PYTORCH与TENSORFLOW:哪种框架最适合您的深度学习项目?
如果您正在阅读本文,则可能已经开始了深度学习的旅程 。为了帮助开发这些架构,诸如Google,Facebook和Uber之类的技术巨头已经发布了适用于Python深度学习环境的各种框架,从而使学习,构建和训练多样化的神经网络变得更加容易。
在本文中,我们将研究两个流行的框架并进行比较:PyTorch与TensorFlow。
简要地比较一下,最常用和依赖的Python框架TensorFlow和PyTorch。
Google的TensorFlow
TensorFlow是由Google开发人员创建并于2015年发布的开源深度学习框架。
可以看论文“ TensorFlow:异构分布式系统上的大规模机器学习”。
FACEBOOK的PYTORCH
PyTorch是最新的深度学习框架之一,由Facebook团队开发,于2017年在GitHub上开源。您可以在研究论文“ PyTorch中的自动差异化”中了解有关其开发的更多信息。
PyTorch有优点: 简单,易用,动态计算图和有效的内存使用,科研工作者用的比较多,我们将在后面详细讨论。
我们可以使用TENSORFLOW和PYTORCH开发什么?
最初,神经网络用于解决简单的分类问题,例如手写数字识别或使用摄像头识别汽车的车牌。
由于有了最新的框架和NVIDIA的GPU,我们可以更快的训练神经网络,并解决更复杂的问题。
例如:在TensorFlow和PyTorch中实现的卷积神经网络在IMAGENET数据集上达到最优的性能。训练后的模型可以用于不同的应用程序,例如对象检测,图像语义分割等。
尽管可以在任何这些框架上实现神经网络的体系结构,但结果不一定是一样的。训练过程中有很多参数取决于框架。
例如,如果您要在PyTorch上训练数据集,则可以在GPU在CUDA(C ++后端)上运行时使用GPU来加速训练过程。在TensorFlow中,您可以访问GPU,但它使用其自身的内置GPU加速功能,因此训练这些模型的时间是依赖于您选择的框架的。
TENSORFLOW热门项目
Magenta :一个开源研究项目,探讨机器学习的奥义。(https://magenta.tensorflow.org/)
Sonnet:Sonnet是一个在TensorFlow之上构建的库,用于构建复杂的神经网络。(https://sonnet.dev/)
Ludwig:Ludwig是无需编写代码即可训练和测试深度学习模型。(https://uber.github.io/ludwig/)
热门PYTORCH项目
CheXNet:具有深度学习功能的胸部X射线放射学家级肺炎检测。(https://stanfordmlgroup.github.io/projects/chexnet/)
PYRO :Pyro是一种用Python编写的通用概率编程语言(PPL),并在后端由PyTorch支持。(https://pyro.ai/)
Horizon:用于强化学习的平台(Applied RL)(https://horizonrl.com)
这些是在TensorFlow和PyTorch之上构建的一些框架和项目。您可以在Github以及TF和PyTorch的官方网站上找到更多信息。
PYTORCH和TENSORFLOW的比较
PyTorch和TensorFlow之间的主要区别在于它们执行代码的方式。这两个框架处理的数据都是张量。您可以将张量想象为下图所示的多维数组。
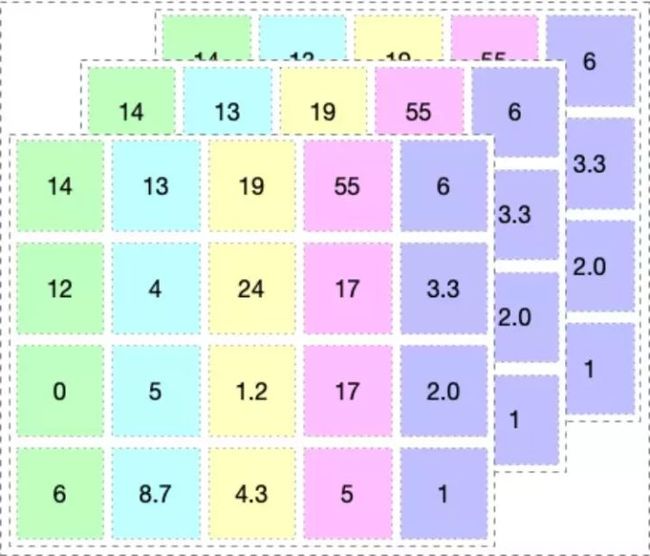
1.机制:动态与静态图定义
TensorFlow 框架由两个核心构建模块组成:
- 一个用于定义计算图以及在各种不同硬件上执行这些图的运行时间的软件库。
- 一个具有许多优点的计算图(后面很快就会介绍这些优点)。
计算图是一种将计算描述成有向图的抽象方式。图是一种由节点(顶点)和边构成的数据结构,是由有向的边成对连接的顶点的集合。
当你在 TensorFlow 中运行代码时,计算图是以静态方式定义的。与外部世界的所有通信都是通过tf.Sessionobject 和tf.Placeholder 执行,它们是在运行时会被外部数据替换的张量。例如,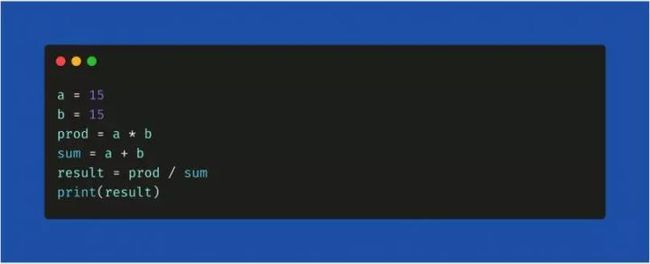
下图是 TensorFlow 中运行代码之前以静态方式生成计算图的方式。计算图的核心优势是能实现并行化或依赖驱动式调度(dependency driving scheduling),这能让训练速度更快,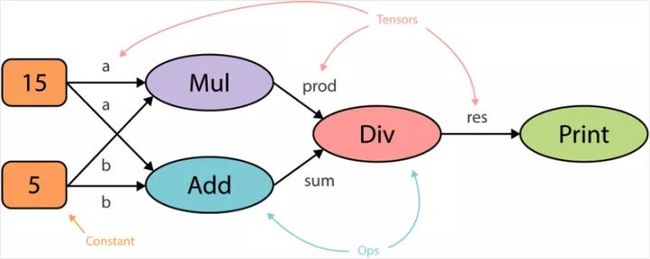
类似于 TensorFlow,PyTorch 也有两个核心模块:
- 计算图的按需和动态构建
- Autograd:执行动态图的自动微分
可以在下图中看到,图会随着执行过程而改变和执行节点,没有特殊的会话接口或占位符。整体而言,这个框架与 Python 语言的整合更紧密,大多数时候感觉更本地化。因此,PyTorch 是更 Python 化的框架,而 TensorFlow 则感觉完全是一种
根据你所用的框架,在软件领域有很大的不同。TensorFlow 提供了使用 TensorFlow Fold 库实现动态图的方式,而 PyTorch 的动态图是内置的。分布式训练PyTorch 和 TensorFlow 的一个主要差异特点是数据并行化。
2.分布式培训
PyTorch 优化性能的方式是利用 Python 对异步执行的本地支持。而用 TensorFlow 时,你必须手动编写代码,并微调要在特定设备上运行的每个操作,以实现分布式训练。但是,你可以将 PyTorch 中的所有功能都复现到 TensorFlow 中,但这需要做很多工作。
下面的代码片段展示了用 PyTorch 为模型实现分布式训练的
3.可视化
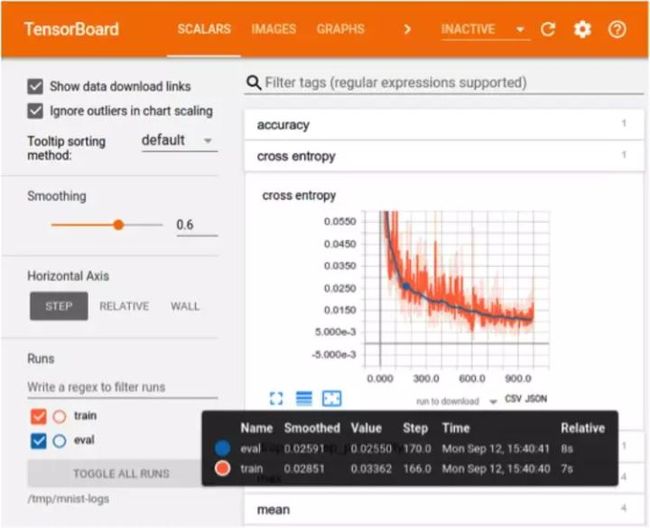
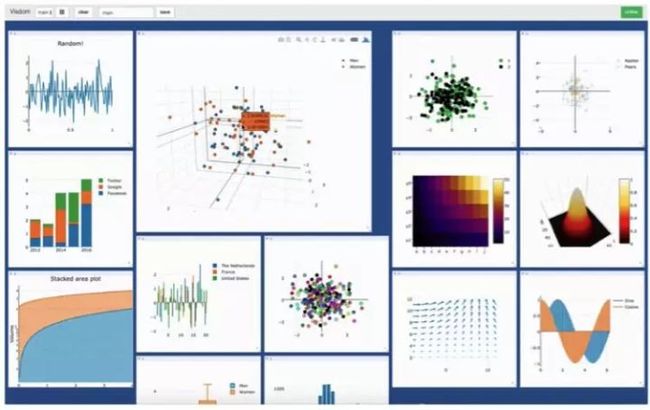
在训练过程的可视化方面,TensorFlow 更有优势。可视化能帮助开发者跟踪训练过程以及实现更方便的调试。TensorFlow 的可视化库名为 TensorBoard。PyTorch 开发者则使用 Visdom,但是 Visdom 提供的功能很简单且有限,所以 TensorBoard 在训练过程可视化方面更好。TensorBoard 的特性:
- 跟踪和可视化损失和准确度等指标
- 可视化计算图(操作和层)
- 查看权重、偏差或其它张量随时间变化的直方图
- 展示图像、文本和音频数据
- 分析 TensorFlow 程序
Visdom 的特性
- 处理回调
- 绘制图表和细节
- 管理环境
4.生产部署
在将训练好的模型部署到生产方面,TensorFlow 显然是赢家。我们可以直接使用 TensorFlow serving 在 TensorFlow 中部署模型,这是一种使用了 REST Client API 的框架。
使用 PyTorch 时,在最新的 1.0 稳定版中,生产部署要容易一些,但它没有提供任何用于在网络上直接部署模型的框架。你必须使用 Flask 或 Django 作为后端服务器。所以,如果要考虑性能,TensorFlow serving 可能是更好的选择。
5.在PYTORCH和TENSORFLOW中定义一个简单的神经网络
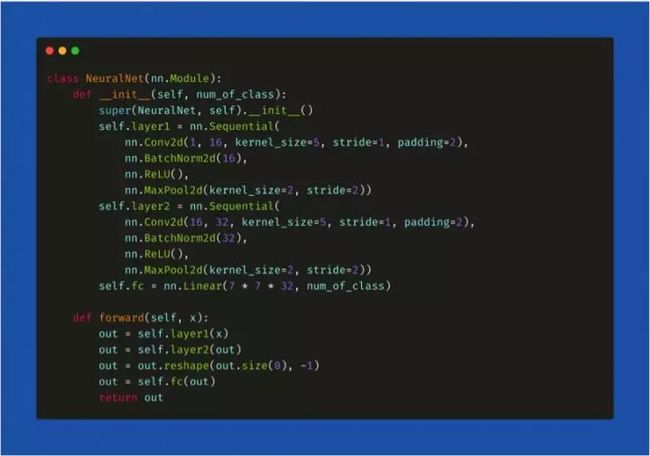
我们比较一下如何在 PyTorch 和 TensorFlow中构建神经网络。在 PyTorch 中,神经网络是一个类,我们可以使用 torch.nn 软件包导入构建架构所必需的层。所有的层都首先在__init__() 方法中声明,然后在 forward() 方法中定义输入 x 在网络所有层中的遍历方式。最后,我们声明一个变量模型并将其分配给定义的架构(model = NeuralNet())。
在Tensorflow中定义一个简单的神经网络
近期 Keras 被合并到了 TensorFlow 库中,这是一个使用 TensorFlow 作为后端的神经网络框架。从那时起,在 TensorFlow 中声明层的句法就与 Keras 的句法类似了。
首先,我们声明变量并将其分配给我们将要声明的架构类型,这里的例子是一个 Sequential()架构。接下来,我们使用 model.add()方法以序列方式直接添加层。层的类型可以从tf.layers导入,如下代码片段所示:
PYTORCH和TENSORFLOW的优缺点
TENSORFLOW的优点:
- 简单的内置高级API。
- 使用Tensorboard 可视化训练。
- 通过 TensorFlow serving 容易实现生产部署。
- 支持移动平台简单
- 开源。
- 良好的文档和社区支持。
TENSORFLOW缺点:
- 静态图。
- 调试方法。
- 难以快速更改。
PYTORCH优点:
- 类 Python 的代码
- 动态图
- 轻松快速的编辑
- 良好的文档和社区支持
- 开源
- 很多项目都使用 PyTorch
PYTORCH缺点:
- 可视化需要第三方。
- 生产所需的API服务器。
PYTORCH和TF安装,版本,更新
最近PyTorch和TensorFlow发布了新版本,PyTorch 1.0(第一个稳定版本)和TensorFlow 2.0 (在Beta中运行)。这两个版本都有重大更新和新功能,使培训过程更加高效,流畅和强大。
要在您的计算机上安装这些框架的最新版本,您可以从源代码构建或从pip安装
PYTORCH安装
● macOS和Linux
pip3 install torch torchvision
● Windows
pip3 install https://download.pytorch.org/whl/cu90/torch-1.1.0-cp36-cp36m-win_amd64.whl
pip3 install https://download.pytorch.org/whl/cu90/torchvision-0.3.0-cp36-cp36m-win_amd64.whl
TENSORFLOW安装
● macOS,Linux和Windows
# Current stable release for CPU-only
pip install tensorflow
# Install TensorFlow 2.0 Beta
pip install tensorflow==2.0.0-beta1
TENSORFLOW VS PYTORCH:我的推荐
TensorFlow 是一种非常强大和成熟的深度学习库,具有很强的可视化功能和多个用于高级模型开发的选项。
它有面向生产部署的选项,并且支持移动平台。另一方面,PyTorch 框架还很年轻,拥有更强的社区动员,而且它对 Python 友好。
我的建议是如果你想更快速地开发和构建 AI 相关产品,TensorFlow 是很好的选择。建议研究型开发者使用 PyTorch,因为它支持快速和动态的训练。
译