Tensorflow与keras学习 (1)——Tensorflow 回归与分类
Tensorflow 回归与分类
1.1 Tensorflow是什么?
Tensorflow是谷歌公司推出的开源深度学习框架,利用它我们可以快速搭建深度学习模型。
1.2 Tensorflow是什么样的框架?
Tensorflow跟很多机器学习库类似,采用了“流图”方式,这样做的好处可以减小计算开销。一般情况下,python的数值计算库会将矩阵乘法之类的复杂计算传送到外部外部语言计算(更高效的语言c,汇编等),但是每次计算转换回来的操作依然是很大的开销。所以“流图”方式采用,先用图和流来描述模型,再将整个模型一起送出去计算,计算完再送回来,这样减少了转换次数以减少开销。
1.3 Tensorflow怎么用?
Tensorflow内部集成了很多的神经网络的反向传播算法,以及其优化方式。只需要编程设置相应的参数即可选择适当的反向传播优化器。
它为我们解决了复杂的反向传播过程的实现,在构建模型时,我们只需要搭建正向的神经网络传输模型以及给出损失函数即可。
1.4 再具体一点?
在Tensorflow中操作的数据对象是tensor(包括常量和变量),由对象和操作OP就构成了图Graph, 将各个图的输入输出连接就形成的流图,至此模型的表示便完成了。在这个框架下表示和执行是分开的,因此,session会话便出场了,将表示放在session中就可以运行了。在运行中很可能要使用到变量,只有数据的更新,才能得到“活水流”,那么怎么在session中赋予新的数据或者获取新数据,使用 tf.placeholder() 创建占位符的op中可以使用 feed 赋值如:sess.run([output], feed_dict={input1:[7.], input2:[2.]}),可以使用 fetch来获取操作的返回值(可以是多个)如: result = sess.run([mul, intermed])。result是多个值。
对于损失函数的构建情况较多(常选择的有均方差,信息熵等),反向优化可以调用相应的操作即可(常选择梯度下降法),下面看一个完整的例子:
import tensorflow as tf
import numpy as np
#1, 数据准备
x_dat=np.float32(np.random.rand(2,100))
y_dat=np.dot([2.0,3.0],x_dat)+5.0
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# 2,变量定义及模型构建
W=tf.Variable(tf.random_uniform([1,2],-0.1,0.1))
b=tf.Variable(tf.zeros([1]))
y_pre=tf.matmul(W,x)+b
# 3,构建损失函数及选择优化器
loss=tf.reduce_mean(tf.square(y_pre-y))
optim=tf.train.GradientDescentOptimizer(0.5)
train_op=optim.minimize(loss)
# 4,初始化变量启动会话,训练
init=tf.initialize_all_variables()
sess=tf.Session()
sess.run(init)
for step in range(1,200):
sess.run([train_op],feed_dict={x:x_dat,y:y_dat })
if step%20 ==0 :
print(sess.run([W,b]))session在运行之前需要构建整个图,除了sesion之外,还有一个可以在图运行中出入其他图的会话InteractiveSession。
1.5多元线性回归
下面是一个多元线性回归的例子,将模型构建函数抽抽离单独实现,在主程序中调用,可以使程序复用性更强。
敲黑板,划重点:
Tip1: out = tf.matmul( w,inputs) + b #注意matmul的参数顺序
Tip2: optmiz = tf.train.GradientDescentOptimizer(0.1) #不收敛需调整变化率,这里0.5不收敛,太小则训练太慢。
Tip3: train_op = optmiz.minimize(loss) #根据loss来确定改变变量的方向及数值
# 多元线性回归
import tensorflow as tf
import numpy as np
# 模型构建函数
def add_layer(inputs, insize, outsize, activation_fun=None):
w = tf.Variable(tf.random_normal([outsize,insize]))
b = tf.Variable(tf.zeros([outsize,1]))
#print(inputs.shape)
out = tf.matmul( w,inputs) + b #注意matmul的参数顺序
if activation_fun is None:
output = out
else:
output = activation_fun(out)
print(output.shape)
return output,w,b
# 1,数据准备
x_dat = np.float32(np.random.rand(5,200))
y_dat = np.dot([2.0, 3.0, 2.0,4.0,9.0],x_dat)+5.0
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# 2,模型构建,变量定义
y_pre,w,b = add_layer(x, 5, 1, activation_fun=None)
# 3,构建损失函数及选择优化器
loss = tf.reduce_mean(tf.square(y-y_pre))
#loss = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_pre),reduction_indices=[1]))
optmiz = tf.train.GradientDescentOptimizer(0.1) #不收敛需调整变化率,这里0.5不收敛,太小则训练太慢。
train_op = optmiz.minimize(loss) #根据loss来确定改变变量的方向及数值
# 4,启动会话,初始化变量,训练
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(2000):
sess.run([train_op],feed_dict={x: x_dat, y: y_dat})
if step % 200 == 0:
print(sess.run([loss,w,b],feed_dict={x: x_dat, y: y_dat}))
结果如下:
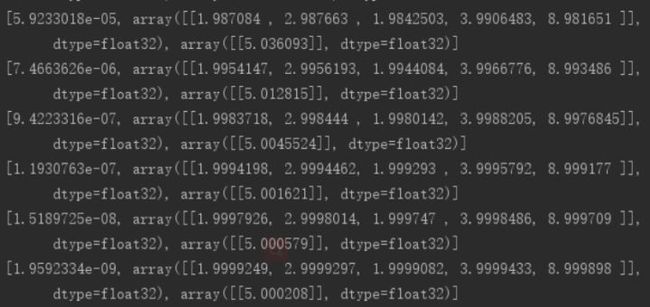
1.6分类的例子:
# 分类
import tensorflow as tf
import numpy as np
import random
# AX=0 相当于matlab中 null(a','r')
def null(a, rtol=1e-5):
u, s, v = np.linalg.svd(a)
rank = (s > rtol * s[0]).sum()
return rank, v[rank:].T.copy()
# 符号函数,之后要进行向量化
def sign(x):
if x > 0:
return 1
elif x == 0:
return 0
elif x < 0:
return -1
# noisy=False,那么就会生成N的dim维的线性可分数据X,标签为y
# noisy=True, 那么生成的数据是线性不可分的,标签为y
def mk_data(N, noisy=False):
rang = [-1, 1]
dim = 5
X = np.random.rand(dim, N) * (rang[1] - rang[0]) + rang[0]
while True:
Xsample = np.concatenate((np.ones((1, dim)), np.random.rand(dim, dim) * (rang[1] - rang[0]) + rang[0]))
k, w = null(Xsample.T)
y = sign(np.dot(w.T, np.concatenate((np.ones((1, N)), X))))
print(y[0][5])
if np.all(y):
break
day=[]
if noisy == True:
idx = random.sample(range(1, N), N / 10)
y[idx] = -y[idx]
for st in range(200):
if(y[0][st]==1):
y1 = [1,0]
else:
y1 = [0,1]
day.append(y1)
da_x = np.float32(X.transpose())
da_y = np.float32(day)
return da_x, da_y, w
# 模型构建函数
def add_layer(insize, outsize, input, function = None):
weight = tf.Variable(tf.random_normal([insize,outsize]))
basize = tf.Variable(tf.zeros([outsize]))
out = tf.matmul(input, weight) + basize
if(function == None):
output = out
else:
output = function(out)
return output
# 1,数据准备
#产生的数据为随机数据,训练结果可能会不稳定
sign = np.vectorize(sign)
x_dat, y_dat, w = mk_data(200)
#x_dat = np.float32(np.random.rand(200,5)*5+10)
#y_dat = np.float32(np.zeros([200,2]))
# x_dat2 = np.float32(np.random.rand(200,5))
# y_dat2 = np.float32(np.zeros([200,2])+1)
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
print(x_dat.shape)
print(y_dat.shape)
# 2,模型构建,变量定义
y_pre = add_layer(5,2,x,tf.nn.softmax)
# 3,构建损失函数及选择优化器
loss = -tf.reduce_sum(y*tf.log(y_pre))
optim = tf.train.GradientDescentOptimizer(0.05)
train_op = optim.minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_pre),tf.argmax(y)),tf.float32))
# 4,启动会话,初始化变量,训练
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(2000):
sess.run([train_op],feed_dict={x:x_dat,y:y_dat})
if step % 100 == 0 :
print(sess.run([loss,accuracy],feed_dict={x:x_dat,y:y_dat}))
print(accuracy.eval(feed_dict={x:x_dat,y:y_dat}))