Flink SQL-Client探索
SQL-Client 就是一个便于大家学习和写 demo 的一个 Flink-SQL 工具,这次文章的基本流程还是根据社区云邪大佬的公开课,和 官方 wiki 的步骤执行的,这里就大体自己捣鼓了一遍记录一下。
前提准备
从 GitHub 上 clone ververica/sql-training 的 Docker 镜像
地址为:https://github.com/ververica/sql-training 包含如下镜像:

执行 docker-compose up -d加载镜像
执行 docker-compose exec sql-client ./sql-client.sh启动 sql-client 看到松鼠就代表跑起来了!
执行 docker-compose down终止
具体实践
执行show tables;
我们先看一下自带了这几张表
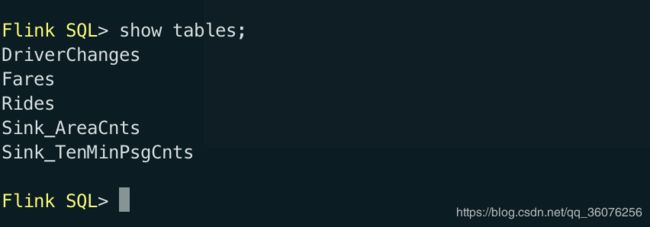
如果你想自己自定义表需要到 sql-training/build-image/training-config.yaml下去自定义表结构,具体操作可以参照官方的文档,这次主要用到 Rides这张表
Rides 的表结构是这样的
| 字段 | 类型 | 含义 |
|---|---|---|
| rideId | BIGINT | 行为 ID(包含两条记录,一条入一条出) |
| taxiId | BIGINT | 出租车 ID |
| isStart | BOOLEAN | 开始 or 结束 |
| lon | FLOAT | 经度 |
| lat | FLOAT | 维度 |
| rideTime | TIMESTAMP | 时间 |
| psgCnt | INT | 乘客数 |
这里我们顺便介绍下training-config.yaml里的结构,sql-client 目前是提供了配置的方式定义表结构,如下:

type:声明是一个source还是sink。update-mode:表里面的数据是什么行为append模式update模式schema:表结构字段的定义。- 具体介绍一下
rideTime事件发生的时间,需要基于这个时间来做一些窗口的操作,因此要把这个字段声明为rowtime字段添加watermark,watermark是Flink里的时间机制,之后的文章再做详细介绍。 connector:主要定义连接配置,像Kafka,Elasticsearch等。format:定义如何去解析定义的格式。
我们先来简单的执行一个 SQL 语句 select * from Rides;看一下 Rides表数据
这时候打开 http://localhost:8081/ (Flink Web)可以发现刚才的 SQL 任务已经跑起来了

同时终端也运行出了结果
需求 1(filter)
现在有这么一个需求,统计出现在纽约的行车记录。这里我们需要进行一个过滤的操作,我们需要有个自定义的 UDF ,具体思路是,表里面有经度和维度这两个字段,通过这个可以来开发一个是否在纽约的 UDF。(这里官方 Demo 里已经帮我们写好了2333)代码都在 sql-training/build-image/sql-udfs下的IsInNYC,继承 ScalarFunction类实现 eval方法。
public class IsInNYC extends ScalarFunction {
// geo boundaries of the area of NYC
private static double LON_EAST = -73.7;
private static double LON_WEST = -74.05;
private static double LAT_NORTH = 41.0;
private static double LAT_SOUTH = 40.5;
public static boolean eval(float lon, float lat) {
return isInNYC(lon, lat);
}
public static boolean isInNYC(float lon, float lat) {
return !(lon > LON_EAST || lon < LON_WEST) &&
!(lat > LAT_NORTH || lat < LAT_SOUTH);
}
}
然后我们执行 mvn clean package得到 UDF 的 jar 包,然后把它扔到 sql-client 的 lib下,然后再去 training-config.yaml下去配置一下 functions

这里官方的 Demo 已经全帮我们做好了,我们去 sql-client 里查看一下

已经有了 isInNYC的 UDF,这样我们就可以用这个 UDF 来筛选出在纽约的行车记录。执行 select * from Rides where isInNYC(lon,lat);

结果如下:
跑出的数据就都是纽约的行车记录了~
需求 2(Group Agg)
计算搭载每种乘客数量的行车事件数,完成无限流上的聚合操作。
也就是搭载1个乘客的行车数,搭载2个乘客的行车数。。
SELECT
psgCnt,
COUNT(*) as cnt
FROM Rides
GROUP BY psgCnt;
结果如下:

需求 3 (Window Agg)
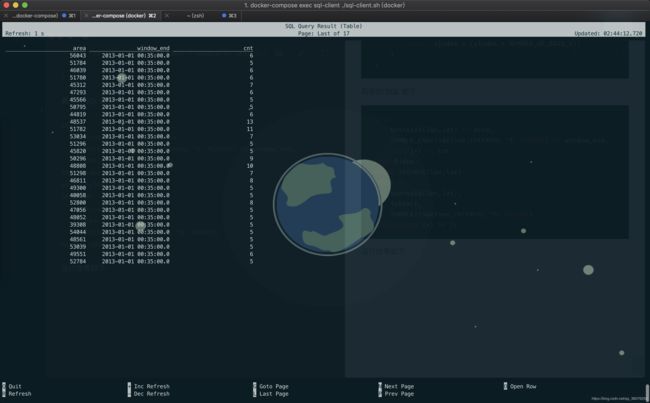
为了持续地监测城市的交通流量,计算每个区域每 5 分钟的进入的车辆数。
我们只关心纽约的区域交通情况,并且只关心至少有 5 辆车子进入的区域。
这里我们还需要区域相关的 UDF ToAreaId
public class ToAreaId extends ScalarFunction {
public static int eval(float lon, float lat) {
return GeoUtils.mapToGridCell(lon, lat);
}
public static int mapToGridCell(float lon, float lat) {
int xIndex = (int) Math.floor((Math.abs(LON_WEST) - Math.abs(lon)) / DELTA_LON);
int yIndex = (int) Math.floor((LAT_NORTH - lat) / DELTA_LAT);
return xIndex + (yIndex * NUMBER_OF_GRID_X);
}
}
具体的 SQL 如下:
SELECT
toAreaId(lon,lat) AS area,
TUMBLE_END(rideTime,INTERVAL '5' MINUTE) AS window_end,
COUNT(*) AS cnt
FROM Rides
WHERE isInNYC(lon,lat)
GROUP BY
toAreaId(lon,lat),
isStart,
TUMBLE(rideTime,INTERVAL '5' MINUTE)
HAVING COUNT(*) >= 5;
运行结果如下:
需求 4(write to Kafka)
将10分钟的搭乘的乘客数写入 Kafka
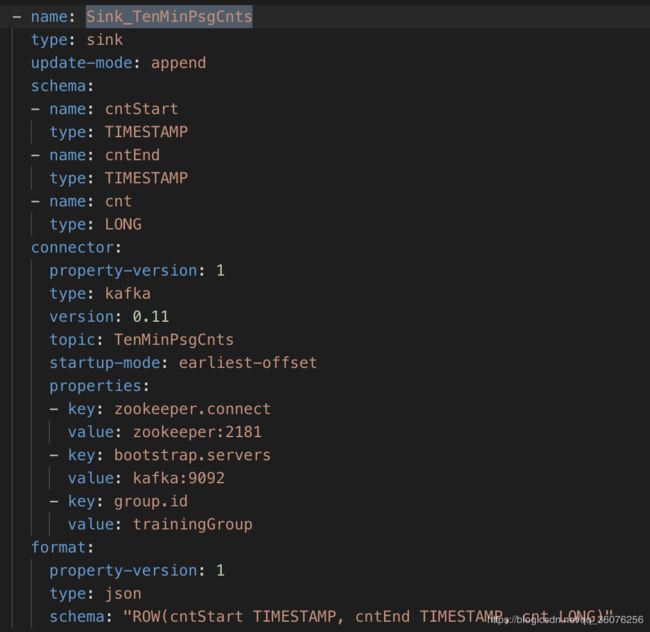
结果表:Sink_TenMinPsgCnts具体的表结构定义如下:
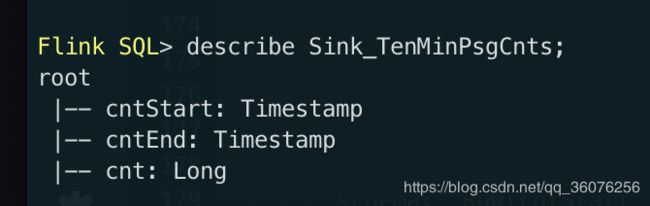
具体的 SQL 如下(因为Sink_TenMinPsgCnts表的 cnt 是 Long 类型需要将 sum 的 cnt 也进行一下转换):
INSERT INTO Sink_TenMinPsgCnts
SELECT
TUMBLE_START(rideTime,INTERVAL '10' MINUTE) AS cntStart,
TUMBLE_END(rideTime,INTERVAL '10' MINUTE) AS cntEnd,
CAST(SUM(psgCnt) AS BIGINT) AS cnt
FROM Rides
GROUP BY TUMBLE(rideTime,INTERVAL '10' MINUTE);
执行docker-compose exec sql-client /opt/kafka-client/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic TenMinPsgCnts --from-beginning可以监听到写入到 Kafka 中的数据,结果如下:

需求 5(write to ES)
从每个区域出发的行车数,写入到 ES
结果表:Sink_AreaCnts具体的表结构定义如下:

具体的 SQL 如下:
INSERT INTO Sink_AreaCnts
SELECT
toAreaId(lon, lat) AS areaId,
COUNT(*) AS cnt
FROM Rides
GROUP BY toAreaId(lon, lat);
之后访问 http://localhost:9200/area-cnts 可以发现index已经创建了

{
"area-cnts":{
"aliases":{
},
"mappings":{
"areacnt":{
"properties":{
"areaId":{
"type":"long"
},
"cnt":{
"type":"long"
}
}
}
},
"settings":{
"index":{
"creation_date":"1557219999010",
"number_of_shards":"5",
"number_of_replicas":"1",
"uuid":"CXFqtgHqQyWi1SoUCicJWA",
"version":{
"created":"6030199"
},
"provided_name":"area-cnts"
}
}
}
}
可以通过 ES 简单的做一下查询 http://localhost:9200/area-cnts/_search?q=areaId:49791

{
"took":62,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"skipped":0,
"failed":0
},
"hits":{
"total":1,
"max_score":1,
"hits":[
{
"_index":"area-cnts",
"_type":"areacnt",
"_id":"49791",
"_score":1,
"_source":{
"areaId":49791,
"cnt":18
}
}
]
}
}
其他更多的实践可以去官方 wiki 查看学习,其他 Flink 的公开课可以去B站学习~,后面有机会我整理下自己学习 Flink 的相关资源,随缘更新哈。