom')
plt.show()
看一下效果:
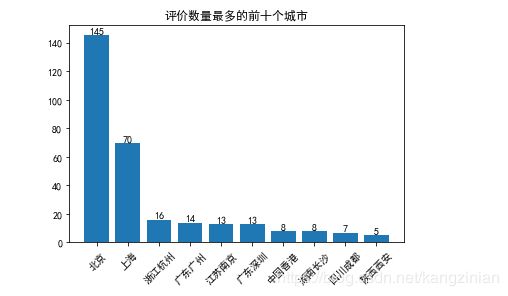
得出了评价数最多的十个城市后。就开始整理数据,一样,先构建一个空表格,然后再统计导入数据
tmp = pd.DataFrame(0,
index= data['评分'].drop_duplicates().sort_values(),
columns=data['居住城市'].drop_duplicates())
for i ,j in zip(data['评分'],data['居住城市']):
tmp.loc[i,j] += 1
但是城市太多了,就取前五个城市吧
cities = num.index[:5] # 取前五个城市
tmp=tmp.loc[:,cities] # 选取评论数前五的城市
tmp = tmp.iloc[:5,:]# 去除NAN
效果:
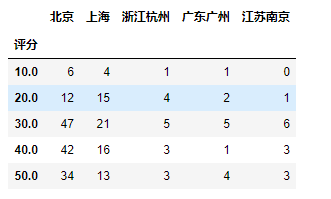
然后就是跟上面差不多的代码,稍微改一下:
n,m= tmp.shape
plt.figure(figsize=(10,5))
plt.rcParams['axes.unicode_minus']=False
for i in range(m):
plt.plot(range(n),tmp.iloc[:,i])#绘制图
plt.fill_between(range(n),tmp.iloc[:,i],alpha=0.5)
plt.grid()
plt.title("评论评分与城市的关系")
plt.legend(tmp.columns) # 图例
plt.xticks(range(n),tmp.index,rotation=45) # 横轴左闭
plt.show()
效果:
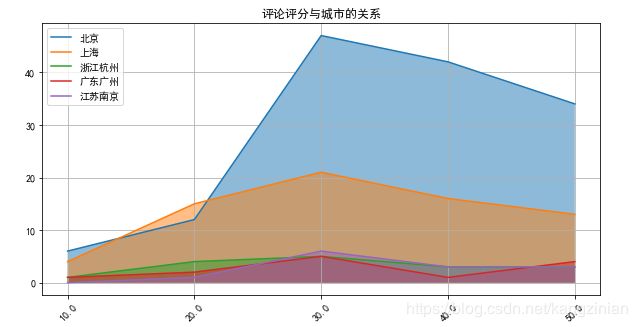
总结:
- 从好评与差评的关键信息展示上可以看得出该影片是中国难得的科幻类型的影片,讲述了人类带着地球流浪的事情,好评主要因为特效和爱国,差评主要因为剧情生硬。
- 从日期上面去进行评论数量分布统计发现评论数量最多的在上映后一周内。点映时评论较好,但是上映后口碑两极分化。
- 北京上海的用户发表短评最多,常住北京的用户好评居多,上海的用户倾向给差评。
谢谢大家,喜欢就点个赞吧