《深入分析JavaWeb技术内幕》之读书笔记(篇一)
CDN
1.1 架构图
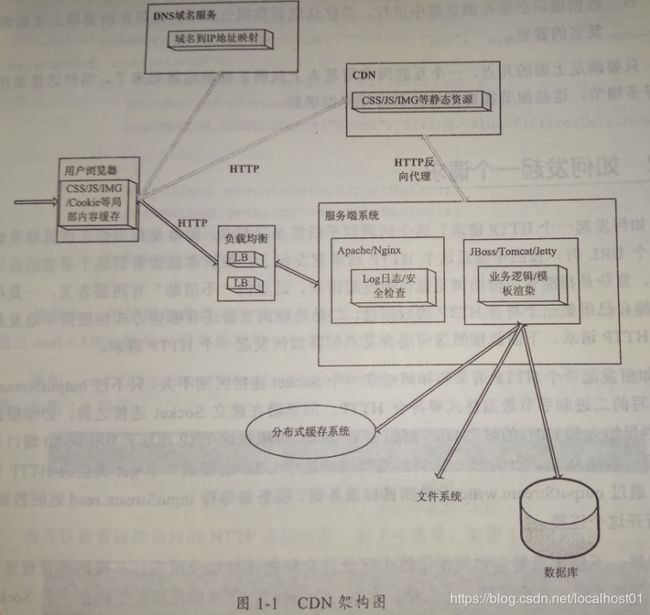
1.2 工作机制
一般架构:如张三在阿里云买了一个域名(如www.test.com),然后配置CNAME记录到另一个域名/或A记录到一个IP,该域名/IP将最终指向CDN全局的DNS负载均衡服务器(GTM),然后由它来负责分配离该用户最近的CND节点。
CDN动态加速:简单原则即每个CDN节点上从源站下属在一个一定大小的文件,看哪个链路的总耗时最短,这样可以构成以个链路列表,然后绑定到DNS解析上,并更新到 Local DNS Server。
浏览器缓存
2.1 Cache-Control/Pragma
强制请求最新数据(而非缓存)的快捷键:Ctrl+F5
代码:Pragma:no-cache、Cache-Control:no-cache代码:Pragma:no-cache、Cache-Control:no-cache
Cache-Control优先级较高,与Expires(缓存时间)等同时出现时,会覆盖这些字段;
Cache-Control和Pragma:no-cache作用一致。
可选值有:
| 值 | 说明 |
|---|---|
| Public | 所有内容都被缓存,在响应头中设置 |
| Private | 内容只缓存到私有缓存中,在响应头中设置 |
| no-cache | 所有内容不缓存,在请求头和响应头中都可设置 |
| no-store | 所有内容都不会被缓存或internet临时文件中,在响应头中设置 |
| must-revalidation/proxy-revalidation | 如果缓存失效,请求必须发送到服务器/代理以进行重新验证,在请求头中设置 |
| max-age | 缓存内容在xxx秒后失效,这个选项只在HTTP1.1可用,和Last-Modified一起使用时优先级更高,在响应头中设置 |
2.2 Expires
设置缓存过期时间,格式为Expires:Sat,25 Feb 2012 12:22:17 GMT,超过这个时间后,缓存将失效,浏览器在发出请求之前会检查这个页面的这个字段,如果页面过期则重新请求。
2.3 Last-Modified/Etag
-
Last-Modified:文件最后修改时间,用于判断当前文件是否是最新的。(Sevlet提供getLastModified方法用于检查某个动态内容是否已更新)
服务端在响应头返回一个
Last-Modified:时间,告诉浏览器这个页面最后修改时间,浏览器每次请求时跟上If-Modified-Since:时间来询问服务器当前页面是否是最新的,若是,返回304状态码。 -
Etag:文件编码版本,给每个页面分配唯一的一个编号,通过编号来区分页面是否是最新的,比Last-Modified更灵活,但是对于集群环境,需要每个web服务器都记住所有页面编号,否则将失去意义。
DNS
3.1 解析步骤(顺序)
- 寻找浏览器缓存中是否有该域名对应解析过的IP地址
- 寻找操作系统上是否有该域名的解析结果(windows的
c://windows/system32/ddrivers/etc/hosts和linux的/etc/hosts,黑客若修改该文件,域名解析到他的恶意ip地址上去,即导致域名劫持) - 寻找Local DNS Server(本地域名服务器),这个服务器一般离你比较近的某个角落,如学校网,这个服务器肯定在你学校,小区网,这个服务器就是电信或联通(SPA),可通过
ipconfig查看其服务器IP(linux通过cat /etc/resolve.conf查看)。这里一般可以完成80%的域名解析。 - 网络上进行解析(♥如请求www.school.org):
- Local DNS Server先请求Root DNS Server(根域名服务器,♥此处即请求
.域名服务器),它将返回一个查询域的主域名服务器(gTLD Server,国际顶级域名服务器,如:.com、.cn、.org等,♥此处将返回一个.org域名服务器) - Local DNS Server再请求
.org域名服务器,并返回此域名对应的Name Server域名服务器地址(即注册的域名服务器,如阿里云、腾讯云,♥此处即school.org域名服务器) - Local DNS Server最后请求
school.org域名服务器,便会查找存储的域名和IP映射表,连同一个TTL值一起返回给本地域名服务器,最后这个域名和IP将在本地域名服务器缓存,缓存时间即是TTL,这个值可在云域名管理平台自由设置。 - 最后Local DNS Server将结果返回给用户,用户也根据TTL缓存到本地系统缓存中。
- Local DNS Server先请求Root DNS Server(根域名服务器,♥此处即请求
- JVM 缓存DNS(InetAdress类),分别支持缓存正确结果和缓存失败结果。
%JAVA_HOME%\lib\security\java.security文件配置缓存时间,默认是-1(永不失效)和10(缓存10秒)。
附:
nslookup 域名 #查看域名解析结果,Linux和Windows都可使用
dig 域名 ##查看域名解析过程,Linux可用
ipconfig /flushdns #清除缓存,Windows可用
/etc/init.d/nscd restart #清除缓存,Linux可用
3.2 域名解析方式
- A记录:即域名对应一个IP,当然可以多个域名指向同一个IP,但不能一个域名指向多个IP。
- CNAME记录:即一个域名解析到另一个域名,另一个域名可能指向一个IP或其他。
- MX记录:为域名设置邮件路由,如可配置qq.com的MX记录指向1.1.1.1,那么类似[email protected]的邮件将发往1.1.1.1服务器,而正常的web请求仍然是访问qq.com对应的A记录。
- NS记录,为域名指定DNS解析服务器
- TXT记录,为域名或主机名设置说明,如localhsot01.cn可设置TXT记录为“冉椿林的博客|xxx”。
Java IO
4.1 磁盘IO工作机制
4.1.1 非Java的几种访问文件的方式
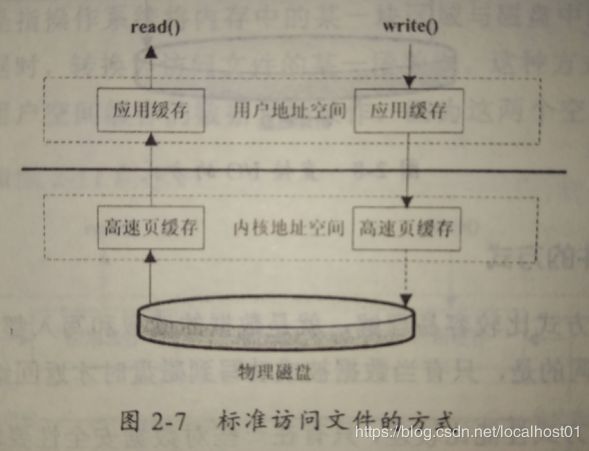
-
标准访问文件方式
应用程序调用read()接口时,操作系统检查在内核的高速缓存中是否有需要的数据,如有,则直接从缓存中返回,若没有,则从磁盘中读取,并缓存到操作系统的缓存中。应用程序调用write()接口将数据从用户地址空间复制到内核地址空间的缓存中,这是对于用户应用程序来说,写操作就已经完成了至于什么时候再写入到磁盘中,由操作系统决定,除非调用sync同步命令(
java中是FileDescriptor.sync())。
-
直接IO方式
即应用程序直接访问磁盘数据,不经过操作系统内核数据缓冲区。目的是为了减少一次从内核缓冲区到用户程序缓存的数据复制。常用实现通常在有应用程序实现的数据库管理系统中。这样系统可明确知道需要缓存哪些数据,并对数据进行预加载。缺点是如果访问的数据不在应用程序缓存中,会直接到磁盘进行加载,导致速度非常慢。所以通常会与异步IO配合使用,以得到较好的性能。

-
同步访问文件方式
与标准访问方式差不多,不过数据的读写都是同步操作,只有当数据被成功写入到磁盘才会返回成功给应用程序。缺点是性能较差,一般只会在对数据安全行要求比较高时使用,且通常这种操作方式的硬件都是定制的。 -
异步访问文件方式
当访问线程发出请求之后,线程会接着去处理其它事情,而不是阻塞等待,当请求的数据返回之后继续处理下面的操作。这种访问方式可以明显提高应用程序的效率,但不会改变访问文件的效率。 -
内存映射方式
操作系统将内存中的某一块区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据。目的也是为了减少数据从内核空间缓存到用户缓存的数据复制操作。
4.1.2 Java访问磁盘文件
java中通常的File并不代表一个真实存在的文件对象,它可能表示代表这个路径的虚拟对象,又或是包含多个文件的目录。而在创建FileInputStream对象时,会创建FileDescriptor对象(文件描述符对象),这个对象才真正表示一个存在的文件描述。可通过getFD()方法来获取它,并且可通过FileDescriptor.sync()方法来将操作系统缓存中的数据强制刷新到磁盘中。
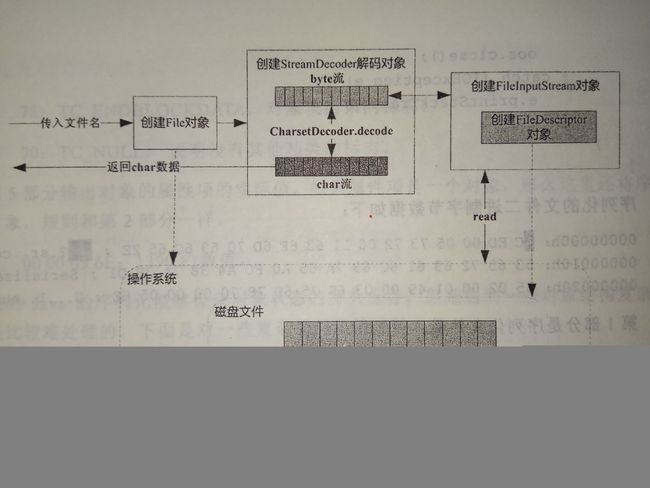
读取文本字符文件流程:
当传入一个文件路径,会根据这个路径创建一个File对象来标识这个文件
然后根据File对象创建真正读取文件的操作对象,这时将会创建与真实磁盘文件相关联的文件描述符(FileDescriptor),通过这个对象可以直接控制磁盘文件。
由于我们要读取字符格式,因此需要StreamDecoder类将byte解码为char格式。至于如何从磁盘驱动器读取一段数据,操作系统会帮我们完成。
注意:
- InputStreamReader类是将字节转换为字符的桥梁,并指定编码字符集,否则将采用操作系统默认字符集,可能出现乱码。而StreamDecoder正是完成从字节到字符解码的实现类,相应的编码实现类即是StreamEncoder。
- Java IO面向字节的InputStream/OutPutStream,读取和写入都是使用byte[]数组,相应的,面向字符的Reader/Writer,读写使用char[]数组。
4.1.3 Java序列化
即将一个对象转换为一串二进制表示的字节数组。反序列化时,需要提供原始类作为模版才能进行还原,从这个过程可以猜测,序列化的数据并不像class文件那样保存类的完整结构信息。
注意:
- 当父类继承Serializable接口,所有子类都可以被序列化;
- 子类实现了Serializable接口,父类没有,父类属性将不能序列化(不报错,数据丢失),子类属性仍可以正确序列化;
- 序列化的对象属性时,如果该对象没有实现Serializable接口,则会报错;
- 反序列化时,如果SerialVersionUID被修改,反序列化会报错;
- 反序列化时,如果对象属性有修改或删减,分两种情况,一是SerialVersionUID设置过,则修改的部分属性会丢失,但不报错,二是SerialVersionUID未设置(默认会根据类属性和方法自动计算生成),由于修改了属性,导致默认生成的SerialVersionUID与序列化文件的不一致而报错。
4.2 网络IO工作机制
4.2.1 Java Socket工作机制
客户端创建Socket实例(包含本地地址、远程地址、端口号),创建完成前和服务器进行三次握手,成功后Socket实例创建完成,否则抛出IOException。
服务器对应创建ServerSocket(包含未使用的本地端口号、监听的地址[默认*,表所有地址]),然后`accept()`进入监听阻塞,当客户端的socket连接过来,服务器创建相应的Socket(请求源地址、端口),并关联到ServerSocket的未完成连接列表中,当三次握手成功后,移动到完成连接列表中
此时服务器和客户端都有一个socket对象,即通道的两个末端,每个socket都有inputStream和outputStream对象,通过这两个对象来交换数据。操作系统会为这两个对象分配一定大小的缓存去,数据的写入和读取都是通过这个缓存区完成。
写入端将数据写入OutputStream对应的SendQ队列,当队列填满,数据发送到另一端的RecvQ队列,如果RecvQ满了,写入端的write方法将被阻塞,直到RecvQ有足够空间。
因此数据的传输效率主要受以上缓存区大小、写入端速度和读取端速度影响。当然,排除了带宽这些因素。
4.2.2 NIO工作机制
-
出现背景
NIO的出现,主要是为了解决BIO的阻塞问题,提供系统吞吐,以上看到,因为BIO数据的读写都可能出现阻塞,此时线程会失去CPU的使用权进入等待。当然也有改善办法,即使用多线程,每个线程管理一个socket连接,这个只是单个socket线程等待,其他线程继续工作,不影响。或直接换用线程池,减少线程的创建和回收成本。但是,也仍然有些需求无法得到解决,如游戏、Web旺旺,他们需要大量的TCP/HTTP长连接,服务器不能创建这么多的线程来保持连接,当然其他需求还有很多。
-
实现方式
-
多路复用选择器(Selector):它可以用来监听一组通信信道,包括ServerSocketChannel和SocketChannel,前提是它先要注册到这些通信信道上去(并标明需要关注的事件)。
-
ServerSocketChannel:服务器Channel,它是一个通信信道,主要负责监听连接请求。通过
severSocketChannel.register(selector,SelectionKey.OP_ACCEPT)语句即实现把多路复用选择器注册到ServerSocketChannel信道上,并标明关注“连接请求”事件。 -
SocketChannel:具体的通信信道,每个信道关联着一个客户端,通过
socketChannel.register(selector,SelectionKey.OP_READ)语句即实现把多路复用选择器注册到该信道上,并标明关注“读数据”事件。
最后,循环读取多路复用选择器:是否有信道出现了关注的事件发生,没有则阻塞等待或超时返回0,有则通过
selector.selectedKeys取出这些信道,并分别判断是哪个事件发生了,不同事件做不同处理(连接请求事件发生了就把产生的信道继续注册到多路复用选择器上;读数据事件发生了就进行数据读取)。当然实际应用中,会把负责监听连接和处理请求分两个线程来进行分工,前者以阻塞方式执行,后者处理线程才算是真正的NIO(示例如tomcat和jetty)。
这样,一个线程即可处理许多的连接,比之BIO的使用多线程或线程池为每个请求分配一个线程,进行了改进,值得注意的是,如果每个连接处理的事情时间花销较长,或多为IO操作,也可考虑使用适当多的线程来替代这里的单线程。 -
-
数据访问方式
-
FileChannel.transferFrom/FileChannel.transferTo
与传统的数据访问方式相比,可减少从内核到用户空间的数据复制,它是数据直接在内核空间进行移动。

-
FileChannel.map(内存映射访问文件,处理大文件时是一个比较理想的高效率手段)
-
DirectByteBuffer(直接IO访问文件,通过
byteBuffer.allocateDirect(capacity)在DirectMemory上进行分配)
-
-
IO中的设计模式
- 适配器模式
将一个接口/类适配到另一个接口/类。一般做法是继承自源类,实现目标类,或继承自目标类,引入源类实例
典型地方就存在于字节流的inputstream/outputstream到字符流的reader/writer的转换类(桥梁)-**InputstreamReader和OutputStreamWriter**,它们分别继承自Reader/Writer抽象类(目标类),构造方法引入inputStream/outputStream实例。
- 装饰器模式
赋予被装饰的类更多的功能。一般做法是引入被装饰类实例
典型地方就是类如FilterInputSream的实现,它对inputstream进行了升级,使得inputstream具有DataInputSream、BufferedInputStream这些子类:

DataInputSream:**是让只能读取字节的inputStream支持读取Java基本类型和String类型**;
BufferedInputStream:**让没有缓冲区的InputStream支持缓冲方式读取**,在网络IO或磁盘IO读取数据时,会根据情况为我们预读更多的字节数据到它自己维护的一个内部字节数组缓冲区中,这样,减少了读取时向内核空间复制数据到用户空间的次数(减少IO次数),加快效率。
Java Web的中文编码
4.1 几种常见编码比较
GB2312 vs GBK:GBK范围更广,能处理所有汉字字符,所以GBK更好。
UTF-16 vs UTF-8:UTF-16编码效率较高,适合磁盘到内存之间使用,可进行字符与字节的快速切换;UTF-8更适合网络传输。效率上:UTF-16>UTF-8>GBK
4.2 URL编解码
URL组成部分:

-
Get提交:浏览器对PathInfo和QueryString的编码不一样,相应的,服务器对于两者的解码也不一样。前者通过设置
这里不推荐使用String value=new String(request.getParameter(key).getBytes("ISO-8859-1"),"gbk"),因为它额外增加了一次编解码。 -
Post提交:在调用
request.getParameter()之前设置request.setCharacterEncoding(charset)。 -
返回资源编码:通过设置
response.setCharacterEncoding(charset)。 -
JS与Java的编解码:JAVA端的
URLEncoder和URLDecoder与前端JS的encodeURIComponet和decodeURIComponet对应。 -
常见问题分析:
-
中文变成了看不懂的字符(如“淘!我喜欢!”变成了“ÌÔ£¡ÎÒϲ»¶£¡”或是“�ԣ���ϲ����”):解码字符集和编码字符集不一致。
-
一个汉字变成一个问号(如“淘!我喜欢!”变成了“??????”):中文和中文字符经过了不支持中文的ISO-8859-1编码
-