数据库调优实践案例
数据库作为基础数据支撑层的核心部分,对于应用和平台整体性能表现有着决定性的影响。因此,数据库性能优化可以说是最考验DBA能力的工作了。本文我们就由数据库内核专家来,以 SequoiaDB 5.0 内核的部分性能优化为例,带领各位数据库爱好者揭开数据库性能优化的“神秘面纱”。
通常优化思路:
提高数据库性能的方式有很多,总结起来从易到难无外乎如下三种:
- 最简单直观的是通过使用数据库提供的工具,找到SQL语句执行中消耗资源最大或耗时最长的部分,也即性能瓶颈。然后通过调整数据本身或数据库配置解决这些性能瓶颈。比如说发现数据分布不均匀,我们可以通过切分数据(split)达到数据均衡(rebalance);再比如我们发现某些网络时延较长,在确定不是网络本身的问题后,我们可以通过调整连接端口数和通讯处理线程提高数据库消息处理能力;再比如单点磁盘IO过多,需要调整缓存或调整部分数据的分布。SequoiaDB提供了图形化的性能诊断工具SequoiaPerf,可以协助用户完成上述的调优。
- 业界经验证明,效果最明显,成本最低的方法其实是SQL语句的调优,通常是通过理解分析访问计划,对比实际语句执行时的开销来判断语句是否优化。比如对比索引读和表读的个数判断否创建使用了合适的索引;对比访问计划的打分和时间执行开销来判断表/集合/索引的统计信息是否反映当前最新的状态;观察锁等待时间来判断系统中是否存在应用持锁时间过长阻塞其他应用而;对比join两边表的返回数据集以及使用的过滤条件判断使用join的类型是否合理。SequoiaDB 提供了完善监控功能,通过结合图形化的sequoiaPerf 与snapshot,用户可以相对容易的定位和实现SQL语句的调优。
- 前两种方式通常是DBA或应用开发者就能完成的任务,第三种是数据库内核的优化。这主要是数据库厂商在不断的实践中,通过各种相对底层的性能诊断工具,定位和优化数据引擎的性能。
内核调优
在数据库内核的调优中,开发人员通常会跑一定的workload或benchmark,使用操作系统或三方提供的工具,持续监控系统各类资源的使用情况,在高并发系统中,也会关注并发控制中使用的锁和原子变量带来的开销。下面我们通过TPCC场景下的逐步优化SequoiaDB内核的过程,来了解我们是如何使用工具来定位优化数据引擎的。
1. CPU usage
我们常使用两大神器观察CPU使用情况:top 和 perf。top能动态的显示linux 系统中各进程/线程以及内存使用的汇总信息。
/
以上图为例,我们知道这台机器的CPU基本上被用满了,其中系统CPU占13%,用户CPU占81.7%。如果CPU出现过多的空闲,往往意味着系统要么还可以增加负载提高性能,要么有瓶颈导致CPU上不去,比如说并发不好,太多等待,串行化太多。在这个例子中,我们没有看到等IO的情况,idle的比例也非常小,这都是好的现象。在CPU用满的情况下,优化系统也意味着要尽量减少开销,让系统能尽可能的跑多点任务。需要注意的是,如果系统CPU过高,意味着CPU不是在执行跟程序逻辑相关的指令,也可以理解为是overhead。根据以往的经验,这里系统CPU占比还是偏高。使用线程模式,更进一步分析,我们可以看到潜在的问题可能是在系统调用,context switch和并发控制的mutex上。
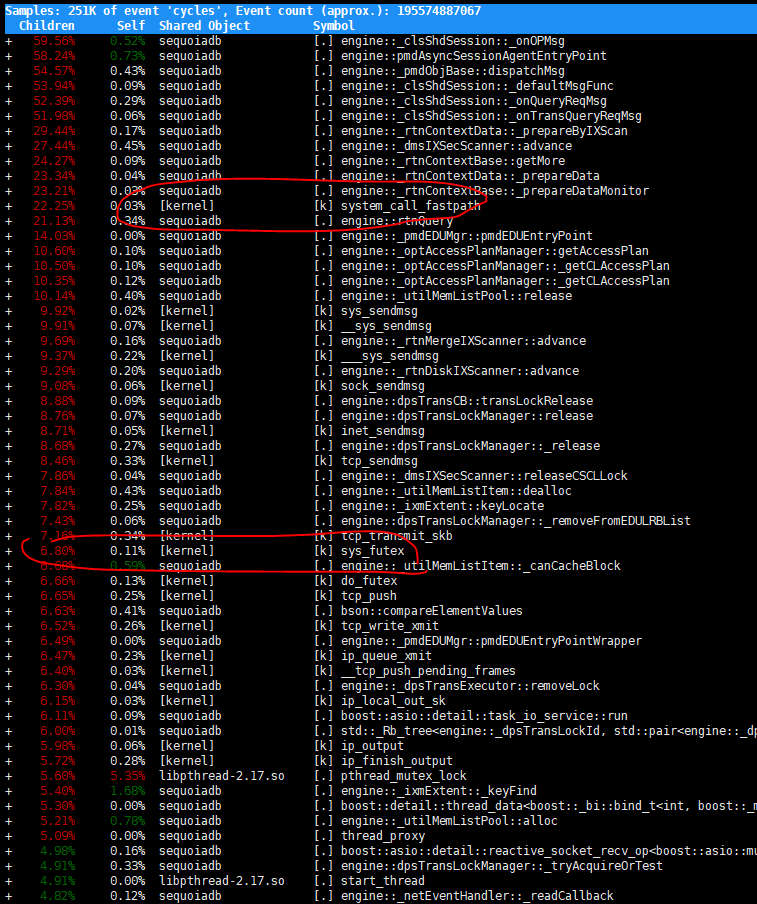
至于更精确的定位,就要perf出马了。注意的是SequoiaDB 的代码编译时加入了debug symbol,这样会带来一定的性能损失,但能够极大的方便问题诊断和定位。
perf 是linux提供的一种基于event的性能搜集分析工具,能够分析CPU/内存/锁等资源的统计信息。perf本身已经提供了相当完整的文字的报表输出功能。

比如这里能看到system_call 也是跟sys_futex 相关的,通常是线程/进程同步共享资源互踩时造成的,还有部分是通讯线程相关的。这样我们的方向就可以从各种锁冲突入手。Perf也能提供锁冲突的信息。
为了简单直观的分析结果,我们还使用火焰图(flame graph)来用图形的方式展现结果,以利用更快的发现问题。下面两张图分别提供了CPU和锁的使用统计:从中我们发现的确有几处热的Latch/mutex。比如内存分配时使用共享内存池,这是会造成等锁的现象,我们可以通过使用线程上独享的内存池解决;还要部分内部表的物理锁冲突严重,我们通过增加锁的控制粒度减少冲突;再有就是尽量减少锁内操作,比如内存分配,磁盘IO尽可能的搬出热锁保护范围。通过一系列优化,我们实现了5%左右的性能提升。
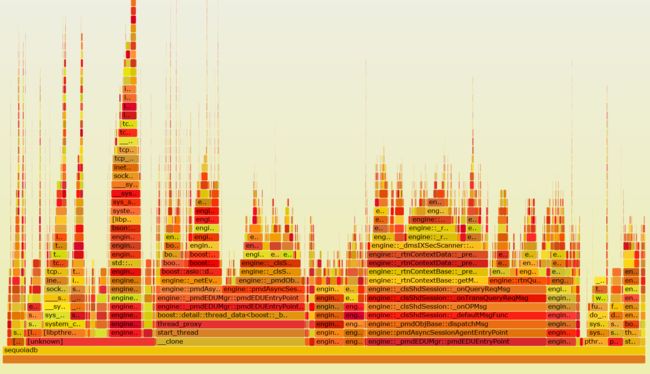
CPU 火焰图
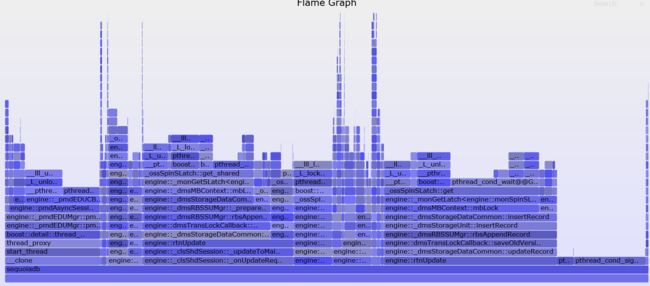
锁火焰图
2. Memory allocation
内存是个好东西,现在计算机系统内存越来越大,软件也尽量通过使用内存来实现空间换时间以提高系统相应速度。但是动态内存分配常常成为了高性能软件的性能瓶颈。我们通过perf 来抓取系统内存的使用情况,并用火焰图显示出来:

这里明显看到的是很多动态内存分配发生在一个set的插入过程中。Std::set内部使用的红黑树,每次结点的插入都要进行内存分配。为了减少系统内存的动态分配与回收,SequoiaDB实现了一整套自己的内存管理机制。最开始尽量在线程预分配好的内存池上分配空间,这点和tcmalloc的原理很接近,这时的开销最小,内存事先已经从操作系统分配好了,而且本线程上分配是无锁的。但是如果线程内存池用完了,我们会到一个共享的预分配好的内存池上分配,这时会多一个锁的开销。但这两处都用完了,我们才向操作系统申请。从火焰图上看,我们基本上都走到向操作系统分配的分支中了。针对这种情况,我们优化了set的实现。当set中结点数量较小时,我们用一个flat的较小的array存放数据,避免了动态内存分配。当结点数较多时,我们再转化成树型结构以提高查找效率。但是我们会提高线程上允许的缓冲池的大小,特别是小结构线程池大小。最终我们避免了绝大多少的动态内存分配与回收,提升了系统性能。通过这块的分析,我们也反过来帮助确定那些query会用到大量数据,并优化对应的query。
3. Cache line misses
大家知道现代CPU的主频非常高,常有超过3GHz,执行指令速度非常快。但是我们存储访问速度始终跟不上,高速的内存又非常贵,这就是现代CPU里有几级不同速度不同大小内存的原因,常见的CPU内集成有L1,L2,L3级缓存。CPU执行时需要从缓存中获取指令和数据。在我们编译程序的时候,编译器会试图优化程序,使得CPU能有效的重用或预提取数据和指令。当CPU在缓存中找不到合适的指令和数据时,就不等不从主存甚至磁盘上读取他们,这样的开销非常大,我们用CPU cache line miss来衡量这中情况出现的频繁程度。
我们还是通过perf命令来搜集cache line miss的情况,
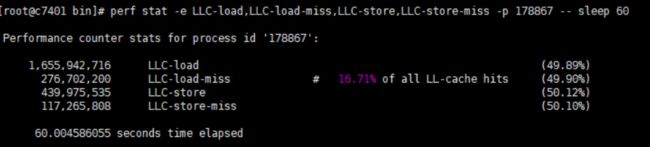
详细信息分解开来,最大一块是由monitor引起的
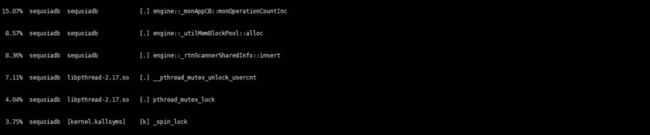
然后我们检查monitor相关的代码,发现代码中有个switch语句公有14个分支,但最常用的一个分支放在了后面。我们只需要将其挪到前面,我们的miss就有显著下降。
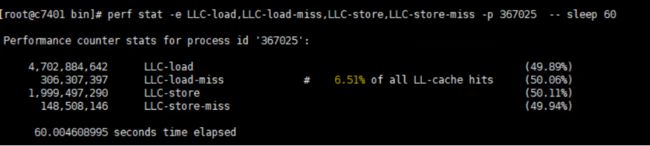
还有另外一种情况造成严重的cache line miss,就是使用原子变量,特别是频繁使用的原子变量。因为一旦该变量被变更了,所有cache 里的值都会变成无效,那么CPU使用时一定会碰到cache line miss。我们通过分析代码逻辑,对于某些常用的确不需要时时精确的值,我们可以在程序逻辑开始存为本地变量,避免过多的直接访问。对于一些只需要单线程访问的变量,我们也避免使用原子变量。
小结:
上面我们通过几个例子,为大家展现了如何通过系统工具进行数据库内核性能优化,同样的思路也可以适用于其他底层软件的开发调试。在实际的实践过程中,除了使用合适的工具,更重要的是还要细心,有耐心和钻研的精神,一步步的下手,从现象中抽丝剥茧,找到根本原因。