Scrapy框架——发送POST请求模拟登陆
除了携带Cookies进行网络登陆外https://mp.csdn.net/postedit/89874926,利用Scrapy 发送Post请求也可以进行模拟登陆。
下面以Github为例,进行POST登陆。登录界面如下:(https://www.github.com/login)
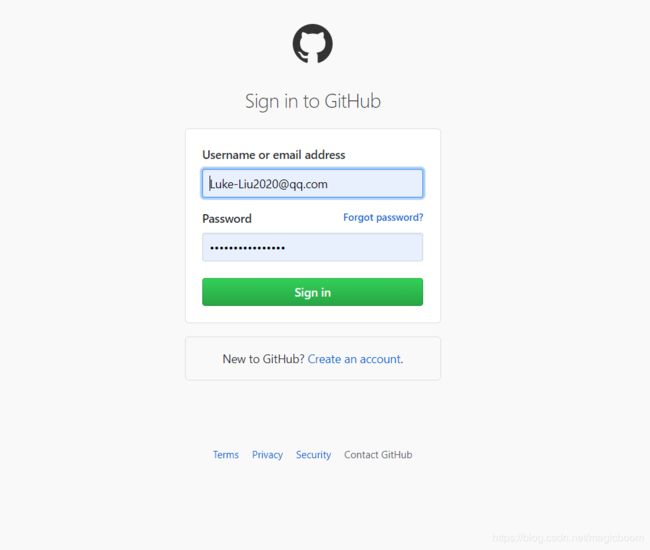
我们可以想尝试发一次错误的密码,相当于发送了一次POST请求,看看结果。

但是我们可以注意到发送完一次POST请求后的网址变化了
![]()
我们可以F12检查元素:的确看懂Request URL变化了

我们看一下表单的信息:
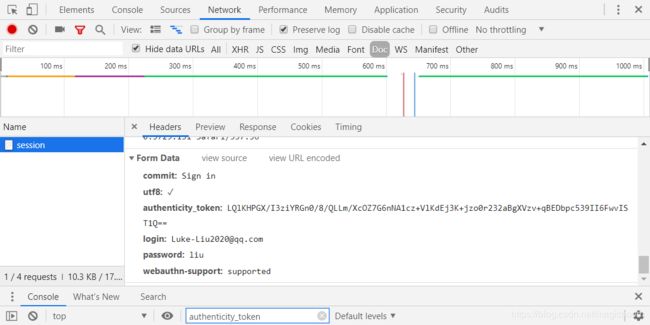
那么我们接下的任务就利用这些Form data 构造一个POST请求。
Form Data 的每个数据项目可以视为一个字典,我们要获得每个项目的对应值,可以用Xpath动态提取。
但是一般 “login”和Passwork是需要你自己输入的。
OK,那么我们开始写spider文件。
# -*- coding: utf-8 -*-
import scrapy
import re
class GhSpider(scrapy.Spider):
name = "gh"
allowed_domains = ["github.com"]
start_urls = ['https://github.com/login']
def parse(self, response):
#定义post请求的数据
request_url="https://github.com/session"
#定义 Form Data的数据
authenticity_token=response.xpath("//input[@name='authenticity_token']/@value").extract_first()
utf8=response.xpath("//input[@name='utf8']/@value").extract_first()
commit=response.xpath("//input[@name='commit']/@value").extract_first()
webauthn=response.xpath("//input[@name='webauthn-support']/@value").extract_first()
post_data=dict(
login="[email protected]",
password="liuzihua19961004",
commit=commit,
utf8=utf8,
authenticity_token=authenticity_token,
)
post_data["webauthn-support"] = webauthn
#发送请求
yield scrapy.FormRequest(
request_url,
# fromdata以字典的格式传入
formdata = post_data,
callback=self.parse_after
)
def parse_after(self,response):
print(response.body.decode())
注意这一部分:scrapy.FromRequest 与普通的scrapy.Request不同,scrapy.FromRequest可以传入数据值,比如fromdata。
注意,url必须是发送过POST后的Url
#发送请求
yield scrapy.FormRequest(
request_url,
# fromdata以字典的格式传入
formdata = post_data,
callback=self.parse_after
)在spider中,我测试一下,所以输出response的body.
然后为了保证爬虫顺利,在这里设置settings.py文件。
BOT_NAME = 'github'
SPIDER_MODULES = ['github.spiders']
NEWSPIDER_MODULE = 'github.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
然后,cmd输入运行试一下:
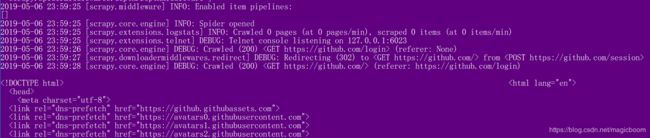
我们看到POST发送成功!response.body也被successfully crawled!
另外的方法是使用:scrapy.FormRequest.from_response,它的优点是相比 scrapy.FormReques,它可以自动从response中获得表单,因此只需要输入要输入的表单内容即可(如用户名,密码),其他的自动获取
yield scrapy.FormRequest.from_response(
response,#自动从response数据中寻找表单
#只需要输入要输入的表单内容即可,其他的自动获取
formdata={
"login":"[email protected]",
"password":"liuzihua19961004",
},
callback=self.parse_after
)