FPGA 17最佳论文 ESE: Efficient Speech Recognition Engine with Compressed LSTM on FPGA
深鉴科技的 ESE 语音识别引擎的论文在 FPGA 2017 获得了唯一的最佳论文
聚焦于使用 LSTM 进行语音识别的场景,结合深度压缩以及专用处理器架构,使得经过压缩的网络在 FPGA 能够实现超越 Pascal Titan X GPU 一个数量级的能效比。论文中所描述的 ESE 语音识别引擎也是深鉴科技 RNN 处理器产品的原型。
软件方面,我们提出了 Load-balance-aware pruning。除了在纯算法上追求压缩率,还会考虑到最终要多核运行并行加速的时候不同核心之间的负载均衡,这种加速差其实属于最优的方式。
EIE 只能运行卷积神经网络的 FC 层。我们考虑到 RNN 的状态机会整体非常复杂,因为里面会有非常多个矩阵要运转,不仅要支持多路用户,还有里面的非线性函数都有非常大的区别。所以说在整个硬件架构过程做了一个重新设计,能够支持多路用户,也能够支持 RNN,如 LSTM 内部多个矩阵的运转。这样整个系统运转的(速度)都是高得多的一个架构。
通常大家会用一些启发式的算法去发现里面不重要的权重,并将它去除,然后再使用数据来进行 re-train 时能够把它的精确度恢复起来。其中绝对的阈值,做 re-train 时权重增长的幅度均可用来作为启发式算法的判别准则。
由于神经网络中的特征表示比较稀疏,所以这样一种非规则稀疏模型压缩效果往往比大家设计一个小一些的模型效果更好:直接砍 channel 数量,或者一些数学上的分解方式。其他模型压缩的方法有 SVD、Winograd 分解、binary network 等,但相比而言 Deep Compression 整体的性价比会更高。
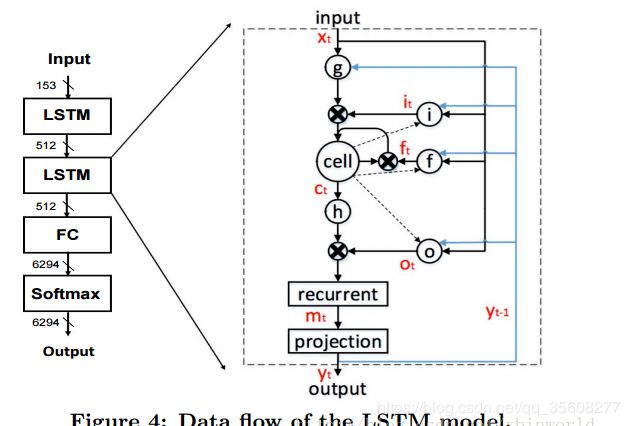
LSTM的结构
它用于得到acoustic output probabilities(音节的输出概率),而且很有可能会占据整个系统中的90%以上的执行时间。所以作者认为要加速LSTM计算。
一个LSTM层里面,实际上是对一个序列x_1 … x_T的递归计算,其中最重要的是有i,f,o三个门控单元,分别叫做input,forget,output gate;一种比较流行的计算模式如下公式所示,也就是Figure 4所代表的含义。
模型压缩
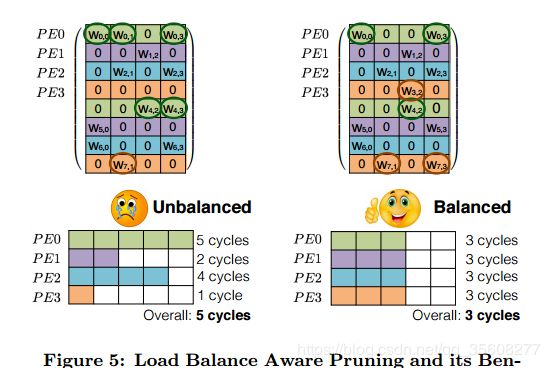
1剪枝pruning与负载均衡Load Balance
基本的剪枝方法和Deep Compression 方法是一致的,
问题:在硬件计算中,如果需要一个批次的计算全部完成,就会因为非零参数严重不均匀,出现快的计算单元等待慢的计算单元执行的情况,造成性能的浪费。
方法:很简单,就是将分组了的参数按照一致的比例去稀疏,而不是原来那样全局稀疏;并通过retraining把损失的精度补回来。这样就做到了负载均衡的稀疏参数了。
利于并行计算
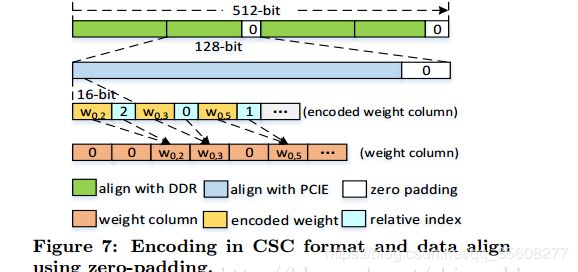
编码Encoding
属于CSC的编码,因为DDR位宽是512bit,所以需要512b对齐,PCIE接口位宽是128bit,所以有128bit对齐的要求。一个weight包含了12bit数据本身+4bit offset,offset表示距离上一个非0值的中间有几个0;
下面这张图是想表示在本文的设计中,一个input data读一次会被计算多次

整个系统的架构图
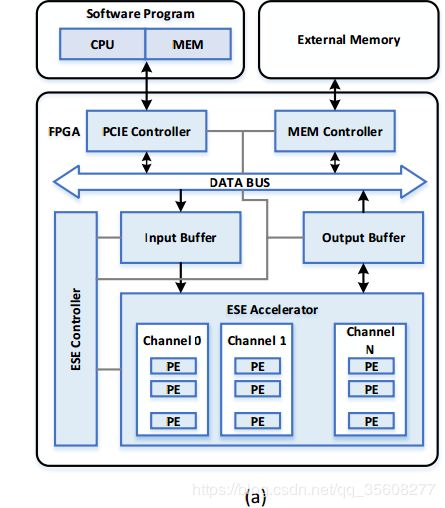
可以看到,有多个channel,每个channel独立计算一个voice vector;在一个channel内部,见右图,有很多个PE,每个PE独立占有一个数据FIFO,而PE的数据来源都是共享的。
整个ESE有32个channel,每个channel有32个PE。
参数会通过指针buffer和weight buffer先把参数连续存在片上RAM中,在解码中,因为知道了某个参数的位置index(通过offset,就可以知道它要和哪个数据相乘),就把需要的数据按序取到FIFO中,在计算的时候就不需要管序号了,只要FIFO和weight buffer中取出来的数据对的上;临时sum结果存在act buffer中,然后每一次乘完后再由Accu累加器把之前的结果和当前结果累加起来;这里有一点,因为一个PE可能需要处理参数矩阵中的多列,所以我猜测act buffer是可以存多个临时结果的。另外剩下的部分就是向量点乘,然后是加法,激活函数这些,完成LSTM整个过程,
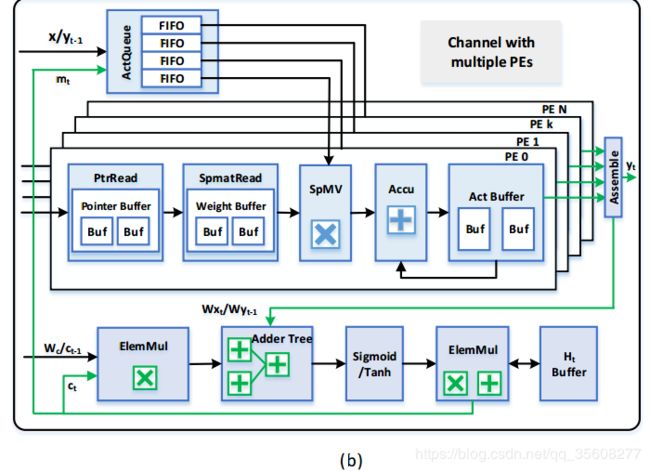
这样看来,处理一个voice数据只有32个PE,也就是32个MAC,需要同时处理32个voice数据才能用满引擎。其实也折射了另外一个问题,sparse计算架构,单个数据处理时很难把并行的PE数量做大(为什么呢?因为目前看到的方案,在sparse计算中,要么就是用参数索引数据,要么用数据索引参数,索引取数据开销比较大;还有一个问题是,一个weight column可以做local reduction,以减少中间计算结果,但是data利用率低,要想data利用率高,中间计算结果就很大,这也是一个矛盾。),还是需要批处理才能提高总的性能。
ref:https://blog.csdn.net/xbinworld/article/details/74012394