Flink 之 Dataflow、Task、subTask、Operator Chains、Slot 介绍
本文开头附:Flink 学习路线系列 ^ _ ^
1.概念
Task(任务):Task 是一个阶段多个功能相同 subTask 的集合,类似于 Spark 中的 TaskSet。
subTask(子任务):subTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑。
Operator Chains(算子链):没有 shuffle 的多个算子合并在一个 subTask 中,就形成了 Operator Chains,类似于 Spark 中的 Pipeline。
Slot(插槽):Flink 中计算资源进行隔离的单元,一个 Slot 中可以运行多个 subTask,但是这些 subTask 必须是来自同一个 application 的不同阶段的 subTask。
2.Dataflows数据流介绍
Dataflows数据流介绍,参考自 Flink 官方文档。
Flink 程序的基本构建是 流(Stream)和转换(Transform)。
从概念上讲,流是对当前数据流向的记录(流也可能是永无止境的) ,而转换是将一个或多个流作为输入,根据需要求转换成我们要的格式的流的过程。
当程序执行时,Flink程序会将数据流进行映射、转换运算成我们要的格式的流。每个数据流都以一个或多个源(Source)开始,并以一个或多个接收器(Sink)结束,数据流类似于任意有向无环图(DAG)。
2.1 串行数据流
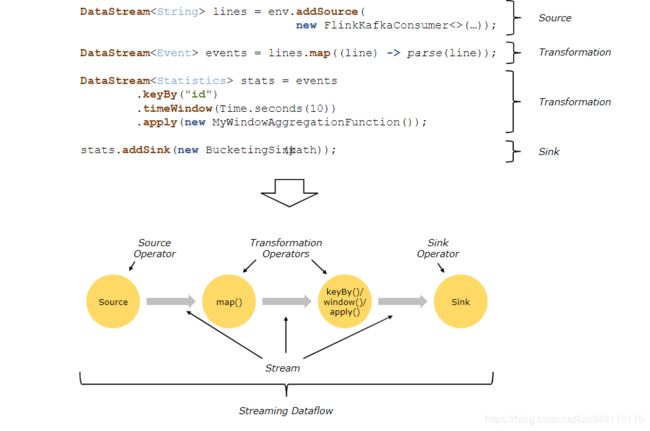
多个 Operator 之间,通过 Stream 流进行连接,Source、Transformation、Sink之间就形成了一个有向非闭环的 Dataflow Graph(数据流图)。
2.2 并行数据流
并行数据流介绍,参考自 Flink 官方文档。
Flink 中的程序本质上是并行的。在执行期间,每一个算子(Transformation)都有一个或多个算子subTask(Operator SubTask),每个算子的 subTask 之间都是彼此独立,并在不同的线程中执行,并且可能在不同的机器或容器上执行。
Operator subTask 的数量指的就是算子的并行度。同一程序的不同算子也可能具有不同的并行度(因为可以通过 setParallelism() 方法来修改并行度)

2.2.1 如何划分 Task 的依据
- 并行度发生变化时;
- keyBy() /window()/apply() 等发生 Rebalance 重新分配;
- 调用 startNewChain() 方法,开启一个新的算子链;
- 调用 diableChaining()方法,即:告诉当前算子操作不使用 算子链 操作。
针对内存密集型、CPU密集型,使用 startNewChins()、disableChaining()方法,可以将当前算子单独放到一个 Task 中,使其独享当前Task的所有资源,以此来提升计算效率。
2.2.2 如何计算 Task 和 subTask 个数

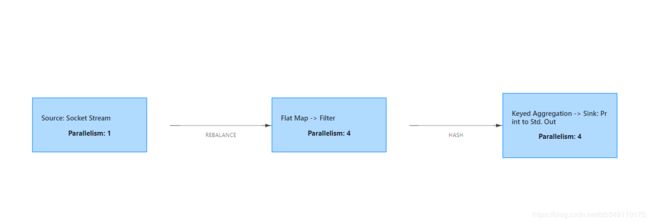
上图并行数据流,一共有 3个 Task,5个 subTask。
流可以按照一对一模式或重新分配模式在两个 Operator 算子之间传输数据:
- 一对一的流:(
例如上图中的 Source 和 map() 算子之间的流)它们都保留各自元素的分区和排序。即:map() 算子的 subtask[1] 将会与产生相同元素顺序的Source() 算子的 subtask[1] 关联,进行数据传输。 - 重新分配的流:(例如上图的
map()和 keyBy()/window()之间以及keyBy ()/window()和Sink之间)重新分配流会改变流的分区。每个算子subTask都将数据发送到不同的目标subTask,具体 subTask 取决于所选算子使用的转换方法。例如: keyBy() 通过 Hash 散列重新分区;broadcast()广播;或者 rebalance() (随机重新分区)。
2.2.3 Demo进行Task划分
/**
* TODO Lambda表达式,实现实时WordCount
*
* @author liuzebiao
* @Date 2020-2-4 15:49
*/
public class LambdaStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建一个 flink steam 程序的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.获取 DataSource 数据来源
DataStreamSource<String> lines = env.socketTextStream("192.168.204.210", 8888);
//3.Transformation 过程
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)))).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(0).sum(1);
//4.Sink过程
sumed.print().setParallelism(2);
//5.任务执行过程
env.execute("LambdaStreamWordCount");
}
}
Task总数:4
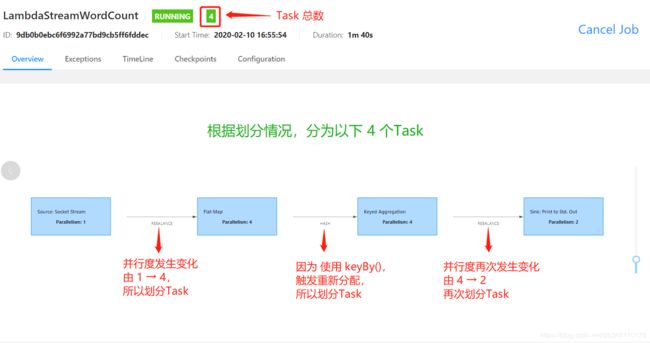
subTask总数:11

3.Operator Chains介绍
Operator Chains介绍,参考自:Flink官方文档
Flink 将多个 subTask 合并成一个 Task(任务),这个过程叫做 Operator Chains,每个任务由一个线程执行。使用 Operator Chains(算子链) 可以将多个分开的 subTask 拼接成一个任务。Operator Chains 是一个有用的优化,它减少了线程到线程的切换和缓冲的开销,并在降低延迟的同时提高了总体吞吐量。
下图中的示例,数据流由五个子任务执行,因此由五个并行线程执行。

4.Slot资源槽
我们已经知道:1.同一个application,多个 task的 subTask,可以运行在同一个 slot 资源槽中。 2.同一个 task 中的多个的 subTask,不能运行在一个 slot 资源槽中,他们可以分散到其他的资源槽中 (如不理解,请继续看下面示例)
举个例子:
/**
* TODO 共享资源槽Demo
*
* @author liuzebiao
* @Date 2020-2-4 15:49
*/
public class LambdaStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建一个 flink steam 程序的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.获取 DataSource 数据来源
DataStreamSource<String> lines = env.socketTextStream("192.168.204.210", 8888);
//3.Transformations 过程(处理数据过程一行搞定)
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleOperator = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)))).returns(Types.TUPLE(Types.STRING,Types.INT));
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = tupleOperator.filter(tuple2 -> tuple2.f0.startsWith("H"));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = streamOperator.keyBy(0).sum(1);
//4.sink过程
summed.print();
//5.任务执行过程
env.execute("LambdaStreamWordCount");
}
}
如图,该任务共有 3 个Task,9个subTask。
目前集群环境: 2 个TaskManager,共 4 个 slot 资源槽。上述例子中的 3个 Task 和 9个 subTask 在 slot 资源槽中分配情况,如下图所示:
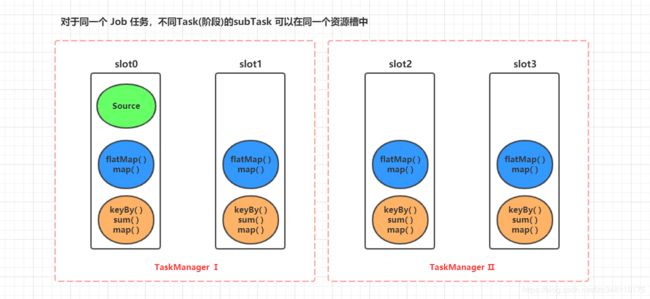
这么看的话,每一个 slot 资源槽中的多个subTask,便构成了一条自上向下流水线开始运行

4.1 Slot共享资源槽
slot 资源槽是可以命名的,slot 资源槽默认名称为:default。在 Flink 中,我们可以使用 .slotSharingGroup(“资源槽名称”) 的方式来设置共享资源槽的名称。
还是上面例子,我们在 flatMap() 时,使用.slotSharingGroup(“flat_slot”)设置slot资源槽名称为 flat_slot,代码如下所示。【请注意.slotSharingGroup(“flat_slot”)部分】
/**
* TODO 使用slotSharingGroup()设置共享资源槽名称
*
* @author liuzebiao
* @Date 2020-2-4 15:49
*/
public class LambdaStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建一个 flink steam 程序的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.获取 DataSource 数据来源
DataStreamSource<String> lines = env.socketTextStream("192.168.204.210", 8888);
//3.Transformations 过程(处理数据过程一行搞定)
//设置共享资源槽名称为:flat_slot
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleOperator = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)))).returns(Types.TUPLE(Types.STRING,Types.INT)).slotSharingGroup("flat_slot");
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = tupleOperator.filter(tuple2 -> tuple2.f0.startsWith("H"));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = streamOperator.keyBy(0).sum(1);
//4.sink过程
summed.print();
//5.任务执行过程
env.execute("LambdaStreamWordCount");
}
}
当我们打包完成,提交到 Flink集群,配置相关参数后开始运行。参数如下图:

我们会发现,设置了.slotSharingGroup(“flat_slot”)资源槽名称后的任务,一直处于CREATED状态。

发现 9 个 subTask 的状态为 SCHEDULED 调度状态

CREATED 和 SCHEDULED 5分钟后,任然无法运行,便会将该任务自动置为 FAILED 失败状态。

4.2 使用Slot共享资源槽后,处于SCHEDULED 错误分析
我们知道 slot 资源槽默认名称为:default。接 4.1 代码,当我们在 flatMap()阶段为slot资源槽设置名称后,切记: 那么后面的 DataStream处理过程中,都会继承前面设置的共享资源槽的名称。
即:flatMap()前面的资源槽名称为 default,flatMap()后面的资源槽名称都变成了 4.1 中设置的 flat_slot。flatMap()就是一个界限,将slot划分为两个不同名称的 slot。
在 4.1 中,我们对参数并行度设置还是 4,此时有一个 slot 槽为 default,其他3个槽为 flat_slot。但是这 3个 flat_slot 槽显然无法满足 4个并行度任务的执行,所以会一致处于 SCHEDULED 状态,即:资源不够导致的调度失败,slot 调度详情如下图所示:
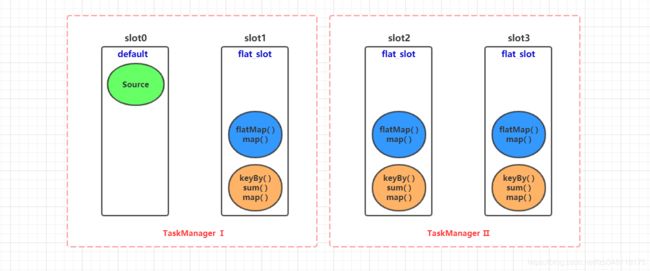
4 个并行度,只有 3 个 slot 可以用来执行 subTask 任务。3 < 4 ,资源不够,所以导致任务一直处于 SCHEDULED调度状态。
这种情况下,我们设置并行度为 3,该任务便能够正常执行了。
好处: 针对内存密集型、CPU密集型,使用 .slotSharingGroup(“flat_slot”)设置资源槽名称后,可以将当前算子单独放到一个 Task 中,使其独享当前Task的所有资源,以此来提升计算效率。

博主写作不易,来个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ