python爬取9000条京东内衣销售数据,最最最最基础的语言和语法;并利用这些数据,基于Aprior算法分析“是否罩杯大的人倾向于买贵一些的bra”
47[TOC](爬取9000条京东内衣销售数据,最最最最基础的语言和语法,并利用这些数据,基于Aprior算法分析“是否罩杯大的人倾向于买贵一些的bra”)
本人刚接触python和爬虫不久,靠着CSDN的博文自学,尽管有很多内 容看不懂,但是还是靠着度娘的支撑慢慢啃下了不少相关博文,并实现了爬取京东的一些销售数据。从学习到实现,为了理解其他大佬们简洁有效代码花了不少功夫,着实感到不易。为了让真正0基础的朋友能看得懂,我写一个最基础的语法程序来实现它(当然我也只会这些基础语法,哈哈,这也是本人第一篇博文,还希望和大家多多交流学习)。为什么选择分析bra的数据,因为衣物是必需品,数据比较多,选bra则是因为它具有一些特点,注重数据的研究,没有太多其他意图
目的
1.京东销售数据python爬虫的简单实现与分析
2.利用销售数据分析这个问题“是否罩杯大的人倾向于买贵一些的bra”(也就是想看看罩杯和消费价格倾向这两个看似无关的元素有没有一点关联)
3.当然在1、2之中需要一些简单的数据清洗和可视化
爬虫用到两个模块urllib.request、json
1.urllib.request
这个模块就是爬虫获取信息的主要工具
req=request.Request(url)
%用于请求爬取网页的函数,参数是url(url就是爬取目标的网页,稍后会介绍怎么获取京东的评论信息的url)
response=request.urlopen(req)
%根据‘open’的字面意思可以理解为请求通过后打开网页
str=response.read()
%打开页面之后再用.read()读取信息(就是我们已经爬取到的信息,是一个很长很长的字符串,里面包含了这个网页的所有信息)
2.json
json.loads(str)
%稍后我们会知道,读取到的str(json数据类型)是一个像python里面的字典格式的字符串,很标准的一个字典格式(键值对),里面包括想得到的数据信息(当然字典里面的值也可以是字典,简单的话把他理解成Python里面的字典就行,但是它在Python里面表象是一个字符串哦)。
json.loads()就是将这个字符串转化成python里面的字典,转化后的东西就完全和python里面的字典一样了
url获取以及代码解析
1.找到京东评论页面的url
下面有图片
1.打开商品页面,下滑找到评论区并点开评论区界面
2.按f12 弹出一个窗口,点击network(有时候会提示你再按一下f5才能出现信息)
3.点击name,让它按文件名排序文件,找到我圈起来这个文件(就是商品的评论页面的内容了)
4.右边就是网页的信息,红圈的地方就是url,下面篮圈的信息是一些请求头headers 和请求方式 methon 以及他们的参数之类的,初学者可以不用理会,他们有很大用处,可以自行百度,我这里不需要用到也不做解释了
5.复制url内容,这个就是我们想要去爬取的url了
6.其实你可以仔细看这个url里面包含两个很有用的参数,一个是productID(商品id),一个是page(页码)。京东里面的所有商品都有不同的id 你可以改变它,就变成了其他商品的评论内容了;改变page的数值就是变成了评论页面的第几页(不知道是不是Bug,京东一个页面十条评论,几万评论的商品应该有几千页才对,但是我一般爬到100页以后,评论信息就空了,只拿到1000多条,不知道是不是刷出来的评论数目了。。。)。更改这两个参数就可以爬取很多商品的评论信息了。


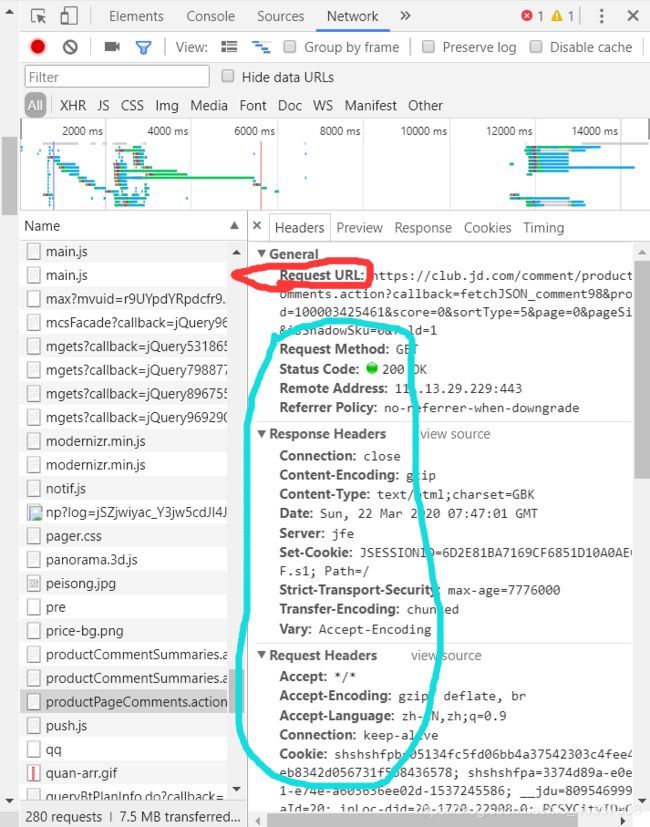
7.展示一个url:(id 和page我加粗斜体标注)
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100003425461&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
当然这个id会展现在这个商品的页面地址上

2.奉上代码和解析
下面展示一些 内联代码片。
from urllib import request
import json
url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100003425461&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
req=request.Request(url)
response=request.urlopen(req)
page=response.read()
### 以上是前文已经做了解析的,不再说明了
page=page.decode('gbk')
#对读取的内容进行解码,在京东评论这里用'gbk'方式
#当然有些网页不用,有些解码用utf-8,如果爬取出错的话增加解码可能会解决问题
#为什么要编解码,原理我不是很清楚,方法就是报错了就试一下就行
print(type(page),page)
#打印读取的内容 以及它的格式,发现它是一个很长的str类型,样子就是一个硕大的字典
#当然在字符串前面几个文字是无关的,可能就是一个记录作用,要把它删去才能用
#因为只有标准的str字典才能直接用json.loads将它变成python里面的字典
#打印出内容,然后发现,这个硕大的字典包含在“fetchJSON_comment98();”的括号里面
#因此我们就是删掉fetchJSON_comment98()
page=page.lstrip('fetchJSON_comment98(')
page=page.rstrip(');')
#strip函数是对字符串类型用的,将某些想要去掉的字符删除
#加个l 就是左边删除,加个r 就是右边删除
print(page)
#再打印出来就是我们想要的标准str字典了
page=json.loads(page)
#将它变成真正的python字典
print(type(page),page)
#再打印出来看看

for key,value in page.items():
print(key,':',value)
#再打印出字典内容来看看,发现没有找到想要的东西啊
#别急,它们还藏在键为comments的键值对里面
comments=page['comments']
print('----'*50)
print(comments)
print('----'*50)
#观察comments,它还是一个硕大的字典,但是外边加了一个[]包着,所以用列表索引打出来看看
print('---'*50)
for comment in comments:
print(comment)
#发现里面每一条内容就是一个评论者的内容,数据类型还是字典,往右慢慢观察,就能看到 productSize 、productColor、referenceTime 为键的键值对,值就是我们想要的了(分别是 规格、颜色、参考时间)
page字典内容:
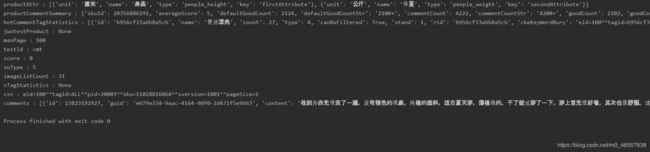
comment内容:

for comment in comments:
#print(comment)
size = comment['productSize']
color = comment['productColor']
paytime = comment['referenceTime']
row = [size, color, paytime]
ROW.append(row)
print(row)
#打印出数据看看,顺便在开头设置一个空的list ROW,
用于接收并保存每一个数据就行啦

爬取内容和详细解析完毕,查询更多数据,只需要改变url的page的值就行了,每一页有十条评论,用个for语句改变page的数值,就可以不断爬取,ROW是全局变量,就可以接收所有评论的值啦
下一篇,我将改变page的值和productid的值,爬取不同的价格的Bra的规格、颜色、时间等,再把得出的数据保存下来(一共差不多9000条),做一个简单的处理以及可视化和粗略的分析。
Mysql对爬取9000条数据进行整理和清洗
再下一篇,我将用这些处理好 的数据,用Aprior算法进行关联度分析,回答“是否罩杯大的女性倾向于购买更贵的bra”
Aprior算法进行关联度分析,回答“是否罩杯大的女性倾向于购买更贵的bra
我是新手,难免有搞错的地方,欢迎指正,重在学习,嘻嘻。需要完整代码的朋友可以私信我拿完整代码。