我虽不是人类:且看我如何攻破Google的ReCAPTCHA
- 理解Recaptcha
- 网页控件
- 工作流程
- 验证码类型
- 解决方案
- 对风险分析系统的分析
- 1 浏览历史
- 2 浏览器环境
- Canvas着色
- 用户机器
- 屏幕分辨率和鼠标
- 3 网站限制
- 简单的验证码破解器
- 1 获取Token
- 2 评价
- 图片验证码
- 1 图片验证码方案的灵活性
- 2 重复的图片
- 图片验证码破解器
- 1 图片注释服务与库
- GRIS
- Clarifai
- Alchemy
- TDL
- NeuralTalk
- Caffe
- 2 标签分类器
- 3 历史模块
- 4 方案
- 5 评价
- 模拟攻击
- 标签分类器
- 实时攻击
- 1 图片注释服务与库
- 适用性
- 经济分析
- 1 图片验证码
- 2 Checkbox验证码
- 道德声明
- 致谢
- 引用
写在前面:
本文是对I’m not a human: Breaking the Google reCAPTCHA的翻译。论文中简单介绍了Google的ReCAPTCHA服务,然后主要针对其中两种验证码方式提出了绕过或攻击方案,并做了模拟测试。
关于ReCAPTCHA的简单介绍,可以看我的这篇Break Google ReCAPTCHA: ReCAPTCHA科普
此分割线以下是全部译文,自己翻译,欢迎勘误。
验证码从诞生之日起,就被广泛地运用在阻止攻击者的不合法操作上。尽管验证码能在一定程度上拦截攻击者,但是在经济利益的驱动下,各种针对验证码的自动化攻击方式层出不穷,验证码服务也相应地做出改进。然而最近,出现了一种针对文本验证码的通用攻击方式。Google也适时地公布了reCaptcha的最新版本。最新版本有双重目标:一是减少合法用户通过验证码认证的成本,二是提供了对计算机来说,比文本识别更具挑战性的验证码。ReCaptcha是由一个“高级的风险分析系统”驱动的,这种系统能分析收到的请求,并挑出适合难度的验证码返回给用户。用户可能需要勾选一个checkbox,或者需要挑出描述相同内容的一组图片。
在这篇论文中,我们对reCaptcha做了系统研究,也对用户请求的方方面面是如何影响风险分析系统做判断的。通过大量的实验,我们发现一些缺陷,攻击者可以通过这些缺陷轻松地影响风险分析系统,绕过验证码限制,进而实施大规模的攻击。接下来,我们利用对图片做语义注释的深度学习技术,设计了一种比较新奇同时又低成本的攻击。我们的攻击系统非常有效,能够自动解决70.78%的图片reCaptcha,每个验证码的认证只平均只耗费19s。我们对Facebook的图片验证码也做了测试攻击,成功率达到了83.5%。基于我们的实验所得,我们针对我们的攻击,提供了一系列的保护和改善措施。总之,我们的研究专注于reCaptcha,我们的发现也有非常广的影响。因为对图片所传达的语义信息的逻辑自动化处理越来越多,越来越频繁,所以,验证码也必须顺应趋势,在更新奇的方向上做更深的探索。
1 理解Recaptcha
Google提供的reCaptcha服务是使用最广泛的验证码服务,许多主流网站都用它来拦截自动化机器的不合法攻击。Google指出,最新reCaptcha机制的部署,具有更高的用户友好度和安全性。
网页控件
当访问一个被reCaptcha保护的网页时,会显示一个小网页控件(如图1(a)所示)。为了避免被第三方分析,这个小控件的JavaScript代码是被混淆过的。当这个控件用来收集用户浏览器的信息并发送给后台服务器。而且,它还会进行一系列的检查,来核实用户的浏览器。
工作流程
一旦用户点击了checkbox,浏览器就会给Google发送一个请求,这个请求中包括(i)Referrer,(ii)网站的sitekey(注册reCaptcha是获得的),(iii)提供给google.com的cookie,和(iv)执行此控件的浏览器收集到的检查信息(加密的)。高级风险测试系统会分析这个请求,然后决定该给用户什么类型的验证码。
 |
 |
|---|---|
| (a) 用户点击checkbox之前 | (b) 用户点击checkbox之后 |
图 1. reCaptcha网页控件

图 2. reCaptcha提供的相似图片验证码
验证码类型
针对不同的用户,会使用不同的验证码类型。对于特定的信用较低,或者频繁请求的,或者输错了很多答案的用户,会使用更难的验证码。在我们的测试中,我们遇到了以下类型的验证码:
- “无验证码的reCaptcha”[图 1]。这是一种新版本的验证码,正常用户可以毫无压力地解决这样的验证码。当用户点击过控件上的checkbox之后,如果高级风险分析系统认定此用户的信用度高,则认为此用户直接通过了验证。本文以下将这种验证码称作checkbox验证码。
- “图片reCaptcha”[图 2]。这种新版的图片验证码要求用户识别出相似的图片。这种验证码包括1张样本图片和9张候选图片,用户需要从候选图片中选出和样本图片相似的图片。这种验证码中也会包括一个关键词,这个关键词就是对用户应该选的那些图片特征的概括性描述。通常需要用户从候选中挑出2到4张图片。
- “文本reCaptcha”[表 1(a)到(e)]。这些扭曲的(译注:这里原文中distored有误,应该是distorted)文字,就是高级风险分析系统为那些被认定为信用度较低的用户提供的。在用户点击checkbox之前,如果用户机器在某些的浏览器检查中失败了,那么分析系统就会返回给用户类似(e)这种可靠的验证码,网页控件会自动收取并显示此验证码。因为这种验证码能被机器所识别,但是对于正常用户却不太友好,所以,在过去的六个月里,文本验证码似乎正在被逐步地“被淘汰”,现在图片验证码通常被作为默认的验证码类型被返回。
表 1. 文本reCaptcha的一些既有例子
(a) |
(b) |
|---|---|
(c) |
(d)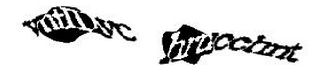 |
(e) |
解决方案
从验证码显示的时刻开始,用户有55秒的时间来解决它。否则用户需要重新再来一遍:再次点击checkbox,再次收到一个新的验证码。一旦用户点击了验证码,一个叫做recaptcha-token的HTML字段就会被保存在token中。如果用户被认定是合法的,不再需要验证码来验证,那么这个token也就会被Google的服务器认可。这个token会被提交给网站,来获得服务器的认可。网站会通过reCaptcha API发送一个确认请求,这个请求中包括:(i)一个共享密钥,(ii)一个响应token和(iii)一个可选的用户IP地址。如果收到了这个请求的响应,就代表认证成功了。
2 对风险分析系统的分析
这一节,我们探索了Google高级风险分析体系,并且鉴定如此大量的用户信息和用户浏览器信息的特征值是怎么影响它的。我们使用黑箱测试,来鉴定我们的系统和测试环境的各个方面是怎么影响风险分析的。我们的目的就是,发出高级风险分析系统认定为合法的验证码请求,这样,我们就能收到最简单的checkbox类型验证码,只需轻轻一点就能通过验证。
2.1 浏览历史
Google的追踪cookie在应该呈现给用户什么难度的验证码的决策中起着至关重要的作用。有一些合法用户,正是因为他们本地的某种特定的cookie,保证了他们只需要通过checkbox验证即可;我们设计的测试方案,就是为了找出什么样浏览历史记录是这样的特定cookie所需要的,我们不仅要找出是哪些,而且要把这些浏览历史的必需量降到最低。我们研究了多重网络连接的启动,以及能够生成浏览历史的活动。我们在我们的分网和US出口节点的Tor网络上都做了测试。我们用自动的方式,在Google上搜索某些关键词,访问搜出来的那些结果,看Youtube上的视频,搜索Google地图,访问包含Google+插件或控件的一些主流网站。令人惊奇的是,我们在第9天一早生成的cookie能够让我们获取checkbox验证码,不需要表2中列举出来的任何浏览活动和网络连接类型。我们的测试还发现,每一个cookie能在一天中收到最多8个checkbox验证码。
表 2. 构造追踪cookie和“模拟”用户行为
| Network | Web Surfing | Account | Threshold |
|---|---|---|---|
| Departmental | Frequent | No | 9th day |
| Departmental | Moderate | No | 9th day |
| ToR | Frequent | No | 9th day |
| ToR | Moderate | No | 9th day |
| Any | None | No | 9th day |
2.2 浏览器环境
为了发现可以的浏览器属性或行为,reCaptcha控件执行了一系列的检查。尽管控件的JavaScript代码已经被混淆了,但是反混淆的代码现在也已经被发布了,通过反混淆,我们就能清楚地知道它具体做了什么样的检查。这里,我们探究了我们的自动的浏览器环境的各个方面是怎么影响风险分析的结果的。
表 3. 我们系统使用的和用户机器包含的不匹配信息的组合
| Component | 9-day Cookie | System runs | User-Agent reports | Captcha |
|---|---|---|---|---|
| Browser | ✔ | Firefox/36.0 | fMobile/8C148 Safari/6533.18.5, Chrome/42.0.2311.135 Safari/537.36g | image |
| Browser version | ✔ | Firefox/36.0 | Firefox/f10.0, 35.0, 36.0, 3.0.12g | checkbox |
| Browser version | ✘ | Firefox/36.0 | Firefox/f10.0, 35.0, 36.0g | image |
| Browser version | - | Firefox/36.0 | Firefox/1.0.4 | fallback |
| Browser version | ✘ | Chrome/42.0 | Chrome/f15.0.861.0, 4.0.212.1g | image |
| Browser version | - | Chrome/42.0 | Chrome/3.0.191.3 | fallback |
| Engine version | - | Chrome/42.0; AppleWebKit/537.36 | AppleWebKit/f528.10, 530.5, 531.3g | fallback |
| Engine version | ✘ | Chrome 42/0; AppleWebKit/537.36 | AppleWebKit/f532 and upg | image |
| Engine version | ✔/✘ | Firefox/36.0; Gecko/20100101 | Gecko/20040914 | image |
| Engine version | ✔ | Chrome 42/0; AppleWebKit/537.36 | Chrome 42/0; Gecko/20100101 | fallback |
| Browser/Engine | - | Firefox/36.0; Gecko/20100101 | Firefox/36.0; AppleWebKit/537.36 | image |
| Browser/Engine | ✔/✘ | Linux x86 64 | f(Macintosh; Intel Mac OS X 10.8;), (Android; Mobile;), (Windows NT 6.3;)g | checkbox |
| - | - | - | wrong format or incomplete information | fallback |
| - | ✔ | Linux x86 64; Firefox/36.0 | Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420 (KHTML, like Gecko) Version/3.0 Mobile/1A543a Safari/419.3 | checkbox |
Canvas着色
Canvas着色是一种既有技术,用来跨机器或浏览器识别用户。reCaptcha的JavaScript代码创建一个canvas节点并构造成一种预定义的结构。着色完成之后,当用户点击checkbox时,这个canvas节点会被编码成base64格式,连同其他数据发送回服务器。这些信息可以被浏览器的着色功能使用,来确定浏览器的版本,然后和用户机器登记的信息做对比,发现不同之处。
用户机器
为了确定用户机器如何影响用户的信用度,我们按特定的情况分组,在每组中做同样的测试。我们发现,如果用户机器的浏览器或者浏览器引擎的版本太低,控件就会自动认定环境可信度太低,然后给用户返回一个可靠的验证码(表 1-(e))。如果浏览器或者引擎是最新的版本,但是和实际的测试环境的版本不相符,控件还是会返回一个可靠的验证码(例如,如果我们使用的是Firefox,而之前登记的是Chrome)。当用户机器上的信息没有被正确的格式化时,返回的还是可靠的验证码。
屏幕分辨率和鼠标
我们测试了不同屏幕分辨率的各种组合和各种鼠标行为的配置(指针的移动速度和模式)。这些对风险分析系统的决策没有任何影响。
2.3 网站限制
如果我们能够解决我们控制的一个网站(attacker.com)的验证码,但是这些验证码却能将我们获取的token和目标网站(example.com)关联起来,这样,我们就能提高攻击的命中率。利用这样的方式,验证码破解服务能构造有效的token卖给别人,从而降低网络活动量,也就是说,降低了攻击的成本。这种简单明了的点击劫持式的攻击已经被证实。为了拦截这样的攻击,reCaptcha被重新设计,来保证token是和提供验证码的网站绑定起来的。除了检查Referrer之外,控件还会通过document.location.hostname来检查网站,这个document.location.hostname是只读的,不可能被拦截而出现安全问题。我们提供了一种变通方案来绕过这个限制。我们在我们的服务器上构建了一个虚拟主机,给这个主机起了一个和example.com一样的名字和其他必要的配置。通过使用a2ensite和修改hosts文件,我们可以在虚拟主机上运行我们的网站,欺骗reCaptcha来把我们的请求和example.com关联起来。为了完整我们的攻击,我们还需要发送目标网站的sitekey,这个sitekey能从网站的网页源文件中轻易地得到。
3 简单的验证码破解器
目的是为了构造看起来像是合法用户生成的而不是机器人自动生成的cookie。每一次,我们都在一台干净的虚拟机上创建cookie,虚拟机上的浏览器自动系统没有保存google.com的任何账号的cookie。
3.1 获取Token
我们还研究了网站是否会禁止我们使用同一个IP地址去获取大量的cookie。我们在一天内创建了63000个cookie,没有任何问题,瓶颈仅在于机器的硬件性能。这表明,用同一个IP地址去获取大量的cookie是没有任何限制的。我们发现的唯一的限制是大量的并发请求(例如,检测到DoS洪泛攻击)。至今为止,没有任何攻击是依赖于创建大量的cookie的,所以导致了对于这种单IP创建大量cookie的保护措施的缺失。没错,我们确实发现了一种能让攻击者有利可图的,通过滥用追踪cookie的攻击方式。
3.2 评价
接下来,我们在这些cookie“成熟”之后部署了我们的系统,来看看我们一天内能解决多少checkbox验证码。我们在不同的验证码请求频度下做了测试,发现随着请求频度的上升,准确率成下降趋势。最后,尽管系统被阻塞了很短的一段时间,但在最佳的请求频度下,我们一个小时内收到了大概2500个checkbox验证码,在最高的请求频度下,一个小时大概是1200个。我们发现,周末时的阻塞会更少,一天能获得大概59000个checkbox验证码。
4 图片验证码
这一节,我们研究新的Google图片验证码,展示我们在测试中发现的各式各样的特性。攻击者可以利用其中的一些特性,来解决图片验证码,我们的目的就是找到这些可能被利用的特性。
4.1 图片验证码方案的灵活性
我们探索了,在判断验证码方案是否正确时,reCaptcha是否具有灵活性。在任何情况下,至少需要选出两张图片,然后才会发送回复响应。我们手动地用不同的正确图片数(n)和错误图片数(k)的各种组合来尝试通过验证码验证。在大多数情况下(74%),我们发现正确的候选图片数通常是2个;其余的多是3个,我们也发现有两个验证码里有4个正确的候选图片。我们的测试发现,即使少选了一个正确图片,或者多选了一个错误图片,用户仍然能通过验证。基于这些结果,我们按照选3个图片来设置我们的验证码破解系统;这样的破解策略能保证,在正确的图片数为2时,我们仍可能通过验证码的验证。
最终,我们的实践结果证实了我们策略的正确性,图片验证码确实具有一定的灵活性,在表4中展示了我们发现的总是会返回true的各种结合方式。
表 4. 通过图片reCaptcha的组合情况
| Image Selection | Constraint | Pass |
|---|---|---|
| n Correct + k Wrong | k ≤ 1 | ✔ |
| (n - 1) Correct | n > 2 | ✔ |
| (n - 1) Correct + k Wrong | k > 0 | ✘ |
4.2 重复的图片
在我们的测试中,我们遇到过几次不同的验证码中存在相同的图片的情况。有时我们也遇到完全相同的两个验证码:完全相同的图片,甚至完全相同的图片顺序。这暗示我们,这些验证码不是被“即时”创建出来的,而是从一个相对较小的验证码库中挑选出来的。
我们也发现,验证码间可能会重复部分图片。然而,在多数情况下,这些图片的MD5值都是不相同的。因此,我们使用感知的哈希方法,来归类那些即使MD5不相同,但是却具有相同含义的图片。我们发现了20%的重复图片。最多的重复了12次。
5 图片验证码破解器
最近在计算机领域可谓是硕果累累,并且已经有人开始把这些最新的成果利用在图片识别服务上了。这些识别服务也变得更有效,适用面也变得更广,所以我们探究,究竟我们能不能把它们用在解决图片验证码上。
为了解决一个图片验证码,我们的系统必须能够自动地判断,哪些候选图片和样本图片在语义上是相符的。收到一个图片验证码后,我们解析样本和候选图片,标记样本图片的语义信息(例如,“wine”)。然后,把所有的图片都传给一个图片注释模块。
5.1 图片注释服务与库
有几款在线的服务和库能提供这样的功能:通过对无描述的图片加标签(关键词)来做图片分类。
GRIS
Google Reverse Image Search是由Krizhevsky等人创建的,提供了基于图片的搜索服务。如果搜索成功了,它可能会返回一个对此图片“贴近真实情况的”描述(见图3),同时会返回这个图片出现过的一系列网站列表。尽管这不是Google的公用API,但是我们通过浏览器调试识别出了这个搜索URL,并把此功能用在我们自己的模块上。在对9个候选图片做搜索的同时,我们还收集了与这些图片相关的网站的网页标题作为备用信息。在条件允许的情况下,我们同样获取了每张图片的更高分辨率的版本,这会帮助提高图片注释模块的准确度。如果返回得描述信息不是英文,我们就用Google翻译的自动语言识别功能,将它们翻译成英文。
| Image | GRIS | Alchemy | Clarifai | TDL | NeuralTalk | Caffe |
|---|---|---|---|---|---|---|
 |
wine and blood | wine, glass | glass, red wine, wine, merlot, liquid, bottle, still, glassware, alcohol, drink, wineglass, beverage, pouring, white wine, cabernet, taste, leaded glass, dining, party, vino | red wine, goblet, wine bottle, punching bag, beer glass, perfume, balloon | a glass of wine sitting on top of a table | red wine, wine, alcohol, drug of abuse, drug, red wine, punching bag, beaker, cocktail shaker, table lamp |
Clarifai
这是由Zeiler等人在一个反卷积网络上搭建的,对于一张图片,会返回20个标签,每个标签还有信用度得分。
Alchemy
同样是在深度学习的基础上搭建的,并且提供了图片识别的API。对于每一个提交的图片,这个服务会返回一组标签,每个标签都有相应的信用度得分。在我们的测试中,对每个图片返回了8个很明确的标签(例如,“wine”)。
TDL
Srivastava和Salakhutdinov利用他们的深度学习系统发布了一个具有图片聚类功能的系统。对每个图片,它会返回8个带信用度得分的标签。
NeuralTalk
Karpathy和Fei-Fei开发了NeuralTalk,一个对无描述图片生成描述信息的周期性神经网络架构。我们把它返回的描述分解成若干个单词。
Caffe
Jia等人发布了Caffe,一个深度学习架构,我们同样用它来在本地处理图片。Caffe返回一组共10个标签:5个最高可信度得分的标签,和5个可信度得分较低,但是更像是关键词的标签。
5.2 标签分类器
返回的标签并不总是能够和reCaptcha的图片验证码中的图片对的上。为了解决这个问题,我们(自主地)研究机器学习,并利用机器学习开发了一个能够在一组标签的基础上“猜”图片真实含义的分类器。我们使用了由Mikolov等人开发的Word2Vec单词矢量引擎来寻找这些候选图片标签和样本图片标签的相似之处。在训练我们的分类器期间,我们对每一个标签(候选图片的和样本图片的)在矢量空间内建模出一个真实的矢量。每一个候选图片标签都和样本图片标签配对,然后把所有标签都作为输入,传入我们建立的数学模型。等对分类器的训练结束之后,它就能通过计算预测样本图片标签和候选图片标签的单词矢量之间的余弦相似性,来分析标签之间的相似处,从而最终识别出和样本图片标签具有较高关联度的候选图片标签的集合。因此,通过这样的方式,即使图片注释系统提供了不相符的标签,我们的分类器也能够识别出相似的图片。
5.3 历史模块
验证码中的图片很多都是被重复使用的。正是因为这样,我们创建了一个图片的标签数据库,来记录我们遇到过的图片,和我们分析出来的与之对应的标签。每一张图片都和验证码中给出的样本图片标签(例如,猫,汤)相关联。我们同样维护了一个hint_list,来保存我们遇到过的所有的样本图片标签。
5.4 方案
每一个模块都会将候选图片分为三类:select,discard和undecided。首先,我们通过GRIS收集所有图片的信息。然后,如果样本图片的标签没有被显示的提供的话,我们就会去找我们的标签数据库,看看能不能找到这张样本图片的标签。接下来,历史模块会去处理候选图片,同样是去标签数据库中找他们的标签,如果找到了,就和样本图片标签做比对,匹配的那些,就会被加入select列表。对那些剩下的不匹配的图片,我们会和hint_list中的那些标签再做进一步比对,如果匹配上,就会加入discard列表中。接着,图片注释模块会去解析所有的图片,然后给它们打上标签。同样,如果和样本图片标签匹配,就会被加入select列表中;如果和hint_list中的标签匹配,就会被加入discard列表中。对于那些我们利用第三方的公共服务和库获取的最佳结果以及网页标题,我们也进行以上同样的操作。当所有模块都运行结束后,系统会整合这些模块的子结果。有时,不同的模块对同一张图片,会给出不同的结果,所以,我们会给子结果赋予不同的“权重”(比如,通过对网页标题分析得到的标签,这些标签权重会比较低)。如果select列表中的图片数量不够3个,系统会优先从undecided列表中挑选图片,来凑够3个。至于要从中挑选哪个(些)图片,可能是用我们的标签分类器来挑选,也可能是挑选那个(些)和样本图片具有最相似的(比如,最有共同点的)标签的图片。
5.5 评价
模拟攻击
我们在我们下载资料库中模拟了验证码攻击。图4中,展示了每个模块和不同信息类型的攻击精确度。这里,我们使用了我们测试中生成的hint_list,但是没有用我们的历史模块或者标签分类器。

图 4. 在模拟攻击中,不同模块与数据的组合对reCaptcha图片验证码的攻击精确度
就像我们之前在表4中展示的一样,reCaptcha的图片验证码策略是有一定灵活性的,即使我们选错了一个候选图片,我们一样能通过验证。既然如此,我们就打了个“擦边球”,把我们的系统设置成挑选3张图片。图4中的Pass Challenge显示的就是攻击结果。
对于每种模块,在它们基于重合标签挑选图片的时候,我们给它们设置了一个最低准则;对于GRIS,它同样需要用到验证码中的样本图片标签和RIS返回的最佳标签。总的来说,GRIS的命中率受限于我们获取到的候选图片的最佳标签的数量。对于其他的模块,最低准则就是挑出来3张和样本图片有最相似标签的那些候选图片。当使用样本图片标签、候选图片的最佳标签和网页标题时,Alchemy模块通过了49.9%的验证码,Clarifai通过了58%。Caffe同样很有效,通过45.9%的验证码。多数情况下,样本图片标签起着至关重要的作用,依赖注释系统能提高1.5%到15.5%的准确率。
我们也探究了高分辨率的图片会如何影响图片注释模块的准确率。我们通过自动化的方式获取了700个验证码中2909张具有更高分辨率的图片。其中371张是相同的图片。高分辨率的图片能提高攻击的准确度,Alchemy和Clarifai分别通过了53.4%和61.2%的验证码。TDL的精度稍低,45%,而Caffe则提高到了49.1%。
我们还测试了,如果忽略图片验证码的灵活性,我们的系统是否还能成功通过验证。因为在多数的情况下,只有两张候选图片是正确的,所以我们把我们的系统也修改成了只挑选两张图片。图4中的Exact Solution展示就是忽略灵活性的结果,其中,所有的图片注释服务在识别正确图片方面都相当有效。Clarifai是最有效的,因为它精确匹配了验证码中40.2%的图片,Alchemy达到了31.5%,Caffe达到了28.3%。
标签分类器
为了量化我们的验证码破解系统中标签分类器的作用,我们基于资料库中700个图片验证码做了10层迭代训练和测试。在我们第一次试验中,我们跳过了所有其他的图片挑选步骤,单单通过分类器来挑选图片。对于每一张图片,分类器接收样本图片标签和一组标签作为输入,返回一个“相似度”评分;我们挑选3张最高得分的图片作为结果。我们的攻击在精确匹配情景下达到了26.28%精确度,解决了44.71%的验证码。在第二次试验中,我们把分类器放在整个系统中使用,在从undecided列表中挑选图片时,使用基于分类器的选择结果,而不是基于近似标签的选择结果。当使用分类器的时候,我们使用Clarifai攻击的平均准确度达到了66.57%,提高了约5.3%。分类器的方式比直接的相似度匹配更有效,因为它识别的是和样本图片标签相关的标签集合中的特定子集,而不是根据相似标签划分出来的简单子集。而且,分类器方式并不影响攻击效率,仅仅多耗时大概0.025s。
实时攻击
为了对我们攻击准确度做精确测量,我们直接用我们的自动验证码破解器攻击reCaptcha。因为Clarifai在我们的试验中表现最好,所以我们使用它作为我们的识别服务。
标签数据库。我们创建了标签数据库来减少重复图片的影响。我们手动给验证码中的3000个图片打上标签,每个图片都有一个描述图片内容的标签。我们从我们的hint_list中挑选了合适的标签。我们使用pHash来做对比,因为它效率很高,能帮助我们的系统在3.3s内就比对了一个验证码中的所有图片。
我们用验证码破解器去识别2235个验证码,准确率达70.78%。之所以比我们模拟攻击的准确率要高,部分是因为图片重复较多;历史模块从我们的标签数据库中识别了1515张样本图片和385张候选图片。
平均运行时间。我们的攻击非常有效率,破解一个验证码平均耗时19.2s。多数的时间耗费在运行GRIS上,因为它会去Google上搜索所有的图片并返回结果,包括那些指向更高分辨率图片的网站链接。
离线模式。我们同样评估了离线模式下的攻击,我们不使用任何的在线注释服务或者GRIS;仅仅使用本地的库、标签数据库和分类器。一共使用了两个库:NeuralTalk和Caffe。当使用Caffe和我们的分类器时,我们的系统解决了41.57%的图片验证码,每个的平均耗时提高到了20.9s。当使用NeuralTalk时,大概解决了40%,耗时也相当长,达到了117.8s,因为NeuralTalk处理10个图片需要110.9s。但是,利用GPU来做计算会提高效率,减少耗时。
因此,攻击者能对reCaptcha的图片验证码部署精确有效的攻击,并且不需要依赖外部的服务,这些处理大量图片或报告可疑活动的服务可能会不是免费的。

图 5. Facebook的图片验证码
6 适用性
我们攻击的原理也适用于其他的情况,通过解析图片的语义信息,我们能够攻击基于图片的验证码,比如Facebook的验证码(图5)。当用户给别人发送包括可疑链接的消息时,Facebook会要求用户通过一个图片验证码,只有通过验证,消息才能发送成功。Facebook的图片验证码和reCaptcha原理类似,用户需要从候选图片(12张以内)中根据提示挑选图片。但是也有一些不同。Facebook在HTML里动态地调整图片的大小,允许访问图片的高分辨率版本。同时,没有样本图片。和reCaptcha一样,它的系统也具有一定的灵活性。正确的图片数量范围是2到10张,多数是5到7张。相应地,我们调整我们的算法,只挑选select列表中的图片,而不是选指定数量的图片。
在200个Facebook的图片验证码中,我们基于Clarifai的攻击达到了83.5%的准确率。比reCaptcha更高的准确率,主要有两个原因。一是候选图片的高分辨率,二是Facebook在创建验证码时,对于不正确的图片,使用的是毫不相关的图片。而reCaptcha对于不正确的图片,选择的也是同类别的图片(比如,都是食物,只是种类有些区别),所以更难区分。
7 经济分析
因为验证码破解通常源于经济利益,我们把我们的攻击看做是一个验证码攻击服务,从经济角度分析了我们的发现。
7.1 图片验证码
拿我们的效率和Decaptcher,一个古老的验证码破解服务,作对比。我们选择Decaptcher做对比是处于两个原因。一,它支持reCaptcha图片验证码,每解决1000个验证码收费$2。二,它之前的表现,证明它是准确度最高的验证码破解服务。
我们向Decaptcher提交了700个图片验证码,然后测量了响应时间和准确度(利用了图片验证码的灵活性)。有意思的是,Decaptcher拒绝了我们提交的很多验证码。
我们提交的一些验证码被拒绝了,是因为服务过载了,我们必须过段时间再提交,并且受到了一个在时间窗口期没有被服务处理的超时异常。258个验证码(占总数的36.85%)成功地精确匹配。当考虑灵活性时,321个(44.3%)验证码被解决。平均的解决时间是22.5s。随着人们越来越适应图片验证码,人工破解的精确度会随着时间提高,但是不可否认,我们的系统还是一种比较有经济效益的可选方案。我们的完全离线验证码破解系统在准确度和效率上完全比得上专业的破解服务,尽管如此,我们也不会提供给任何攻击者来获利。
7.2 Checkbox验证码
假设每1000个解决的验证码收费2美元的话,我们的token攻击,一个主机(IP地址)一天,能收入104到110美元。通过使用代理服务做并行攻击的话,这个收入的数字会比单机有显著的提高。
8 道德声明
我们把我们的发现和建议报告给了Google,帮助他们提高reCaptcha对自动攻击的健壮性。根据我们的揭露成果,reCaptcha改变了安全策略和风险分析过程,来缓解我们的大规模token攻击。他们也移除了图片验证码方案的灵活性和样本图片,从而降低了攻击的准确度。我们也通知的Facebook,但是我们还没有发现他们做了任何改变。总之,我们希望,通过分享我们的发现,能帮助发起研究者和企业之间关于验证码未来的亟需的讨论。
致谢
我们的工作得到了NSF的支持,得到了CNS-13-18415的拨款。作者Suphannee Sivakorn现在兼职于泰国皇家科学技术部门。文中的任何观点、发现、结论或建议都是作者的表述,并不代表US政府或NSF。
引用
见原文。略。