1,网络传输三大问题:packet reordering, packet duplication, and packet erasures (drops).
A straightforward method of dealing with packet drops (and bit errors) is to resend the packet until it is received properly. This requires a way to determine (1) whether the receiver has received the packet and (2) whether the packet it received was the same one the sender sent. The method for a receiver to signal to a sender that it has received a packet is called an acknowledgment, or ACK. In its most basic form, the sender sends a packet and awaits an ACK. When the receiver receives the packet, it sends the ACK. When the sender receives the ACK, it sends another packet, and the process continues. Interesting questions to ask here are (1) How long should the sender wait for an ACK? (2) What if the ACK is lost? (3) What if the packet was received but had errors in it?
As we shall see, the first question turns out to be deep. Deciding how long to wait relates to how long the sender should expect to wait for an ACK. The answer to question 2 is easier: if an ACK is dropped, the sender cannot readily distinguish this case from the case in which the original packet is dropped, so it simply sends the packet again. Of course, the receiver may receive two or more copies in that case, so it must be prepared to handle that situation. As for the third question, It is generally much easier to use codes to detect errors in a large packet (with high probability) using only a few bits than it is to correct them. Simpler codes are typically not capable of correcting errors but are capable of detecting them. That is why checksums and CRCs are so popular. In order to detect errors in a packet, then, we use a form of checksum. When a receiver receives a packet containing an error, it refrains from sending an ACK. Eventually, the sender resends the packet, which ideally arrives undamaged.
Even with the simple scenario presented so far, there is the possibility that the receiver might receive duplicate copies of the packet being transferred. This problem is addressed using a sequence number. Basically, every unique packet gets a new sequence number when it is sent at the source, and this sequence number is carried along in the packet itself. The receiver can use this number to determine whether it has already seen the packet and if so, discard it.
The sender is able to inject a single packet into the communications path but then must stop until it hears the ACK. This protocol is therefore called “stop and wait.” Its throughput performance (data sent on the network per unit time) is proportional to M/R where M is the packet size and R is the round-trip time (RTT), assuming no packets are lost or irreparably damaged in transit. For a fixed-size packet, as R goes up, the throughput goes down. If packets are lost or damaged, the situation is even worse: the “goodput” (useful amount of data transferred per unit time) can be considerably less than the throughput.
Allowing more than one packet to be in the network at a time complicates matters considerably. Now the sender must decide not only when to inject a packet into the network, but also how many. It also must figure out how to keep the timers when waiting for ACKs, and it must keep a copy of each packet not yet acknowledged in case retransmissions are necessary. The receiver needs to have a more sophisticated ACK mechanism: one that can distinguish which packets have been received and which have not. The receiver may need a more sophisticated buffering (packet storage) mechanism—one that allows it to hold “out-of- sequence” packets (those packets that have arrived earlier than those expected because of loss or reordering), unless it simply wants to throw away such packets, which is very inefficient. There are other issues that may not be so obvious. What if the receiver is slower than the sender? If the sender simply injects many packets at a very high rate, the receiver might just drop them because of process- ing or memory limitations. The same question can be asked about the routers in the middle. What if the network infrastructure cannot handle the rate of data the sender and receiver wish to use?
To handle all of these problems, we begin with the assumption that each unique packet has a sequence number, as described earlier. We define a window of packets as the collection of packets (or their sequence numbers) that have been injected by the sender but not yet completely acknowledged (i.e., the sender has not received an ACK for them). We refer to the window size as the number of packets in the window. The term window comes from the idea that if you lined up all the packets sent during a communication session in a long row but had only a small aperture through which to view them, you would see only a subset of them—like peering through a window.
ack和超时重传解决包丢失问题,序列号解决包重复问题,crc校验解决包传输错误问题。并行发送多个包提高吞吐量。

This figure shows the current window of three packets, for a total window size of 3. Packet number 3 has already been sent and acknowledged, so the copy of it that the sender was keeping can now be released. Packet 7 is ready at the sender but not yet able to be sent because it is not yet “in” the window. If we now imagine that data starts to flow from the sender to the receiver and ACKs start to flow in the reverse direction, the sender might next receive an ACK for packet 4. When this happens, the window “slides” to the right by one packet, meaning that the copy of packet 4 can be released and packet 7 can be sent. This movement of the window gives rise to another name for this type of protocol, a sliding window protocol.
The sliding window approach can be used to combat many of the problems described so far. Typically, this window structure is kept at both the sender and the receiver. At the sender, it keeps track of what packets can be released, what packets are awaiting ACKs, and what packets cannot yet be sent. At the receiver, it keeps track of what packets have already been received and acknowledged, what packets are expected (and how much memory has been allocated to hold them), and which packets, even if received, will not be kept because of limited memory. Although the window structure is convenient for keeping track of data as it flows between sender and receiver, it does not provide guidance as to how large the window should be, or what happens if the receiver or network cannot handle the sender’s data rate.
使用窗口(缓冲buffer)解决发送速度和ack速度不一致问题。
To handle the problem that arises when a receiver is too slow relative to a sender, we introduce a way to force the sender to slow down when the receiver cannot keep up. This is called flow control and is usually handled in one of two ways. One way, called rate-based flow control, gives the sender a certain data rate allocation and ensures that data is never allowed to be sent at a rate that exceeds the allocation. This type of flow control is most appropriate for streaming applications and can be used with broadcast and multicast delivery .
The other predominant form of flow control is called window-based flow control and is the most popular approach when sliding windows are being used. In this approach, the window size is not fixed but is instead allowed to vary over time. To achieve flow control using this technique, there must be a method for the receiver to signal the sender how large a window to use. This is typically called a window advertisement, or simply a window update. This value is used by the sender (i.e., the receiver of the window advertisement) to adjust its window size. Logically, a window update is separate from the ACKs we discussed previously, but in practice the window update and ACK are carried in a single packet, meaning that the sender tends to adjust the size of its window at the same time it slides it to the right.
发送方和接收方可以协商窗口(buffer)大小。
This approach works fine for protecting the receiver, but what about the network in between? We may have routers with limited memory between the sender and the receiver that have to contend with slow network links. When this happens, it is possible for the sender’s rate to exceed a router’s ability to keep up, leading to packet loss. This is addressed with a special form of flow control called congestion control. Congestion control involves the sender slowing down so as to not overwhelm the network between itself and the receiver.
木桶原理:发送速度同时要考虑发送方和接收方中间的所有路由器的buffer大小。
One of the most important performance issues the designer of a retransmission- based reliable protocol faces is how long to wait before concluding that a packet has been lost and should be resent. Stated another way, What should the retransmission timeout be? Intuitively, the amount of time the sender should wait before resending a packet is about the sum of the following times: the time to send the packet, the time for the receiver to process it and send an ACK, the time for the ACK to travel back to the sender, and the time for the sender to process the ACK. Unfortunately, in practice, none of these times are known with certainty. To make matters worse, any or all of them vary over time as additional load is added to or removed from the end hosts or routers.
Because it is not practical for the user to tell the protocol implementation what the values of all the times are (or to keep them up-to-date) for all circumstances, a better strategy is to have the protocol implementation try to estimate them. This is called round-trip-time estimation and is a statistical process. Basically, the true RTT is likely to be close to the sample mean of a collection of samples of RTTs. Note that this average naturally changes over time (it is not stationary), as the paths taken through the network may change.
Once some estimate of the RTT is made, the question of setting the actual timeout value, used to trigger retransmissions, remains. If we recall the definition of a mean, it can never be the extreme value of a set of samples (unless they are all the same). So, it would not be sensible to set the retransmission timer to be exactly equal to the mean estimator, as it is likely that many actual RTTs will be larger, thereby inducing unwanted retransmissions. Clearly, the timeout should be set to something larger than the mean, but exactly what this relationship is (or even if the mean should be directly used) is not yet clear. Setting the timeout too large is also undesirable, as this leads back to letting the network go idle, reducing throughput.
抽样分析一个包从发送到收到ack的平均时间,作为接受ack超时重传包的参考值。
TCP does not interpret the contents of the bytes in the byte stream at all. It has no idea if the data bytes being exchanged are binary data, ASCII characters, EBCDIC characters, or something else. The interpretation of this byte stream is up to the applications on each end of the connection.
tcp不关心包的内容
TCP provides reliability using specific variations on the techniques just described. Because it provides a byte stream interface, TCP must convert a sending application’s stream of bytes into a set of packets that IP can carry. This is called packetization. These packets contain sequence numbers, which in TCP actually represent the byte offsets of the first byte in each packet in the overall data stream rather than packet numbers. This allows packets to be of variable size during a transfer and may also allow them to be combined, called repacketization. The application data is broken into what TCP considers the best-size chunks to send, typically fitting each segment into a single IP-layer datagram that will not be fragmented. This is different from UDP, where each write by the application usually generates a UDP datagram of that size (plus headers). The chunk passed by TCP to IP is called a segment
tcp把数据流拆分成包发送,每个包包含序列号,表示此包的第一个字节在整个数据流中的偏移,方便在必要时重新拆包打包。
TCP maintains a mandatory checksum on its header, any associated application data, and fields from the IP header. This is an end-to-end pseudo-header checksum whose purpose is to detect any bit errors introduced in transit. If a segment arrives with an invalid checksum, TCP discards it without sending any acknowledgment for the discarded packet. The receiving TCP might acknowledge a previous (already acknowledged) segment, however, to help the sender with its congestion control computations
tcp每个包都有checksum,收到校验值错误的包直接丢弃,或者ack上一个包帮助发送者重传。
When TCP sends a group of segments, it normally sets a single retransmission timer, waiting for the other end to acknowledge reception. TCP does not set a different retransmission timer for every segment. Rather, it sets a timer when it sends a window of data and updates the timeout as ACKs arrive. If an acknowledgment is not received in time, a segment is retransmitted.
tcp以窗口为单位设置重传超时时长。
When TCP receives data from the other end of the connection, it sends an acknowledgment. This acknowledgment may not be sent immediately but is normally delayed a fraction of a second. The ACKs used by TCP are cumulative in the sense that an ACK indicating byte number N implies that all bytes up to number N (but not including it) have already been received successfully. This provides some robustness against ACK loss—if an ACK is lost, it is very likely that a subsequent ACK is sufficient to ACK the previous segments.
收到第100个包的ack,隐含表示前面99个包已经全部收到。ack可以累计到一定量再发送,提高效率。
TCP provides a full-duplex service to the application layer. This means that data can be flowing in each direction, independent of the other direction. There- fore, each end of a connection must maintain a sequence number of the data flow- ing in each direction. Once a connection is established, every TCP segment that contains data flowing in one direction of the connection also includes an ACK for segments flowing in the opposite direction. Each segment also contains a win- dow advertisement for implementing flow control in the opposite direction. Thus, when a TCP segment arrives on a connection, the window may slide forward, the window size may change, and new data may have arrived. a fully active TCP connection is bidirectional and symmetric; data can flow equally well in either direction.
tcp是全双工协议,一旦连接建立,client和server可以独立的收发数据,client可以主动询问server,server也可以发传单给client。每个发送包都包含反方向的ack。
非常重要的常识:tcp是全双工协议!!!
Using sequence numbers, a receiving TCP discards duplicate segments and reorders segments that arrive out of order. Recall that any of these anomalies can happen because TCP uses IP to deliver its segments, and IP does not provide duplicate elimination or guarantee correct ordering. Because it is a byte stream protocol, however, TCP never delivers data to the receiving application out of order. Thus, the receiving TCP may be forced to hold on to data with larger sequence numbers before giving it to an application until a missing lower-sequence-numbered segment (a “hole”) is filled in.
tcp是有序发送的,但是ip没有顺序,所以接收方需要重新排序。


Each TCP header contains the source and destination port number. These two values, along with the source and destination IP addresses in the IP header, uniquely identify each connection. The combination of an IP address and a port number is sometimes called an endpoint or socket in the TCP literature.
原来所谓socket就是一个ip和端口的组合!!!
The Sequence Number field identifies the byte in the stream of data from the sending TCP to the receiving TCP that the first byte of data in the containing segment represents. If we consider the stream of bytes flowing in one direction between two applications, TCP numbers each byte with a sequence number. This sequence number is a 32-bit unsigned number that wraps back around to 0 after reaching (232) − 1. Because every byte exchanged is numbered, the Acknowledgment Number field (also called the ACK Number or ACK field for short) contains the next sequence number that the sender of the acknowledgment expects to receive. This is therefore the sequence number of the last successfully received byte of data plus 1. This field is valid only if the ACK bit field (described later in this section) is on, which it usually is for all but initial and closing segments. Sending an ACK costs nothing more than sending any other TCP segment because the 32-bit ACK Number field is always part of the header, as is the ACK bit field.
序列号表示数据域的第一个字节在整个字节流中的偏移,ack比当前收到的最大字节数大1,表示下一个期望的字节偏移,只有ack标识位为1 ack字段才有效。
When a new connection is being established, the SYN bit field is turned on in the first segment sent from client to server. Such segments are called SYN segments, or simply SYNs. The Sequence Number field then contains the first sequence number to be used on that direction of the connection for subsequent sequence numbers and in returning ACK numbers (recall that connections are all bidirectional). Note that this number is not 0 or 1 but instead is another number, often randomly chosen, called the initial sequence number (ISN). The reason for the ISN not being 0 or 1 is a security measure. The sequence number of the first byte of data sent on this direction of the connection is the ISN plus 1 because the SYN bit field consumes one sequence number. As we shall see later, consuming a sequence number also implies reliable delivery using retransmission. Thus, SYNs and application bytes (and FINs, which we will see later) are reliably delivered. ACKs, which do not consume sequence numbers, are not.
建立连接的第一个包SYN标识位为1,表示同步序列号,初始序列号ISN由于安全原因是随机生成的,发送的第一个字节的序列号是ISN+1,SYN本身也占用一个字节的序列号,只要占用序列号里的字节,就能从ack里知道有没有发送成功。
TCP can be described as “a sliding window protocol with cumulative positive acknowledgments.” The ACK Number field is constructed to indicate the largest byte received in order at the receiver (plus 1). For example, if bytes 1–1024 are received OK, and the next segment contains bytes 2049–3072, the receiver cannot use the regular ACK Number field to signal the sender that it received this new segment. Modern TCPs, however, have a selective acknowledgment (SACK) option that allows the receiver to indicate to the sender out-of-order data it has received correctly. When paired with a TCP sender capable of selective repeat, a significant performance benefit may be realized.
选择性ack可以提高重传的效率。
The Header Length field gives the length of the header in 32-bit words. This is required because the length of the Options field is variable. With a 4-bit field, TCP is limited to a 60-byte header. Without options, however, the size is 20 bytes.
4bit的header length表示以32bit为单位的长度,最长60字节。
8个标识位含义:
- CWR—Congestion Window Reduced (the sender reduced its sending rate);
- ECE—ECN Echo (the sender received an earlier congestion notification);
- URG—Urgent (the Urgent Pointer field is valid—rarely used)
- ACK—Acknowledgment (the Acknowledgment Number field is valid— always on after a connection is established);
- PSH—Push (the receiver should pass this data to the application as soon as possible—not reliably implemented or used);
- RST—Reset the connection (connection abort, usually because of an error);
- SYN—Synchronize sequence numbers to initiate a connection;
- FIN—The sender of the segment is finished sending data to its peer;
TCP’s flow control is provided by each end advertising a window size using the Window Size field. This is the number of bytes, starting with the one specified by the ACK number, that the receiver is willing to accept. This is a 16-bit field, limiting the window to 65,535 bytes, and thereby limiting TCP’s throughput performance. The Window Scale option that allows this value to be scaled, providing much larger windows and improved performance for high-speed and long-delay networks.
window size表示从收到的最大ack开始能连续发送多少字节,最大16k,有一个选项可以指定将window size向右偏移多少位,直接大幅提升window size,进而提高发送效率。
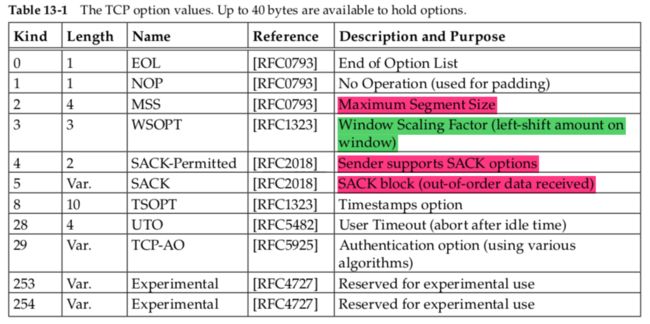
The most common Option field is the Maximum Segment Size option, called the MSS. Each end of a connection normally specifies this option on the first segment it sends (the ones with the SYN bit field set to establish the connection). The MSS option specifies the maximum-size segment that the sender of the option is willing to receive in the reverse direction.
最常用的option之一是MSS,指定希望收到的最大包大小。

上面都是做铺垫的,正题是tcp连接建立和断开的过程,这张图描述的非常清楚了。
建立tcp连接的过程:
- The active opener (normally called the client) sends a SYN segment (i.e., a TCP/IP packet with the SYN bit field turned on in the TCP header) specifying the port number of the peer to which it wants to connect and the client’s initial sequence number or ISN(c). It typically sends one or more options at this point. This is segment 1.
- The server responds with its own SYN segment containing its initial sequence number (ISN(s)). This is segment 2. The server also acknowledges the client’s SYN by ACKing ISN(c) plus 1. A SYN consumes one sequence number and is retransmitted if lost.
- The client must acknowledge this SYN from the server by ACKing ISN(s) plus 1. This is segment 3.
These three segments complete the connection establishment. This is often called the three-way handshake. Its main purposes are to let each end of the connection know that a connection is starting and the special details that are carried as options, and to exchange the ISNs.
这就是传说中的三次握手,主要目的是告诉双方连接已建立,交换ISN,以及交换window size,MSS之类的参数。
Either end can initiate a close operation, and simultaneous closes are also supported but are rare. Traditionally, it was most common for the client to initiate a close. However, other servers (e.g., Web servers) initiate a close after they have completed a request. Usually a close operation starts with an application indicating its desire to terminate its connection (e.g., using the close() system call). The closing TCP initiates the close operation by sending a FIN segment (i.e., a TCP segment with the FIN bit field set). The complete close operation occurs after both sides have completed the close:
The active closer sends a FIN segment specifying the current sequence number the receiver expects to see (K). The FIN also includes an ACK for the last data sent in the other direction (L).
The passive closer responds by ACKing value K + 1 to indicate its successful receipt of the active closer’s FIN. At this point, the application is notified that the other end of its connection has performed a close. Typically this results in the application initiating its own close operation. The passive closer then effectively becomes another active closer and sends its own FIN. The sequence number is equal to L.
To complete the close, the final segment contains an ACK for the last FIN.
Note that if a FIN is lost, it is retransmitted until an ACK for it is received.
While it takes three segments to establish a connection, it takes four to terminate one. It is also possible for the connection to be in a half-open state, although this is not common. This reason is that TCP’s data communications model is bidirectional, meaning it is possible to have only one of the two directions operating. The half-close operation in TCP closes only a single direction of the data flow. Two half-close operations together close the entire connection. The rule is that either end can send a FIN when it is done sending data. When a TCP receives a FIN, it must notify the application that the other end has terminated that direction of data flow. The sending of a FIN is normally the result of the application issuing a close operation, which typically causes both directions to close.
连接可以处于半关闭状态,发送完数据的一方可以关闭发送连接,然后只接受数据回复ack。

最最重要的一个问题来了:ISN的作用以及随机生成的原因
When a connection is open, any segment with the appropriate two IP addresses and port numbers is accepted as valid provided the sequence number is valid (i.e., within the window) and the checksum is OK. This brings up the question of whether it might be possible to have TCP segments being routed through the net- work that could show up later and disrupt a connection. This concern is addressed by careful selection of the ISN, which we now investigate.
一对socket之间发送的数据包只要序列号和校验值是合法的,数据包就是合法的,如果有个包迷路了,同一对socket断开连接之后又建立了连接,这时候那个迷路的包又找到家了,它也是合法的,那就会乱套了,解决这个问题就靠ISN了。
Before each end sends its SYN to establish the connection, it chooses an ISN for that connection. The ISN should change over time, so that each connection has a different one. [RFC0793] specifies that the ISN should be viewed as a 32-bit counter that increments by 1 every 4μs. The purpose of doing this is to arrange for the sequence numbers for segments on one connection to not overlap with sequence numbers on a another (new) identical connection. In particular, new sequence numbers must not be allowed to overlap between different instantiations (or incarnations) of the same connection.
The idea of different instantiations of the same connection becomes clear when we recall that a TCP connection is identified by a pair of endpoints, creat- ing a 4-tuple of two address/port pairs. If a connection had one of its segments delayed for a long period of time and closed, but then opened again with the same 4-tuple, it is conceivable that the delayed segment could reenter the new connection’s data stream as valid data. This would be most troublesome. By taking steps to avoid overlap in sequence numbers between connection instantiations, we can try to minimize this risk. It does suggest, however, that an application with a very great need for data integrity should employ its own CRCs or checksums at the application layer to ensure that its own data has been transferred without error. This is generally good practice in any case, and it is commonly done for large files.
ISN根据规范是一个每4微妙加1的计数器,每发送一个包序列化+1,发送速度肯定没有ISN 4微妙加1速度快,所以断开再连上时,新的ISN会比之前最大的SN大很多,确保同一对socket断开又连上之后ISN不会重叠,收到上次连接迷路的包就能从ISN上判断它不合法,直接丢弃。
As we shall see, knowing the connection 4-tuple as well as the currently active window of sequence numbers is all that is required to form a TCP segment that is considered valid to a communicating TCP endpoint. This represents a form of vulnerability for TCP: anyone can forge a TCP segment and, if the sequence numbers, IP addresses, and port numbers are chosen appropriately, can interrupt a TCP connection [RFC5961]. One way of repelling this is to make the initial sequence number (or ephemeral port number [RFC6056]) relatively hard to guess. Another is encryption
ISN另一个重要作用是安全,知道了两个socket和ISN之后就可以仿制出合法的包,所以ISN要随机生成,client的port一般也是随机选择的,正式这个原因。
Linux goes through a fairly elaborate process to select its ISNs. It uses a clock-based scheme but starts the clock at a random offset for each connection. The random offset is chosen as a cryptographically hashed function on the connection identifier (4-tuple). A secret input to the hash function changes every 5 minutes. Of the 32 bits in the ISN, the top-most 8 bits are a sequence number of the secret, and the remaining bits are generated by the hash. This produces an ISN that is difficult to guess, but also one that increases over time.
linux下的ISN生成机制
常用option