flume简单介绍
一:flume 的简介与功能架构
1.1 flume 的简介:
1.1.1 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.1.2当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
1.2 flume 的功能:
1.2.1 flume 是一个分布式的,可靠的,可用的,非常有效率的对大数据量的日志数据进行收集,聚集,移动信息的服务。flume 仅支持在linux上面运行.
1.2.2 flume 是一个基于流式数据,非常简单(就写一个配置文件就可以),灵活的架构,一个健壮的,容错的,简单的扩展数据模型用于在线上实时应用分析, 他的表现为:写一个source,channel,sink 之后一条命令就能够操作成功了。
1.2.3 flume , kafka 实时进行数据收集,spark , storm 实时去处理,impala 实时去查询。
1.3 flume 结构图 :

1.4 flume 的结构图解释:
flume-ng 只有一个角色的节点:agent 的角色,agent 有source,channel, sink 组成。
1. Event 是flume数据传输的基本单元
2. flume 以事件的形式将数据从源头传送到最终的目的
3. Event 由可选的header 和加载有数据的一个byte array 构成
3.1 载有的数据对flume 是不透明的
3.2 header 是容纳凌key-value字符串对的无序集合,key 在集合内饰唯一的。
3.3 header 可以在上下文路由中使用扩展1.5 Channel/Event/Sink 图:
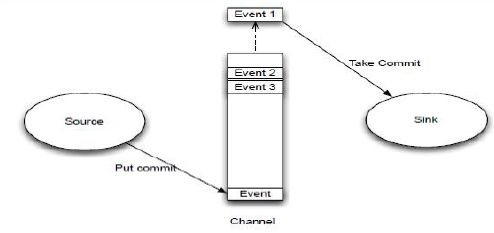
source 监控某个文件,将数据拿到,封装在一个event当中,并put/commit 到chennel 当中,chennel 是一个队列,队列的有点事先进先出,放好后尾部一个个 event 出来,sink 主动去从chennel 当中去拉数据,sink 在把数据写到某个地方,比如hdfs 上去。
二: flume 的安装与配置
2.1 flume 的安装:
下载flume的cdh 版本:flume-ng-1.5.0-cdh5.3.6.tar.gz
安装flume-ng:
tar -zxvf flume-ng-1.5.0-cdh5.3.6.tar.gz
mv apache-flume-1.5.0-cdh5.3.6-bin yangyang/flume 2.2 生成配置文件:
cd yangyang/flume/conf
cp -p flume-env.sh.template flume-env.sh
cp -p flume-conf.properties.template flume-conf.properties
更改 flume-env.sh 增加java 的环境
export JAVA_HOME=/home/hadoop/yangyang/jdk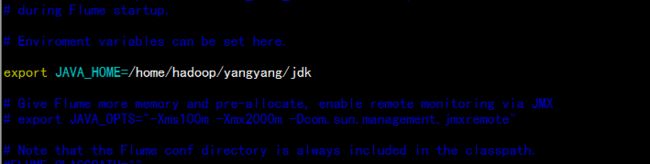
2.3 安装 telnet 的包:
yum install -y telnet-*
rpm -ivh netcat-1.10-891.2.x86_64.rpm2.4 创建test-conf.properties 文件处理
cd /home/hadoop/yangyang/flume/
cp -p flume-conf.properties test-conf.properties
echo "" > test-conf.properties 清空文件vim test-conf.properties
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1运行一个agent 处理
cd /home/hadoop/yangyang/flume
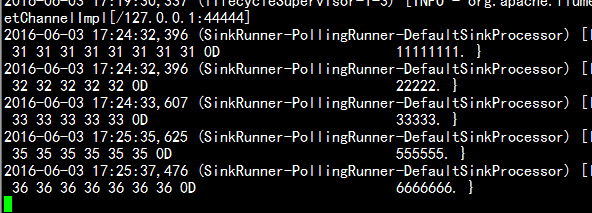
bin/flume-ng agent --conf conf --conf-file conf/test-conf.properties --name a1 -Dflume.root.logger=INFO,console

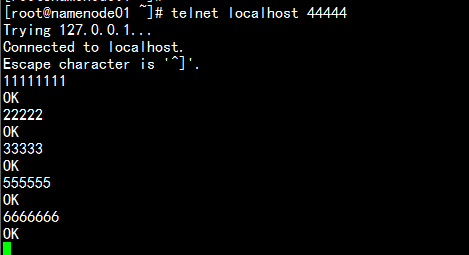
telnet 登陆处理:
telnet localhost 44444
三: flume 的扩展
3.1 Flume有哪些优缺点
(1).优点
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据.
3. 提供上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
6.实时性,Flume有一个好处可以实时的将分析数据并将数据保存在数据库或者其他系统中
(2).缺点
Flume的配置很繁琐,source,channel,sink的关系在配置文件里面交织在一起,不便于管理
3.2 应用场景
(1).电子商务网站
比如我们在做一个电子商务网站,然后我们想从消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图. 这样我们就可以更加快速的将他想要的推送到界面上,实现这一点,我们需要将获取到的她访问的页面以及点击的产品数据等日志数据信息收集并移交给Hadoop平台上去分析.而Flume正是帮我们做到这一点
(2).内容推送
现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于次
(3).ETL工具
可以利用插件把关系型数据实时增量的导入到Hdfs外部数据源
七、其他类似Flume框架
Facebook的Scribe,还有Apache新出的另一个明星项目chukwa,还有淘宝Time Tunnel
3.3 Flume插件
1. Interceptors拦截器
用于source和channel之间,用来更改或者检查Flume的events数据
2. 管道选择器 channels Selectors
在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
默认管道选择器: 每一个管道传递的都是相同的events
多路复用通道选择器: 依据每一个event的头部header的地址选择管道.
3.sink线程
用于激活被选择的sinks群中特定的sink,用于负载均衡.