[深度学习论文笔记][arxiv 1711] Non-local Neural Networks
[arxiv 1711] Non-local Neural Networks
Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He
from CMU, FAIR
paper link
Motivation
“Non-local”直译为“非局部”。个人的理解是指特征提取时,当前输入数据的特征计算要考虑其它输入数据的信息。举例来说,非局部操作的关注点就是在于如何建立起图像上两个有一定距离的像素之间的联系,如何建立视频里两帧的联系,如何建立一段话中不同词的联系。
一个典型的CNN网络是由一系列卷积操作累积起来的。对于使用在图像上的CNN,每个卷积操作只能捕捉到输入数据的局部信息。整个网络通过局部操作的逐步累积来获得范围较广的信息提取。而RNN则是通过循环的方式处理序列输入(如视频每一帧图像的时间序列或者图片上一列像素的空间序列),从而融合非局部的信息。
这篇文章提出三点CNN和RNN在融合非局部信息上的三个劣势:1.计算不高效;2.优化更难;3.非局部特征的信息传递不够灵活,功能不够强大。当然,这也是因为CNN和RNN的初衷并不是专门来融合非局部信息的。
在这篇文章中,作者提出了一种非局部模块(non-local block, 简称NL block)的网络结构,来帮助深度网络更好地融合非局部的信息。这对于一些问题是非常重要的。
Method
从使用在图像去噪问题中的non-local means[1]方法出发,作者对NL block的抽象描述为:
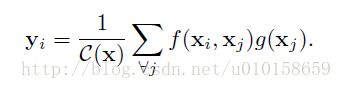
以图像为背景来说的话,i,j是像素坐标,x,y是输入和输出信息。j的取值范围是任意的坐标。C(x)是一个归一化常数。f(.)是用来构建i,j点处信息关联的二输入函数。g(.)是计算j点信息对i点影响的单输入函数。
这样的非局部操作其实很常见,从广义的角度来讲可以从多个已有的研究方向来理解这个操作。首先这是从图像去噪中借鉴来的模型。除此之外,如果f(.)函数输出的是一个概率值,即0~1之间的数值,那么这就是前段时间有所讨论的self-attention[2]。因为(i,j)二元坐标对取遍了所有情况,这个定义又很像dense CRF[3],或者可以认为这也是一种图模型。
回到这篇文章中。作者对f(.)有很多不同选择的定义方式。通过实验选定了名为Embedded Gaussain+Dot product的方案。对g(.)的定义是一个简单的线性函数。NL block的输出并没有替代输入,而是和原输入相加,形成一个残差结构(residual),得到 zi 。
其中W均为待学习的参数,可以将其视为1x1卷积的参数。若 C(x)=∑∀jf(xi,xj) ,那么 1C(x)f(xi,xj) 就是二阶的softmax,即CRF。
f(.)中所做的点积不同于style transfer中的协方差或者bilinear操作。后两者是把不同通道的特征图两两内积,空间信息完全抛弃,得到的结果是通道数x通道数大小的协方差矩阵。f(.)的操作是每个点的特征向量(通道个数的维度)进行内积,空间信息保留了下来,输出还是HxW大小。
整个NL block也可以从结构图来理解:

图中T,H,W代表输入特征的维度。其中T是对于视频数据的帧数,对于分割或检测任务,T=1.
这里面作者还提到了一些小trick可以进一步压缩计算量。比如1x1的卷积压缩输出通道数,形成一个瓶颈结构(bottleneck)。或者在f(.)对应的1x1卷积之后使用pooling来减小H,W,即采样一部分的j而不是所有的j进行信息融合。
可以看到,NL block可以用作网络设计中的一个补充结构插入到CNN中任意的一层之后。因为使用的是1x1卷积,因此对输入特征没有尺寸限制。同时整个操作计算量相对较小,额外参数量也很少。
Experiment
作者在视频分类、物体检测、物体实例分割这些很需要非局部信息关联的任务上进行了实验。其中在Kinetics数据集上进行了ablation study,来仔细研究NL block各个细节的有效性。结果表格不再赘述,得到的结论总结如下:
- NL block中f(.)不同的定义方式各有千秋,但是为了更好化可视化使用embedded Gaussian+dot product,即上文提到的公式所示的方法。
- NL block的放入网络主干的位置:放在浅层好,高层提升作用下降。
- NL block变深的作用:对于主干网络较浅的网络,加深NL block能够提升性能。对于较大较深的网络无论是增加NL block还是继续加深主干网络的深度都很难再提升性能。
- (对视频任务)NL block同时作用于时空比单独作用于时间域或空间域要好。
- (对视频任务)与C3D比较:比C3D又快又好。
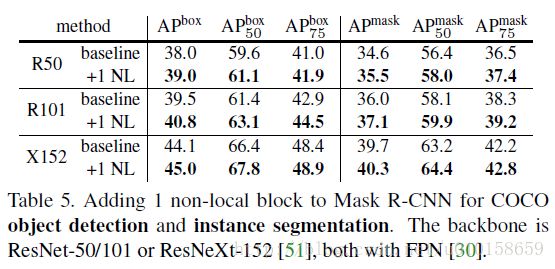
在COCO数据库上的实验结果如下所示。鉴于NL block结构的易用性,在平时设计网络时可以考虑添加这样的模块。
Reference
[1] A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In Computer Vision and Pattern Recognition (CVPR), 2005.
[2] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Neural Information Processing Systems (NIPS), 2017.
[3] P. Krahenbuhl and V. Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In Neural Information Processing Systems (NIPS), 2011.