MapReduce编程实例(一)
前提准备:
1.hadoop安装运行正常。Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装
2.集成开发环境正常。集成开发环境配置请参考 :Ubuntu 搭建Hadoop源码阅读环境
MapReduce编程实例:
MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析
MapReduce编程实例(二),计算学生平均成绩
MapReduce编程实例(三),数据去重
MapReduce编程实例(四),排序
MapReduce编程实例(五),MapReduce实现单表关联
开发示例:WordCount
本文例详细的介绍如何在集成环境中运行第一个MapReduce程序 WordCount,以及WordCount代码分析
新建MapReduce项目:
Finish生成项目如下,建立WordCount.java类
WordCount.java类代码以下详细解,先运行起来。
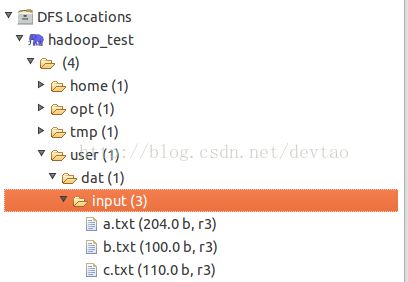
在HDFS建立新目录并上传若干实验用的文本,上传后如下:
配置Run Configuration 参数:
hdfs://localhost:9000/user/dat/input hdfs://localhost:9000/user/dat/output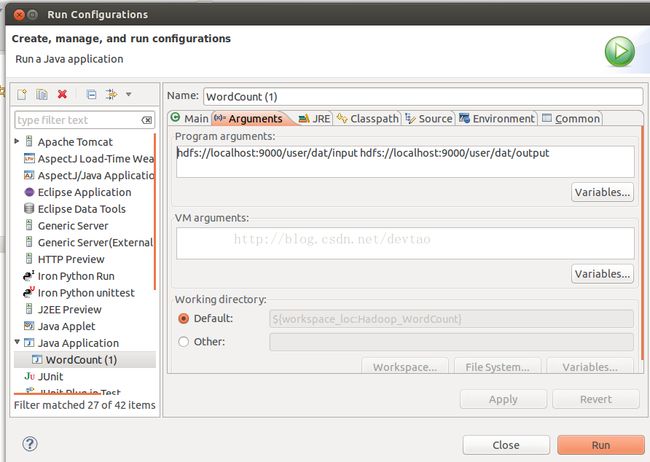
Run On Hadoop,
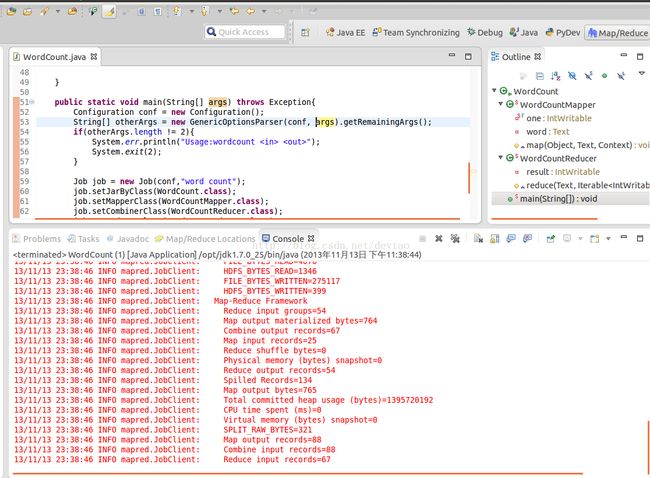
OK,运行成功,检查HDFS的文件生成

Eclipse中可以直接查看也可以在命令行中查看结果
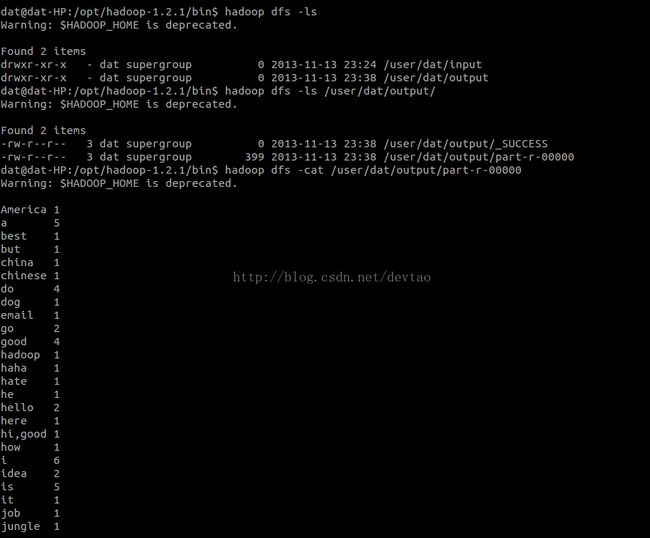
OK,第一个MapReduce程序 WordCount已经成功运行。下面开始解析代码部分
----------------------------------------------烦人的分割线-----------------------------------------------------
代码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//嵌套类 Mapper
//Mapper
public static class WordCountMapper extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);//Context机制
}
}
}
//嵌套类Reducer
//Reduce
//Reducer的valuein类型要和Mapper的va lueout类型一致,Reducer的valuein是Mapper的valueout经过shuffle之后的值
public static class WordCountReducer extends Reducer{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable i:values){
sum += i.get();
}
result.set(sum);
context.write(key,result);//Context机制
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();//获得Configuration配置 Configuration: core-default.xml, core-site.xml
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();//获得输入参数 [hdfs://localhost:9000/user/dat/input, hdfs://localhost:9000/user/dat/output]
if(otherArgs.length != 2){//判断输入参数个数,不为两个异常退出
System.err.println("Usage:wordcount ");
System.exit(2);
}
////设置Job属性
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);//将结果进行局部合并
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//传入input path
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//传入output path,输出路径应该为空,否则报错org.apache.hadoop.mapred.FileAlreadyExistsException。
System.exit(job.waitForCompletion(true)?0:1);//是否正常退出
}
}
先解释两个Java基础问题
----------------------------------StringTokener类--------------------------------------------------------------
Java语言中,提供了专门用来分析字符串的类StringTokenizer(位于java.util包中)。该类可以将字符串分解为独立使用的单词,并称之为语言符号。语言符号之间由定界符(delim)或者是空格、制表符、换行符等典型的空白字符来分隔。其他的字符也同样可以设定为定界符。StringTokenizer类的构造方法及描述见表15-6所示。
表15-6 StringTokenizer类的构造方法及描述
| 构 造 方 法 |
描 述 |
| StringTokenizer(String str) |
为字符串str构造一个字符串分析器。使用默认的定界符,即空格符(如果有多个连续的空格符,则看作是一个)、换行符、回车符、Tab符号等 |
| StringTokenizer(String str, String delim) |
为字符串str构造一个字符串分析器,并使用字符串delim作为定界符 |
StringTokenizer类的主要方法及功能见表15-7所示。
表15-7 StringTokenizer类的主要方法及功能
| 方 法 |
功 能 |
| String nextToken() |
用于逐个获取字符串中的语言符号(单词) |
| boolean hasMoreTokens() |
用于判断所要分析的字符串中,是否还有语言符号,如果有则返回true,反之返回false |
| int countTokens() |
用于得到所要分析的字符串中,一共含有多少个语言符号 |
下面是一个例子。
String s1 = "|ln|ln/sy|ln/dl|ln/as|ln/bx|";
StringTokenizer stringtokenizer1 = new StringTokenizer(s1, "|");
while(stringtokenizer1 .hasMoreTokens()) {
String s3 = stringtokenizer.nextToken();
System.out.println(s3);
}
输出:
ln
ln/sy
ln/dl
ln/as
ln/bx
请参考文章:http://blog.csdn.net/yakihappy/article/details/3979858
-------------------------------------------Java的反射机制--------------------------------------------------------
请参考文章:http://www.cnblogs.com/rollenholt/archive/2011/09/02/2163758.html
请参考文章:http://lavasoft.blog.51cto.com/62575/15433/
请参考文章: http://lavasoft.blog.51cto.com/62575/43218/
----------------------------------------WordCount MapReduce代码分析-------------------------------------
代码分为三部分,一个主函数,一个嵌套类WordCountMapper继承Mapper,一个嵌套类WordCountReducer继承Reducer。
主函数通过反射设置Job属性,设置输入输出路径.。
WordCountMapper:
一个常量IntWritable做valueout,一个Text做keyout.
重写map方法,用StringTokener解析字符串,写入context
WordCountReducer:
一个Intwritable变量,记录输出个数。
reduce函数解析values计算数量,设置context的keyout,valueout。
ok,就是这么easy。。。
注意map和reduce都是回调函数,是由MapReduce框架控制的,还未深入研究。