面试干货!21个必知数据科学面试题和答案part1(1-11)
本文为数盟原创译文,欢迎转载,注明出处“数盟社区”即可
KDnuggets编辑给你“20个问题来分辨真假数据科学家”的答案,包括什么是正则化、我们崇拜的数据科学家、模型验证等等。
作者 Gregory Piatetsky, KDnuggets.
最近KDnuggets上发的“20个问题来分辨真假数据科学家”这篇文章非常热门,获得了一月的阅读量排行首位。
但是这些问题并没有提供答案,所以KDnuggets的小编们聚在一起写出了这些问题的答案。我还加了一个特别提问——第21问,是20个问题里没有的。
下面是答案。
Q1.解释什么是正则化,以及它为什么有用。
回答者:Matthew Mayo
正则化是添加一个调优参数的过程模型来引导平滑以防止过拟合。(参加KDnuggets文章《过拟合》)
这通常是通过添加一个常数到现有的权向量。这个常数通常要么是L1(Lasso)要么是L2(ridge),但实际上可以是任何标准。该模型的测算结果的下一步应该是将正则化训练集计算的损失函数的均值最小化。
Xavier Amatriain在这里向那些感兴趣的人清楚的展示了L1和L2正则化之间的比较。
图1: Lp球:p的值减少,相应的L-p空间的大小也会减少。
Q2.你最崇拜哪些数据科学家和创业公司?
回答者:Gregory Piatetsky
这个问题没有标准答案,下面是我个人最崇拜的12名数据科学家,排名不分先后。
Geoff Hinton, Yann LeCun, 和 Yoshua Bengio-因他们对神经网络的坚持不懈的研究,和开启了当前深度学习的革命。
Demis Hassabis,因他在DeepMind的杰出表现——在Atari游戏中实现了人或超人的表现和最近Go的表现。
来自datakind的Jake Porway和芝加哥大学DSSG的Rayid Ghani因他们让数据科学对社会产生贡献。
DJ Patil,美国第一首席数据科学家,利用数据科学使美国政府工作效率更高。
Kirk D. Borne,因其在大众传媒中的影响力和领导力。
Claudia Perlich,因其在广告生态系统的贡献,和作为kdd-2014的领头人。
Hilary Mason在Bitly杰出的工作,和作为一个大数据的明星激发他人。
Usama Fayyad,展示了其领导力,为KDD和数据科学设立了高目标,这帮助我和成千上万的人不断激励自己做到最好。
Hadley Wickham,因他在数据科学和数据可视化方面的出色的成果,包括dplyr,ggplot2,和RStudio。
数据科学领域里有太多优秀的创业公司,但我不会在这里列出它们,以避免利益冲突。
Q3.如何验证一个用多元回归生成的对定量结果变量的预测模型。
回答者:Matthew Mayo
模型验证方法:
如果模型预测的值远远超出响应变量范围,这将立即显示较差的估计或模型不准确。
如果值看似是合理的,检查参数;下列情况表示较差估计或多重共线性:预期相反的迹象,不寻常的或大或小的值,或添加新数据时观察到不一致。
利用该模型预测新的数据,并使用计算的系数(平方)作为模型的有效性措施。
使用数据拆分,以形成一个单独的数据集,用于估计模型参数,另一个用于验证预测。
如果数据集包含一个实例的较小数字,用对折重新采样,测量效度与R平方和均方误差(MSE)。
Q4.解释准确率和召回率。它们和ROC曲线有什么关系?
回答者:Gregory Piatetsky
这是kdnuggets常见问题的答案:精度和召回
计算精度和召回其实相当容易。想象一下10000例中有100例负数。你想预测哪一个是积极的,你选择200个以更好的机会来捕捉100个积极的案例。你记录下你预测的ID,当你得到实际结果时,你总结你是对的或错的。以下是正确或错误的四种可能:
TN/真负数:例负数且预测负数
TP/真正数:例正数且预测正数
FN/假负数:例负数但是预测负数
FP/假正数:例负数但是预测正数
意义何在?现在你要计算10000个例子中有多少进入了每一个bucket:
现在,你的雇主会问你三个问题:
1.你的预测正确率有几成?
你回答:确切值是(9760+60)除以10000=98.2%
2.你获得正值的例子占多少比例?
你回答:召回比例为60除以100=60%
3.正值预测的百分比多少?
你回答:精确值是60除以200=30%
看一个维基上的精度和召回的优秀范例。
图4.精度和召回
ROC曲线代表了灵敏度(召回)与特异性(不准确)之间的关系,常用来衡量二元分类的性能。然而,在处理高倾斜度的数据集的时候,精度-召回(PR)曲线给出一个更具代表性的表现。见Quora回答:ROC曲线和精度-召回曲线之间的区别是什么?。
Q5.如何证明你对一个算法的改进确实比什么都不做更好?
回答者:Anmol Rajpurohit. .
我们会在追求快速创新中(又名“快速成名”)经常看到,违反科学方法的原则导致误导性的创新,即有吸引力的观点却没有经过严格的验证。一个这样的场景是,对于一个给定的任务:提高算法,产生更好的结果,你可能会有几个关于潜在的改善想法。
人们通常会产生的一个明显冲动是尽快公布这些想法,并要求尽快实施它们。当被问及支持数据,往往是共享的是有限的结果,这是很有可能受到选择偏差的影响(已知或未知)或一个误导性的全局最小值(由于缺乏各种合适的测试数据)。
数据科学家不让自己的情绪操控自己的逻辑推理。但是确切的方法来证明你对一个算法的改进确实比什么都不做更好将取决于实际情况,有几个共同的指导方针:
确保性能比较的测试数据没有选择偏差
确保测试数据足够,以成为各种真实性的数据的代表(有助于避免过拟合)
确保“受控实验”的原则,即在比较运行的原始算法和新算法的表现的时候,性能、测试环境(硬件等)方面必须是完全相同的。
确保结果是可重复的,当接近类似的结果出现的时候
检查结果是否反映局部极大值/极小值或全局极大值/最小值
来实现上述方针的一种常见的方式是通过A/B测试,这里面两个版本的算法是,在随机分割的两者之间不停地运行在类似的环境中的相当长的时间和输入数据。这种方法是特别常见的网络分析方法。
Q6.什么是根本原因分析?
回答者:Gregory Piatetsky
根据维基百科,
根本原因分析(RCA)是一种用于识别错误或问题的根源的解决方法。一个因素如果从problem-fault-sequence的循环中删除后,阻止了最终的不良事件重复出现,则被认为是其根源;而一个因果因素则影响一个事件的结果,但不其是根本原因。
根本原因分析最初用于分析工业事故,但现在广泛应用于其他领域,如医疗、项目管理、软件测试。
这是一个来自明尼苏达州的实用根本原因分析工具包。
本质上,你可以找到问题的根源和原因的关系反复问“为什么”,直到找到问题的根源。这种技术通常被称为“5个为什么”,当时涉及到的问题可能比5个更少或更多。
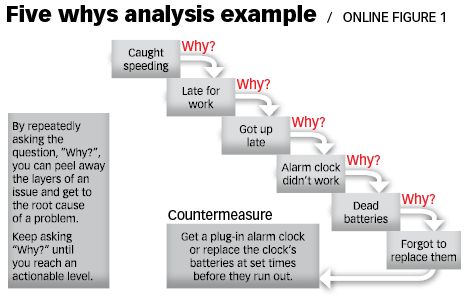
图 5个为什么分析实例,来自《根本原因分析的艺术》
Q7.你是否熟悉价格优化、价格弹性、库存管理、竞争情报?举例说明。
回答者:Gregory Piatetsky
这些问题属于经济学范畴,不会经常用于数据科学家面试,但是值得了解。
价格优化是使用数学工具来确定客户会如何应对不同渠道产品和服务的不同价格。
大数据和数据挖掘使得个性化的价格优化成为可能。现在像亚马逊这样的公司甚至可以进一步优化,对不同的游客根据他们的购买历史显示不同的价格,尽管有强烈的争论这否公平。
通常所说的价格弹性是指
需求的价格弹性,价格敏感性的衡量。它的计算方法是:
需求的价格弹性=需求量变动%÷价格变动%。
同样,供应的价格弹性是一个经济衡量标准,显示了产品或服务的变化如何响应价格变化。
库存管理是一个企业在生产过程中使用的产品的订购、储存和使用的监督和控制,它将销售的产品和销售的成品数量进行监督和控制。
维基百科定义
竞争情报:定义、收集、分析和分发有关产品、客户、竞争对手和所需环境的任何方面的情报,以支持管理人员和管理者为组织做出战略决策的环境。
像Google Trends, Alexa, Compete这样的工具可以用来确定趋势和分析你的竞争对手的网站。
下面是一些有用的资源:
竞争情报的报告指标,by Avinash Kaushik
37款监视你的竞争对手的最好的营销工具from KISSmetrics
来自10位专家的10款最佳竞争情报工具
8.什么是统计检定力?
回答者:Gregory Piatetsky
维基百科定义二元假设检验的统计检定力或灵敏度为测试正确率拒绝零假设的概率(H0)在备择假设(H1)是真的。
换句话说,统计检定力是一种可能性研究,研究将检测到的效果时效果为本。统计能力越高,你就越不可能犯第二类错误(结论是没有效果的,然而事实上有)。
这里有一些工具来计算统计功率。
9.解释什么是重抽样方法和它们为什么有用。并说明它们的局限。
回答者:Gregory Piatetsky
经典的统计参数检验比较理论抽样分布。重采样的数据驱动的,而不是理论驱动的方法,这是基于相同的样本内重复采样。
重采样指的是这样做的方法之一
估计样本统计精度(中位数、方差、百分位数)利用可用数据的子集(折叠)或随机抽取的一组数据点置换(引导)
在进行意义测试时,在数据点上交换标签(置换测试),也叫做精确测试,随机测试,或是再随机测试)
利用随机子集验证模型(引导,交叉验证)
维基百科里关于bootstrapping, jackknifing. 。
见How to Check Hypotheses with Bootstrap and Apache Spark
这里是一个很好的概述重采样统计。
10.有太多假阳性或太多假阴性哪个相比之下更好?说明原因。
回答者:Devendra Desale
这取决于问题本身以及我们正在试图解决的问题领域。
在医学检验中,假阴性可能会给病人和医生提供一个虚假的安慰,表面上看它不存在的时候,它实际上是存在的。这有时会导致不恰当的或不充分的治疗病人和他们的疾病。因此,人们会希望希望有很多假阳性。
对于垃圾邮件过滤,当垃圾邮件过滤或垃圾邮件拦截技术错误地将一个合法的电子邮件信息归类为垃圾邮件,并影响其投递结果时,会出现假阳性。虽然大多数反垃圾邮件策略阻止和过滤垃圾邮件的比例很高,排除没有意义假阳性结果是一个更艰巨的任务。所以,我们更倾向于假阴性而不是假阳性。
11。什么是选择偏差,为什么它是重要的,你如何避免它?
回答者:Matthew Mayo
选择偏差,一般而言,是由于一个非随机群体样本造成的问题。例如,如果一个给定的样本的100个测试案例是一个60 / 20/ 15/ 5的4个类,实际上发生在在群体中相对相等的数字,那么一个给定的模型可能会造成错误的假设,概率可能取决于预测因素。避免非随机样本是处理选择偏差最好的方式,但是这是不切实际的。可以引入技术,如重新采样,和提高权重的策略,以帮助解决问题。
第二部分的答案将于下周发表。