Flink1.10入门:详解三种部署模式
微信公众号:大数据开发运维架构
关注可了解更多大数据相关的资讯。问题或建议,请公众号留言;
如果您觉得“大数据开发运维架构”对你有帮助,欢迎转发朋友圈
从微信公众号拷贝过来,格式有些错乱,建议直接去公众号阅读
一、概述
Flink有三种部署模式Local、Standalone、On Yarn,这里拿最新的稳定版本flink1.10.0演示下。
系统版本
Centos7.2
JDK1.8
二、三种部署模式
这里用的scala2.11版本,下载地址:
https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz
1.Local模式 一般用户本地测试
上传到服务器,解压、启动即可,这里可以不用配置,直接用默认的:
//解压[root@master app]# tar -zxvf flink-1.10.0-bin-scala_2.11.tgz//直接运行脚本启动即可[root@master bin]# /data/app/flink-1.10.0/bin/start-cluster.sh
默认界面访问端口是8081,可验证下是否启动成功。
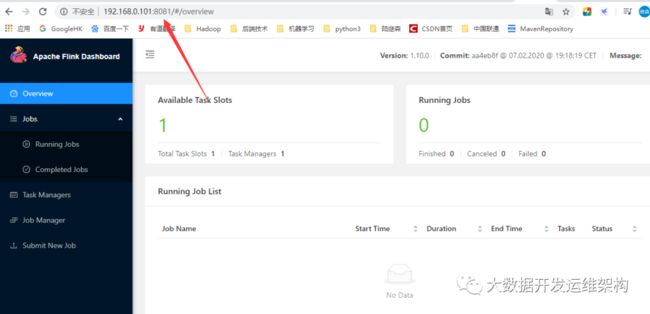
2.Standalone模式
主机信息:
| IP | 主机名 | 备注 |
| 192.168.0.101 | master.hadoop.ljs | master |
| 192.168.0.102 | worker1.hadoop.ljs | worker1 |
| 192.168.0.103 | worker2.hadoop.ljs | worker2 |
2.1 先上传到master节点,解压:
//解压[root@master app]# tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
2.2 修改配置文件
1).修改conf目录下配置文件flink-conf.yaml,这里只放开了最些基本的配置,其他配置以后再去讲解,这里先不用关注,只是给你列出来了:
#基础配置------------------------------------------------------------------------#jobmanager地址jobmanager.rpc.address: master.hadoop.ljs# jobManager 的rpc通信端口号jobmanager.rpc.port: 6123# jobManager JVM heap 内存大小jobmanager.heap.size: 1024m#taskManager JVM heap 内存大小taskmanager.heap.size: 1024m# 每个taskManager提供任务的slots数量大小taskmanager.numberOfTaskSlots: 1#程序默认的并行计算的个数parallelism.default: 1#故障恢复策略 基于 Region 的局部重启 这个策略后面单独讲解jobmanager.execution.failover-strategy: region#restApi端口rest.port: 8081#临时文件io.tmp.dirs: /data/app/flink-1.10.0/tmp# 基于 Web 的运行时监视器侦听的地址.#jobmanager.web.address: 0.0.0.0# 是否从基于 Web 的 jobmanager 启用作业提交# jobmanager.web.submit.enable: false#HA高可用配置------------------------------------------------------------------------# 可以选择 'NONE' 或者 'zookeeper'.# high-availability: zookeeper# 文件系统路径,让 Flink 在高可用性设置中持久保存元数据# high-availability.storageDir: hdfs:///flink/ha/# zookeeper 集群中仲裁者的机器 ip 和 port 端口号# high-availability.zookeeper.quorum: localhost:2181# 默认是 open,如果 zookeeper security 启用了该值会更改成 creator# high-availability.zookeeper.client.acl: open# 用于网络缓冲区的JVM内存的分数。这决定了 TaskManager 可以同时拥有多少流数据交换通道以及通道缓冲的程度。# 如果作业被拒绝或者您收到系统没有足够缓冲区的警告,请增加此值或下面的最小/最大值。# 另外请注意'taskmanager.network.memory.min'和'taskmanager.network.memory.max'可能会覆盖此分数# taskmanager.network.memory.fraction: 0.1# taskmanager.network.memory.min: 67108864# taskmanager.network.memory.max: 1073741824#容错和Checkpoint配置------------------------------------------------------------------------# 用于存储和检查点状态# state.backend: filesystem# 存储检查点的数据文件和元数据的默认目录# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints# savepoints 的默认目标目录(可选)# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints# 用于启用/禁用增量 checkpoints 的标志#安全配置------------------------------------------------------------------------# 指示是否从 Kerberos ticket 缓存中读取# security.kerberos.login.use-ticket-cache: true# 包含用户凭据的 Kerberos 密钥表文件的绝对路径# security.kerberos.login.keytab: /path/to/kerberos/keytab# 与 keytab 关联的 Kerberos 主体名称# security.kerberos.login.principal: flink-user# 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证)# 你可以通过 bin/historyserver.sh (start|stop) 命令启动和关闭 HistoryServer#HistoryServer相关配置------------------------------------------------------------------------# 将已完成的作业上传到的目录# jobmanager.archive.fs.dir: hdfs:///completed-jobs/# 基于 Web 的 HistoryServer 的地址# historyserver.web.address: 0.0.0.0# 基于 Web 的 HistoryServer 的端口号# historyserver.web.port: 8082# 以逗号分隔的目录列表,用于监视已完成的作业# historyserver.archive.fs.dir: hdfs:///completed-jobs/# 刷新受监控目录的时间间隔(以毫秒为单位)
2).修改conf目录下配置文件masters和slaves
masters
master.hadooop.ljs:8081slaves
worker1.hadoop.ljsworker2.hadoop.ljs
3).拷贝到其他节点
scp -r /data/app/flink-1.10.0 worker1.hadoop.ljs:/data/app/scp -r /data/app/flink-1.10.0 worker2.hadoop.ljs:/data/app/
2.3 配置环境变量 ,在/etc/profile中添加以下内容:
export FLINK_HOME=/data/app/flink-1.10.0export PATH=$PATH:$FLINK_HOME/bin
source /etc/profile //使环境变量生效2.4 启动集群(在master节点操作)
/data/app/flink-1.10.0/bin/start-cluster.sh可登录master.hadoop.ljs:8081界面验证是否启动成功,这里启动了两个taskmanager,如图所示:
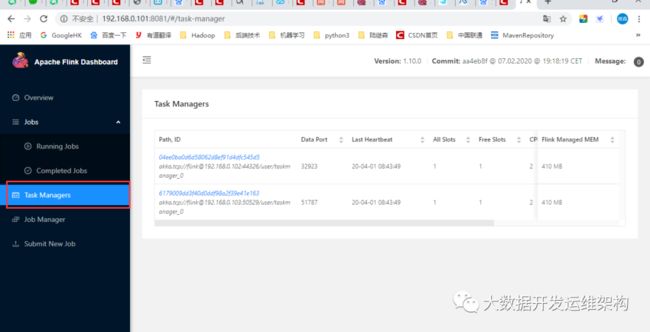
2.4报错信息处理
1).启动集群报错信息
2020-04-01 08:35:28,614 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Install security context.
at org.apache.flink.runtime.security.SecurityUtils.install(SecurityUtils.java:73)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.installSecurityContext(ClusterEntrypoint.java:200)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:166)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:518)
at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:64)
Caused by: java.lang.RuntimeException: unable to generate a JAAS configuration file
at org.apache.flink.runtime.security.modules.JaasModule.generateDefaultConfigFile(JaasModule.java:170)
at org.apache.flink.runtime.security.modules.JaasModule.install(JaasModule.java:94)
at org.apache.flink.runtime.security.SecurityUtils.install(SecurityUtils.java:67)
... 4 more
Caused by: java.nio.file.NoSuchFileException: /data/app/flink-1.10.0/tmp/jaas-7593212081001397255.conf
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:86)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214)
at java.nio.file.Files.newByteChannel(Files.java:361)
at java.nio.file.Files.createFile(Files.java:632)
at java.nio.file.TempFileHelper.create(TempFileHelper.java:138)
at java.nio.file.TempFileHelper.createTempFile(TempFileHelper.java:161)
at java.nio.file.Files.createTempFile(Files.java:852)
at org.apache.flink.runtime.security.modules.JaasModule.generateDefaultConfigFile(JaasModule.java:163)
... 6 more
.
2020-04-01 08:35:28,630 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Could not start cluster entrypoint StandaloneSessionClusterEntrypoint.
org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint StandaloneSessionClusterEntrypoint.
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:187)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:518)
at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:64)
Caused by: java.lang.Exception: unable to establish the security context
at org.apache.flink.runtime.security.SecurityUtils.install(SecurityUtils.java:73)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.installSecurityContext(ClusterEntrypoint.java:200)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:166)
... 2 more
Caused by: java.lang.RuntimeException: unable to generate a JAAS configuration file
at org.apache.flink.runtime.security.modules.JaasModule.generateDefaultConfigFile(JaasModule.java:170)
at org.apache.flink.runtime.security.modules.JaasModule.install(JaasModule.java:94)
at org.apache.flink.runtime.security.SecurityUtils.install(SecurityUtils.java:67)
... 4 more
Caused by: java.nio.file.NoSuchFileException: /data/app/flink-1.10.0/tmp/jaas-7593212081001397255.conf
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:86)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214)
at java.nio.file.Files.newByteChannel(Files.java:361)
at java.nio.file.Files.createFile(Files.java:632)
at java.nio.file.TempFileHelper.create(TempFileHelper.java:138)
at java.nio.file.TempFileHelper.createTempFile(TempFileHelper.java:161)
at java.nio.file.Files.createTempFile(Files.java:852)
at org.apache.flink.runtime.security.modules.JaasModule.generateDefaultConfigFile(JaasModule.java:163)
... 6 more
解决方案:
由于我在flink-conf.yaml中修改了临时文件路径配置项io.tmp.dirs,他不会自动创建,在三个节点手动创建、授予权限即可:
mkdir -p /data/app/flink-1.10.0/tmpchmod -R 755 /data/app/flink-1.10.0/tmp
3.Flink On Yarn模式
下面是FLink官网的Flink与Yarn的交互流程图:
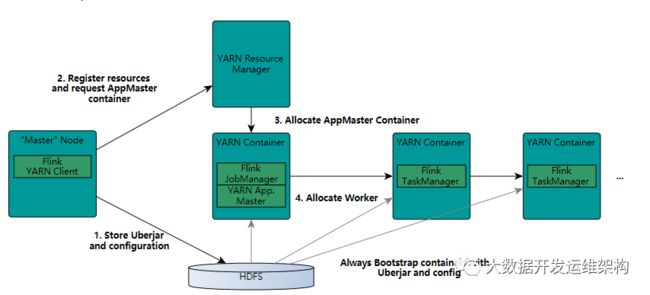
Flink On Yarn有两种任务提交模式
这里有个需要注意,由于yarn内部运行需要和hadoop的类一起启动,所以需要在flink的节点配置环境变量 HADOOP_CLASSPATH,在/etc/profile文件最后添加:
export HADOOP_CLASSPATH=`hadoop classpath`使环境变量生效:
source /etc/profile
1).第一种是yarn session模式
先用yarn-session.sh启动一个session会话,在yarn上申请资源,相当于起了一个yarn任务,这个session资源不变并一直运行;flink run提交任务,这里需要注意,如果提交任务过多session资源占满了,后面任务只能等待其他作业执行完后才能正常提交。
启动session:
bin/yarn-session.sh -n 2 -s 2 -jm 768 -tm 768-n : TaskManager的数量,相当于executor的数量
-s : 每个JobManager的core的数量,executor-cores。建议将slot的数量设置每台机器的处理器数量
-tm : 每个TaskManager的内存大小,executor-memory
-jm : JobManager的内存大小,driver-memory
-s : 每个taskmanager的slot槽位数 默认是1
上面的命令的意思是,同时向Yarn申请3个container,其中 2 个 Container 启动 TaskManager(-n 2),每个 TaskManager 拥有两个 Task Slot(-s 2),并且向每个 TaskManager 的 Container 申请 768M 的内存,以及一个ApplicationMaster(Job Manager)。
启动成功后可在yarn上看到这个任务,如图所示:
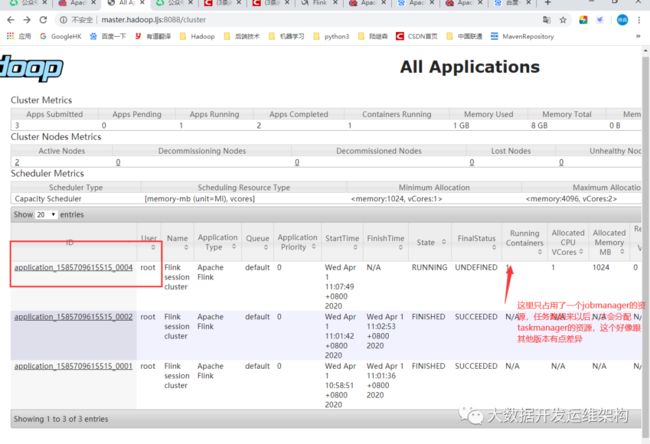
可通过以下命令提交任务:
/data/app/flink-1.10.0/bin/flink run -m yarn-cluster -yid application_1585709615515_0004 -ys 2 /data/app/flink-1.10.0/examples/batch/WordCount.jar -m : 指定运行模式 这里是yarn-cluster集群模式
-yid : 就是你启动的yarn-session在yarn上的任务ID,重启yarn这个ID会变化;
-ys: 每个taskmanager上的槽位数slot
2).第二种 直接在yarn上运行任务
通过flink run命令也可直接在yarn上提交flink任务,这种方式一个任务对应yarn上一个job,每个Job根据需要指定对应的yarn资源,这样每个作业不会影响到下一个作业的运行,但是如果yarn集群上没有任何资源的话也会报错。
可通过以下命令提交任务:
/data/app/flink-1.10.0/bin/flink run -ytm 1024 -ys 2 /data/app/flink-1.10.0/examples/batch/WordCount.jar
如果觉得我的文章能帮到您,请关注微信公众号“大数据开发运维架构”,并转发朋友圈,谢谢支持!!!
