评分卡模型开发-定量指标筛选
模型开发的前三步主要讲的是数据处理的方法,从第四步开始我们将逐步讲述模型开发的方法。在进行模型开发时,并非我们收集的每个指标都会用作模型开发,而是需要从收集的所有指标中筛选出对违约状态影响最大的指标,作为入模指标来开发模型。接下来,我们将分别介绍定量指标和定性指标的筛选方法。
library(InformationValue)
library(klaR)
data(GermanCredit)
train_kfold<-sample(nrow(GermanCredit),800,replace=F)
train_kfolddata<-GermanCredit[train_kfold,]
test_kfolddata<-GermanCredit[-train_kfold,]
#将违约样本用“1”表示,正常样本用“0”表示。
credit_risk<-ifelse(train_kfolddata[,"credit_risk"]=="good",0,1)
tmp<-train_kfolddata[,-21]
data<-cbind(tmp,credit_risk)
#获取定量指标
quant_vars<-c("duration","amount","installment_rate","present_residence","age",
"number_credits","people_liable","credit_risk")
quant_GermanCredit<-data[,quant_vars] #提取定量指标(1)第一种定量指标的筛选方法:用随机森林法寻找自变量中对违约状态影响最显著的指标,代码如下:
#第一种方法:随机森林法
library(party)
cf1<-cforest(credit_risk~.,data = quant_GermanCredit,
controls = cforest_unbiased(mtry=2,ntree=50))
varimp(cf1)
#基于变量均值的精度下降,获取自变量的重要性
#mtry代表在每一棵树的每个节点处随机抽取mtry 个特征,通过计算每个特征蕴含的信息量,特征中选择一个最具有分类能力的特征进行节点分裂。
#varimp代表重要性函数。
varimp(cf1,conditional = TRUE)
#经过变量间的相关系数调整后,获取自变量的重要性
varimpAUC(cf1)
#经过变量间的不平衡性调整后,获取自变量的重要性
(2)第二种定量指标的筛选方法:计算变量间的相对重要性,并通过相对重要性的排序,获取自变量中对违约状态影响最显著的指标,代码如下:
#第二种方法:计算变量间的相对重要性,回归法
library(relaimpo)
lmMod<-lm(credit_risk~.,data = quant_GermanCredit) #线性回归
relImportance<-calc.relimp(lmMod,type = "lmg",rela = TRUE)
#计算自变量间的相对重要性
sort(relImportance$lmg,decreasing = TRUE)
#排序并输出自变量间的相对重要性
(3)第三种定量指标的筛选方法:通过自变量间的广义交叉验证法,获取自变量中对违约状态影响最显著的指标,代码如下:
#第三种方法:自变量间的广义交叉验证法
library(earth)
marsModel<-earth(credit_risk~.,data = quant_GermanCredit)
ev<-evimp(marsModel)
ev
#经过自变量间的广义交叉验证后,获取自变量的重要性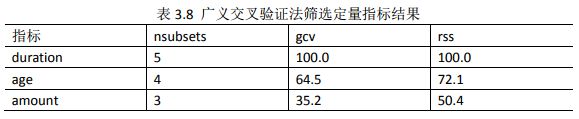
(4)第四种定量指标的筛选方法:通过自变量的逐步回归法,获取自变量中对违约状态影响最显著的指标,代码如下:
#第四种方法:自变量的逐步回归法
base.mod<-lm(credit_risk~1,data = quant_GermanCredit)
#获取线性回归模型的截距
all.mod<-lm(credit_risk~.,data = quant_GermanCredit)
#获取完整的线性回归模型
stepMod<-step(base.mod,scope = list(lower=base.mod,upper=all.mod),
direction = "both",trace = 0,steps = 1000)
#采用双向逐步回归法,筛选变量
shortlistedVars<-names(unlist(stepMod[[1]]))
#获取逐步回归得到的变量列表
shortlistedVars<-shortlistedVars[!shortlistedVars %in%"(Intercept)"]
#删除逐步回归的截距
print(shortlistedVars)
#输出逐步回归后得到的变量
(5)第五种定量指标的筛选方法:采用“Boruta”法,获取自变量中对违约状态影响最显著的指标,代码如下:
#第五种方法:"Boruta"法
library(Boruta)
boruta_output<-Boruta(credit_risk~.,data = na.omit(quant_GermanCredit),
doTrace=2)
boruta_signif<-names(boruta_output$finalDecision[
boruta_output$finalDecision %in%c("Confirmed","Tentative")])
#获取自变量中确定的和实验性的指标
print(boruta_signif)
#Levels: Tentative Confirmed Rejected
#Confirmed坚定的;Tentative踌躇的;Rejected拒绝的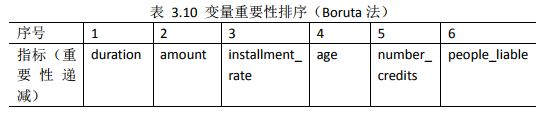
plot(boruta_output,cex.axis=.7,las=2,xlab="",main="Variable Importance")
#绘制变量显著性表示的箱图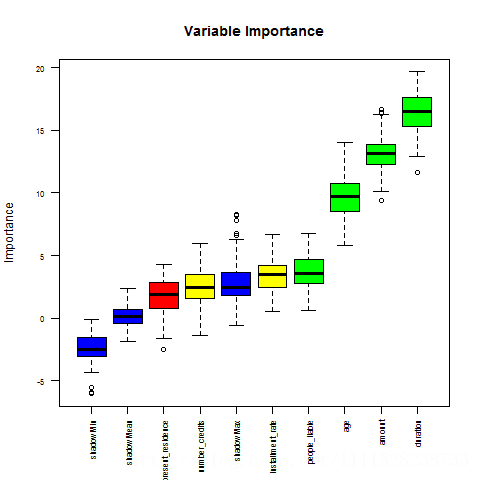
图3.9 箱图表示变量重要性(Boruta法)
综上,我们共计详细使用了五种定量指标入模的方法,在实际的模型开发过程中,我们可以只选择其中一种方法,也可以结合多种方法,来筛选出定量数据的入模指标。综合这五种方法,我们筛选出了对违约状态影响最显著的四个入模指标,如表3.11所示。

定性指标筛选见下篇:
http://blog.csdn.net/lll1528238733/article/details/76600147