一篇文章教会你利用Python网络爬虫抓取百度贴吧评论区图片和视频
点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利
【一、项目背景】
百度贴吧是全球最大的中文交流平台,你是否跟我一样,有时候看到评论区的图片想下载呢?或者看到一段视频想进行下载呢?
今天,小编带大家通过搜索关键字来获取评论区的图片和视频。
【二、项目目标】
实现把贴吧获取的图片或视频保存在一个文件。
【三、涉及的库和网站】
1、网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=吴京&fr=search
2、涉及的库:requests、lxml、urrilb
【四、项目分析】
1、反爬措施的处理
前期测试时发现,该网站反爬虫处理措施很多,测试到有以下几个:
1) 直接使用requests库,在不设置任何header的情况下,网站直接不返回数 据。
2) 同一个ip连续访问40多次,直接封掉ip,起初我的ip就是这样被封掉的。
为了解决这两个问题,最后经过研究,使用以下方法,可以有效解决。
获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2、如何实现搜索关键字?
通过网址我们可以发现只需要在kw=() ,括号中输入你要搜索的内容即可。这样就可以用一个{}来替代它,后面我们在通过循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个主方法main和初始化方法init。导入需要的库。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
pass
def main(self):
pass
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
spider.main()
pass
if __name__ == '__main__':
spider= ImageSpider()
spider.main()
2、准备url地址和请求头headers 请求数据。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name #输入的名字
self.url = "http://tieba.baidu.com/f?kw={}&ie=utf-8&pn=0"
self.headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
'''发送请求 获取响应'''
def get_parse_page(self, url, xpath):
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
parse_html = etree.HTML(html)
r_list = parse_html.xpath(xpath)
return r_list
def main(self):
url = self.url.format(self.tieba_name)
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
key_word = parse.quote(inout_word)
spider = BaiduImageSpider(key_word)
spider.main()
3、用xpath进行数据分析
3.1、chrome_Xpath插件安装
1) 这里用到一个插件。能够快速检验我们爬取的信息是否正确。具体安装方法如下。
2) 百度下载chrome_Xpath_v2.0.2.crx, chrome浏览器输入:chrome://extensions/

3) 直接将chrome_Xpath_v2.0.2.crx拖动至该扩展程序页面 ;
4) 如果安装失败,弹框提示“无法从该网站添加应用、扩展程序和用户脚本”,遇到这个问题,解决方法 是:打开开发者模式,将crx文件(直接或后缀修改为rar)并解压成文件夹,点击开发者模式的加载已解压的扩展程序,选择解压后的文件夹,点击确定,安装成功;
3.2、chrome_Xpath插件使用
上面我们已经安装好了chrome_Xpath插件,接下来我们即将使用它。
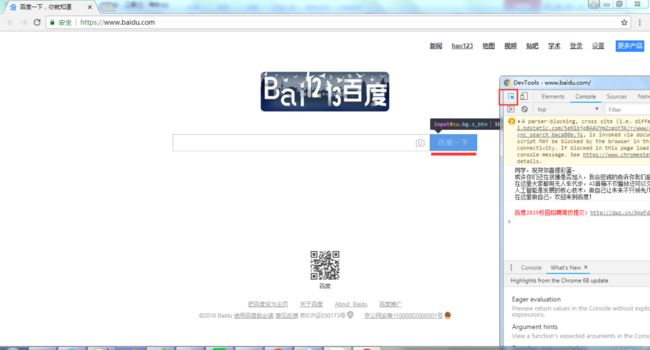
1) 打开浏览器,按下快捷键F12 。
2) 选择元素,如下图所示。
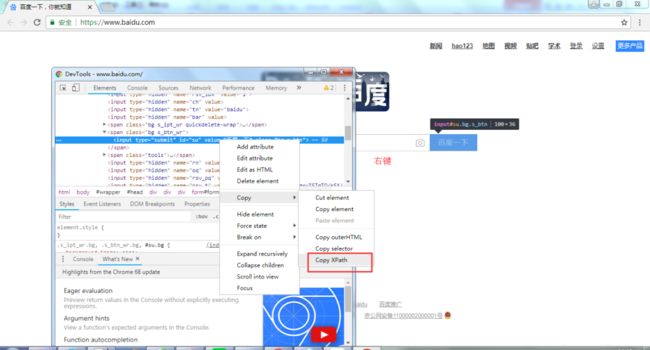
3) 右键,然后选择,“Copy XPath”,如下图所示。
3.3、编写代码,获取链接函数。
上面我们已经获取到链接函数的Xpath路径,接下来定义一个获取链接函数get_tlink,并继承self,实现多页抓取。
'''获取链接函数'''
def get_tlink(self, url):
xpath = '//div[@class="threadlist_lz clearfix"]/div/a/@href'
t_list = self.get_parse_page(url, xpath)
# print(len(t_list))
for t in t_list:
t_link = "http://www.tieba.com" + t
'''接下来对帖子地址发送请求 将保存到本地'''
self.write_image(t_link)
4、保存数据
这里定义一个write_image方法来保存数据,如下所示。
'''保存到本地函数'''
def write_image(self, t_link):
xpath = "//div[@class='d_post_content j_d_post_content clearfix']/img[@class='BDE_Image']/@src | //div[@class='video_src_wrapper']/embed/@data-video"
img_list = self.get_parse_page(t_link, xpath)
for img_link in img_list:
html = requests.get(url=img_link, headers=self.headers).content
filename = "百度/"+img_link[-10:]
with open(filename, 'wb') as f:
f.write(html)
print("%s下载成功" % filename)
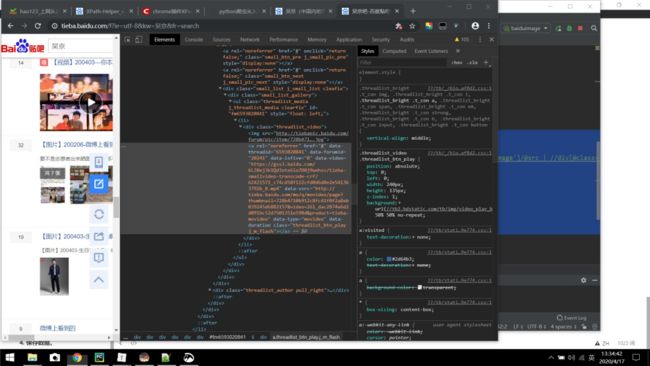
注:@data-video是网址中的视频,如下图所示。
【六、效果展示】
1、点击运行,如下图所示(请输入你要查询的信息):
2、以吴京为例输入,回车:
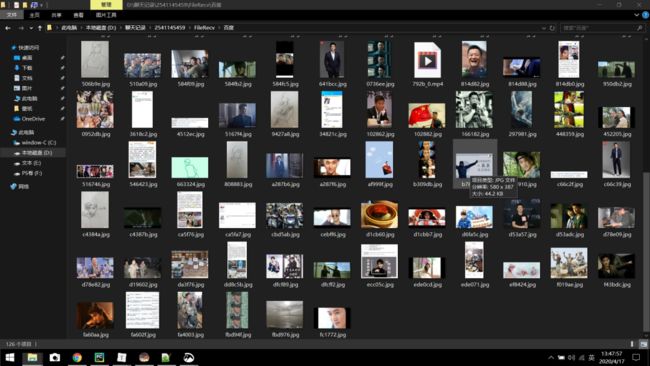
3、将图片下载保存在一个名为“百度”文件夹下,这个文件夹需要你提前在本地新建好。务必记得提前在当前代码的同级目录下,新建一个名为“百度”的文件夹,否则的话系统将找不到该文件夹,会报找不到“百度”这个文件夹的错误。

4、下图中的MP4就是评论区的视频。
【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、本文基于Python网络爬虫,利用爬虫库,实现百度贴吧评论区爬取。就Python爬取百度贴吧的一些难点, 进行详细的讲解和提供有效的解决方案。
3、欢迎大家积极尝试,有时候看到别人实现起来很简单,但是到自己动手实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。学习requests 库的使用以及爬虫程序的编写。
4、通过本项目可以更快的去获取自己想要的信息。
5、需要本文源码的小伙伴,后台回复“百度贴吧”四个字,即可获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

------------------- End -------------------
往期精彩文章推荐:
一篇文章教会你用Python抓取抖音app热点数据
一篇文章教会你使用Python定时抓取微博评论
手把手教你使用Python抓取QQ音乐数据(第四弹)