GCN论文笔记
Large Kernel Matters——Improve Semantic Segmentation by Global Convolution Network
GCN的pytorch实现: https://github.com/SConsul/Global_Convolutional_Network
论文地址:https://arxiv.org/pdf/1703.02719.pdf
一. 语义分割中的两个问题
1. classification
需要feature map中像素和classifier之间密集连接---得到全局信息,便于分类.
同时classification需要具有transformation不变性(平移旋转变形等,类别保持不变)。
所以需要大的感受野。
2. localizatiion
需要对transformation敏感,transformation后应该能够准确的locate every pixel for each semantic category。所以要保持feature map的size,但是感受野会变小不利于classification。
分类和分割的网络结构对比:

所以分类网络通常采用"圆锥形"网络结构(如VGG\ResNet等),在网络的最后通过全连接层或者全局池化层来使classifier 密集链接整个feature map.
而分割网络通常采用"桶形"结构(如FCN\Deeplab\Deconv-net)
总之, 分类要求增大感受野来获取context信息----对feature map进行pooling
但是pooling操作会降低feature map的分辨率,对于需要保持score map分辨率的localization不利
所以,这两个问题natural contradictory。
二. 语义分割的相关工作
大致有三种思路:
1. Context Embedding
(1) ParseNet增加global pooling branch来提取出context information来帮助分类。
(2) Dilated-Net在score map之后增加一些layers来提取多尺度的context
(3) DeeplabV2用ASPP, 在feature map上使用不同rate的空洞卷积, 提取到不同scale的context(为了解决不同scale object问题)
2. Resolution Enlarging
(1) FCN使用反卷积恢复分辨率(反卷积原理及棋盘格现象)
(2) DeconvNet和SegNet引入unpooling操作和glass-like network来学习上采样过程
(3)LRR提出对feature map进行上采样比对score map要好
(4)Deeplab和Dilated-Net提出了使用空洞卷积从而得到较大分辨率的scoremap(deeplab移除了后两个pooling层)
3. Boundary Alignment
使用CRF作为后处理, 提高物体边界的分割精度, 后续又提出一些CRF的改进版
本文的思想: 把语义分割看成是在large feature map上的分类任务.
三. GCN的创新点
1. GCN平衡了classification和localization这两个问题:
(1)For classification, 增大感受野:
使用大的卷积核,使feature map与classifier之间密集连接(大的感受野)。
(2)For localization 保持较大分辨率的Score map:
不使用全连接层和全局池化层,转而使用大卷积核来扩大感受野。并采用FCN的framework。
2. 提出BR(Boundary Refinement)
BR block是一个残差模块,用来提高物体边界的分割准确度。公式是
![]()
其中, 表示经过BR调整之后的score map, S表示原始的Score map, R()表示residual branch
表示经过BR调整之后的score map, S表示原始的Score map, R()表示residual branch

GCN的结构
GCN的思想就是用大的卷积核来达到来扩大感受野(classifier与feature map之间的密集连接)帮助分类的目的
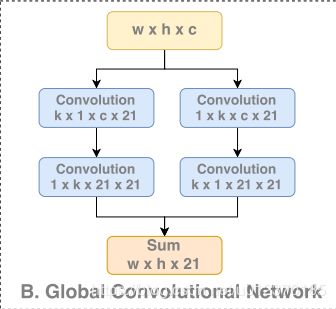
GCN的思想
对于downsampling过程中generate的不同分辨率的feature map都经过GCN
GCN通过大卷积核扩大当前feature map的感受野, 也为分类提供更多scale的context
GCN采用卷积分解的思想, 用k*1和1*k堆叠的方法达到k*k卷积核相同的感受野(可能是为了对称性,两种堆叠顺序并联)
四. 实验部分
1. GCN的对比实验
(1) 参数量带来的提升?
GCN与常规卷积的对比(保持k相同)
结果是:
GCN参数量更少, 但是精度更高
当k<=5的时候常规卷积随着k增大精度变高,但是k>7之后反倒降低了,猜测是因为大卷积核参数量过大导致了过拟合
(2)小卷积核的堆叠和 GCN中的卷积核分解的对比
小卷积核的堆叠: 如VGG中用3个3*3近似一个7*7
小卷积核堆叠比GCN的参数量大, 精度不如GCN(可能是多个小卷积核堆叠,有效感受野并不能达到跟大卷积核同样效果)
另外GCN中1*k和k*1之间不使用非线性激活(作者说为了保证两层之间的连续性?)
(3)GCN是如何提升分割性能的?
GCN主要是因为引入了大卷积核,扩大了感受野(密集连接),保证了transformation 的不变性,从而对分类精度提升有帮助.
所以GCN主要是对object内部的像素点的分类精度有提升(因为这部分像素更像是单纯的分类问题,需要transform不变性,属于classification问题),而对于物体边界的分割精度提升没什么帮助(因为这一部分属于localization问题,需要对transformation敏感)
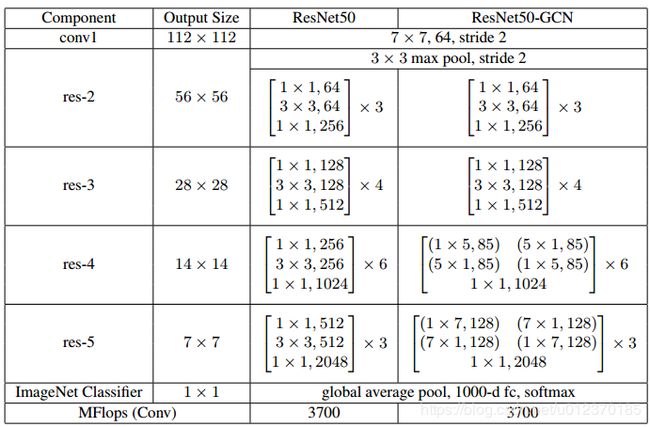
2. GCN替换ResNet的两层
作者还提出一个ResNet-GCN网络,实验中将ResNet中的两层替换成DCN,实验证明GCN对于分类没什么影响, 更适用于分割问题.
(可能是因为分类问题已经有全局池化或者全连接来 实现密集链接,GCN没什么用处, 而GCN主要是用来在大分辨率的feature map上进行分类,所以扩大感受野十分重要)
五. 总结
GCN通过使用大卷积核来平衡classification和localization之间的矛盾. GCN中的大卷积核思想用较少的参数量增大了感受野.
GCN提升了物体内部区域像素的分类精度, BR增加了物体边界像素的分类精度.